
Kafka中topic的Partition,Kafka為什麼這麼快 Consumer的負載均衡及consumerGrou
阿新 • • 發佈:2018-11-14
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow
也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
1.1. Kafka中topic的Partition
在Kafka檔案儲存中,同一個topic下有多個不同partition,每個partition為一個目錄,partiton命名規則為topic名稱+有序序號,第一個partiton序號從0開始,序號最大值為partitions數量減1。
每個partion(目錄)相當於一個巨型檔案被平均分配到多個大小相等segment(段)資料檔案中。但每個段segment file訊息數量不一定相等,這種特性方便old segment file快速被刪除。預設保留7天的資料。
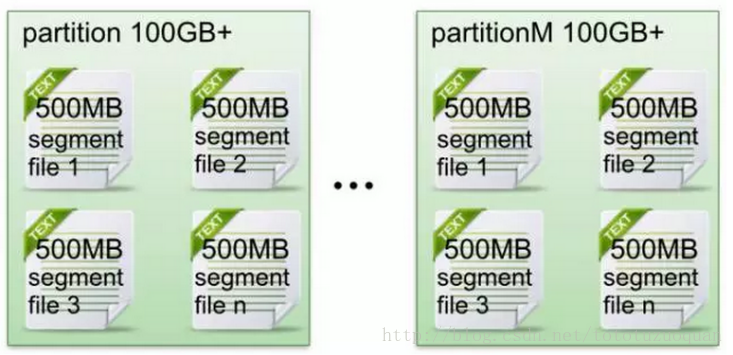
每個partiton只需要支援順序讀寫就行了,segment檔案生命週期由服務端配置引數決定。(什麼時候建立,什麼時候刪除)
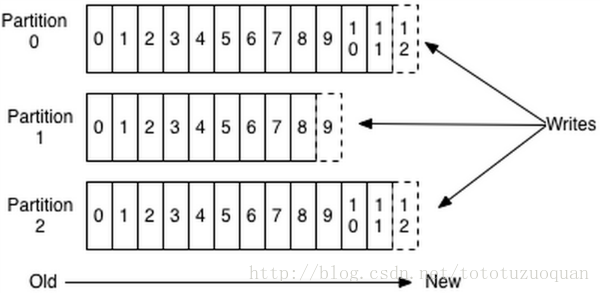
資料有序的討論?
一個partition的資料是否是有序的? 間隔性有序,不連續
針對一個topic裡面的資料,只能做到partition內部有序,不能做到全域性有序。
特別加入消費者的場景後,如何保證消費者消費的資料全域性有序的?偽命題。
只有一種情況下才能保證全域性有序?就是隻有一個partition。
其它:
2.Kafka為什麼這麼快
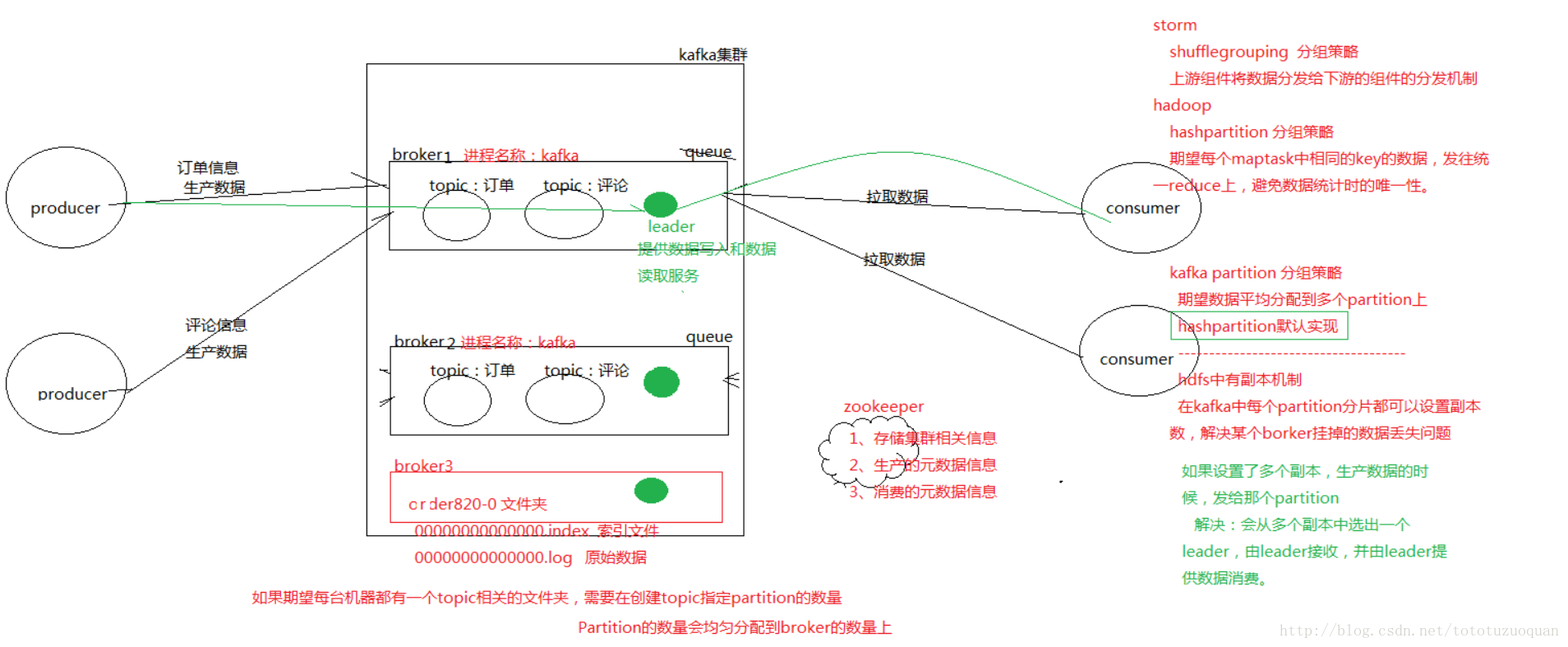
2.1. 首先簡單介紹一下Kafka的架構和涉及到的名詞:
- Topic:用於劃分Message的邏輯概念,一個Topic可以分佈在多個Broker上。
- Partition:是Kafka中橫向擴充套件和一切並行化的基礎,每個Topic都至少被切分為1個Partition。
- Offset:訊息在Partition中的編號,編號順序不跨Partition。
- Consumer:用於從Broker中取出/消費Message。
- Producer:用於往Broker中傳送/生產Message。
- Replication:Kafka支援以Partition為單位對Message進行冗餘備份,每個Partition都可以配置至少1個Replication(當僅1個Replication時即僅該Partition本身)。
- Leader:每個Replication集合中的Partition都會選出一個唯一的Leader,所有的讀寫請求都由Leader處理。其他Replicas從Leader處把資料更新同步到本地,過程類似大家熟悉的MySQL中的Binlog同步。
- Broker:Kafka中使用Broker來接受Producer和Consumer的請求,並把Message持久化到本地磁碟。每個Cluster當中會選舉出一個Broker來擔任Controller,負責處理Partition的Leader選舉,協調Partition遷移等工作。
- ISR(In-Sync Replica):是Replicas的一個子集,表示目前Alive且與Leader能夠“Catch-up”的Replicas集合。由於讀寫都是首先落到Leader上,所以一般來說通過同步機制從Leader上拉取資料的Replica都會和Leader有一些延遲(包括了延遲時間和延遲條數兩個維度),任意一個超過閾值都會把該Replica踢出ISR。每個Partition都有它自己獨立的ISR。
以上幾乎是我們在使用Kafka的過程中可能遇到的所有名詞,同時也無一不是最核心的概念或元件,感覺到從設計本身來說,Kafka還是足夠簡潔的。這次本文圍繞Kafka優異的吞吐效能,逐個介紹一下其設計與實現當中所使用的各項“黑科技”。
Broker
不同於Redis和MemcacheQ等記憶體訊息佇列,Kafka的設計是把所有的Message都要寫入速度低容量大的硬碟,以此來換取更強的儲存能力。實際上,Kafka使用硬碟並沒有帶來過多的效能損失,“規規矩矩”的抄了一條“近道”。
首先,說“規規矩矩”是因為Kafka在磁碟上只做Sequence I/O,由於訊息系統讀寫的特殊性,這並不存在什麼問題。關於磁碟I/O的效能,引用一組Kafka官方給出的測試資料(Raid-5,7200rpm):
Sequence I/O: 600MB/s
Random I/O: 100KB/s
所以通過只做Sequence I/O的限制,規避了磁碟訪問速度低下對效能可能造成的影響。
接下來我們再聊一聊Kafka是如何“抄近道的”。
首先,Kafka重度依賴底層作業系統提供的PageCache功能。當上層有寫操作時,作業系統只是將資料寫入PageCache,同時標記Page屬性為Dirty。當讀操作發生時,先從PageCache中查詢,如果發生缺頁才進行磁碟排程,最終返回需要的資料。實際上PageCache是把儘可能多的空閒記憶體都當做了磁碟快取來使用。同時如果有其他程序申請記憶體,回收PageCache的代價又很小,所以現代的OS都支援PageCache。
使用PageCache功能同時可以避免在JVM內部快取資料,JVM為我們提供了強大的GC能力,同時也引入了一些問題不適用與Kafka的設計。
· 如果在Heap內管理快取,JVM的GC執行緒會頻繁掃描Heap空間,帶來不必要的開銷。如果Heap過大,執行一次Full GC對系統的可用性來說將是極大的挑戰。
· 所有在在JVM內的物件都不免帶有一個Object Overhead(千萬不可小視),記憶體的有效空間利用率會因此降低。
· 所有的In-Process Cache在OS中都有一份同樣的PageCache。所以通過將快取只放在PageCache,可以至少讓可用快取空間翻倍。
· 如果Kafka重啟,所有的In-Process Cache都會失效,而OS管理的PageCache依然可以繼續使用。
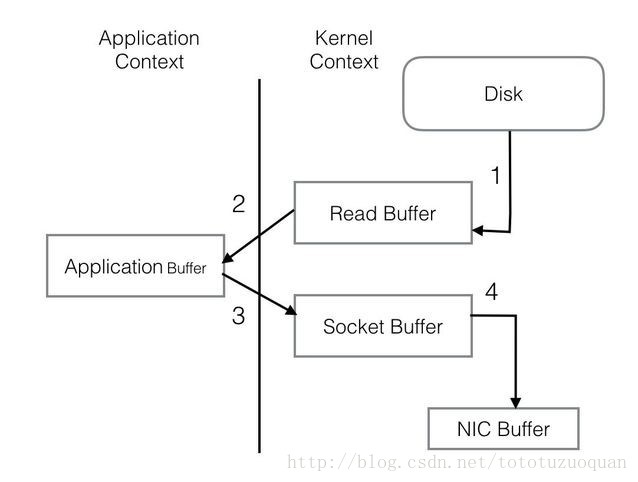
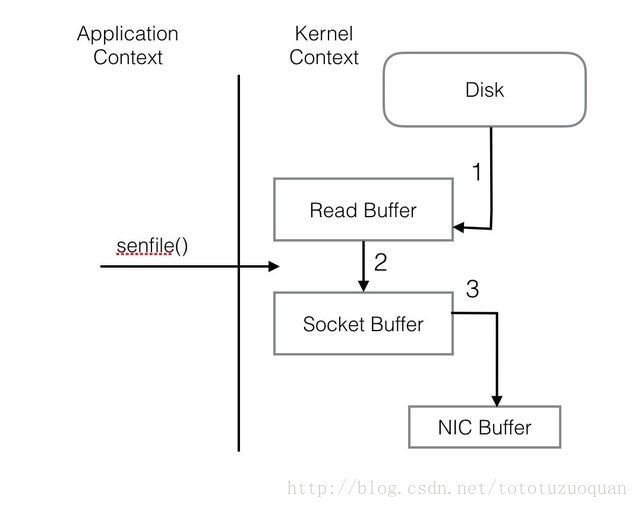
PageCache還只是第一步,Kafka為了進一步的優化效能還採用了Sendfile技術。在解釋Sendfile之前,首先介紹一下傳統的網路I/O操作流程,大體上分為以下4步。 - OS 從硬碟把資料讀到核心區的PageCache。
- 使用者程序把資料從核心區Copy到使用者區。
- 然後使用者程序再把資料寫入到Socket,資料流入核心區的Socket Buffer上。
- OS 再把資料從Buffer中Copy到網絡卡的Buffer上,這樣完成一次傳送。
整個過程共經歷兩次Context Switch,四次System Call。同一份資料在核心Buffer與使用者Buffer之間重複拷貝,效率低下。其中2、3兩步沒有必要,完全可以直接在核心區完成資料拷貝。這也正是Sendfile所解決的問題,經過Sendfile優化後,整個I/O過程就變成了下面這個樣子。
通過以上的介紹不難看出,Kafka的設計初衷是盡一切努力在記憶體中完成資料交換,無論是對外作為一整個訊息系統,或是內部同底層作業系統的互動。如果Producer和Consumer之間生產和
費進度上配合得當,完全可以實現資料交換零I/O。
3.Consumer的負載均衡
當一個group中,有consumer加入或者離開時,會觸發partitions均衡.均衡的最終目的,是提升topic的併發消費能力,步驟如下:
1、 假如topic1,具有如下partitions: P0,P1,P2,P3
2、 加入group中,有如下consumer: C1,C2
3、 首先根據partition索引號對partitions排序: P0,P1,P2,P3
4、 根據consumer.id排序: C0,C1
5、 計算倍數: M = [P0,P1,P2,P3].size / [C0,C1].size,本例值M=2(向上取整)
6、 然後依次分配partitions: C0 = [P0,P1],C1=[P2,P3],即Ci = [P(i * M),P((i + 1) * M -1)] 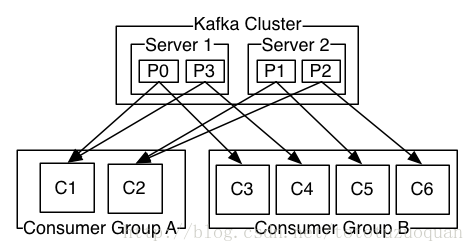
給我老師的人工智慧教程打call!http://blog.csdn.net/jiangjunshow
