
Hadoop的三種排程器
(1)FIFO Scheduler
將所有的Applications放到佇列中,先按照作業的優先順序高低、再按照到達時間的先後,為每個app分配資源。如果第一個app需要的資源被滿足了,如果還剩下了資源並且滿足第二個app需要的資源,那麼就為第二個app分配資源,and so on。
優點:簡單,不需要配置。
缺點:不適合共享叢集。如果有大的app需要很多資源,那麼其他app可能會一直等待。
一個例子
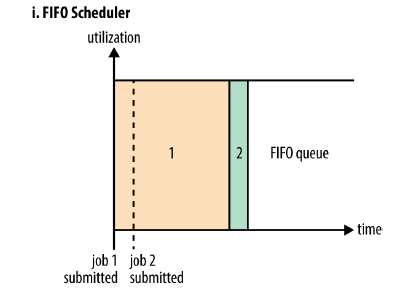
上圖的示例:有一個很大的job1,它先提交,並且佔據了全部的資源。那麼job2提交時發現沒有資源了,則job2必須等待job1執行結束,才能獲得資源執行。
配置
FIFO Scheduler不需要配置
(2)Capacity Scheduler
CapacityScheduler用於一個叢集(叢集被多個組織共享)中執行多個Application的情況,目標是最大化吞吐量和叢集利用率。
CapacityScheduler允許將整個叢集的資源分成多個部分,每個組織使用其中的一部分,即每個組織有一個專門的佇列,每個組織的佇列還可以進一步劃分成層次結構(Hierarchical Queues),從而允許組織內部的不同使用者組的使用。
每個佇列內部,按照FIFO的方式排程Applications。當某個佇列的資源空閒時,可以將它的剩餘資源共享給其他佇列。
if there is more than one job in the queue and there are idle resources available, then the Capacity Scheduler may allocate the spare resources to jobs in the queue, even if that causes the queue’s capacity to be exceeded This behavior is known as queue elasticity.
配置
CapacityScheduler的配置檔案etc/hadoop/capacity-scheduler.xml
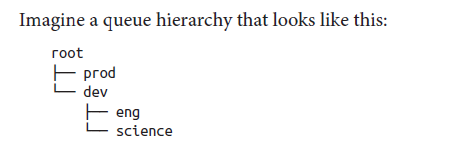

說明:root佇列下面有兩個佇列,分別為prod(40%的容量,即使用40%的叢集資源)和dev(60%的容量,最大的75% -> 說明即使prod佇列空閒了,那麼dev最多隻能使用75%的叢集資源。這樣就可以保證prod中新增新的apps時馬上可以使用25%的資源)。
除了佇列的容量和層次,還可以指定單個使用者或者應用被分配的資源大小、同時可以執行的app數量、佇列的ACLs。
可以指定app要放在哪個佇列中。如果不指定,app將會被放在名字是 default的佇列中。
CapacityScheduler的佇列名字必須是層次結構最後的名字,比如eng。不能是root.dev.eng或者dev.eng。
一個例子

上圖的示例:有一個專門的佇列允許小的apps提交之後能夠儘快執行,注意到job1先提交,先執行時並沒有佔用系統的全部資源(假如job1需要100G記憶體,但是整個叢集只有100G記憶體,那麼只分配給job1 80G),而是保留了一部分的系統資源。
佇列放置
可以再hadoop應用內部指定配置mapreduce.job.queuename來指定要使用的佇列,例如mapreduce.job.eng。如果不指定,則被放入default的佇列。
(3)Fair Scheduler
FairScheduler允許應用在一個叢集中公平地共享資源。預設情況下FairScheduler的公平排程只基於記憶體,也可以配置成基於memory and CPU。當叢集中只有一個app時,它獨佔叢集資源。當有新的app提交時,空閒的資源被新的app使用,這樣最終每個app就會得到大約相同的資源。可以為不同的app設定優先順序,決定每個app佔用的資源百分比。FairScheduler可以讓短的作業在合理的時間內完成,而不必一直等待長作業的完成。
Fair Sharing: Scheduler將apps組織成queues,將資源在這些queues之間公平分配。預設情況下,所有的apps都加入到名字為“default“的佇列中。app也可以指定要加入哪個佇列中。佇列內部的預設排程策略是基於記憶體的共享策略,也可以配置成FIFO和multi-resource with Dominant Resource Fairness
Minimum Sharing:FairScheduller提供公平共享,還允許指定minimum shares to queues,從而保證所有的使用者以及Apps都能得到足夠的資源。如果有的app用不了指定的minimum的資源,那麼可以將超出的資源分給別的app使用。
FairScheduler預設讓所有的apps都執行,但是也可以通過配置檔案小智每個使用者以及每個queue執行的apps的數量。這是針對一個使用者一次提交hundreds of apps產生大量中間結果資料或者大量的context-switching的情況。
一個例子

示例1:大的任務job1提交併執行,佔用了叢集的全部資源,開始執行。之後小的job2執行時,獲得系統一半的資源,開始執行。因此每個job可以公平地使用系統的資源。當job2執行完畢,並且叢集中沒有其他的job加入時,job1又可以獲得全部的資源繼續執行。
注意:job2提交之後並不能馬上就獲取到叢集一半的資源,因為job2必須等待job1釋放containers。
一個例子
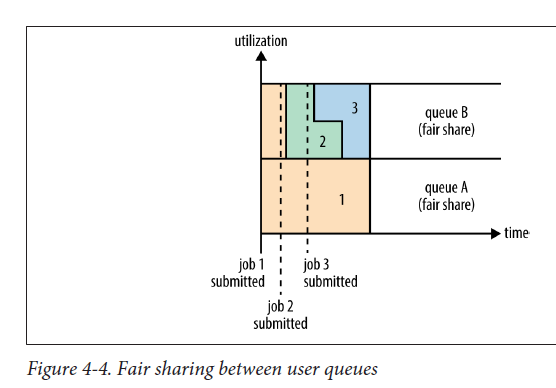
示例2:兩個使用者A和B。A提交job1時叢集內沒有正在執行的app,因此job1獨佔叢集中的資源。使用者B的job2提交時,job2在job1釋放一半的containers之後,開始執行。job2還沒執行完的時候,使用者B提交了job3,job2釋放它佔用的一半containers之後,job3獲得資源開始執行。
配置:
(1)修改yarn-site.xml,開啟fair排程器
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
(2)新增fair-scheduler.xml
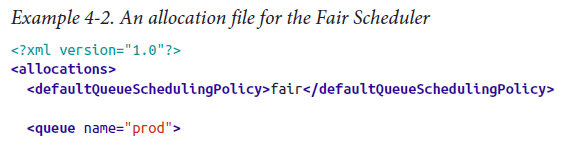

使用FairScheduler需要在fair-scheduler.xml中列出存在的佇列和各自的 weights and capacities
prod和dev的權重也可以設定成2和3。
dev下的兩個sub-queue沒有指定權重,則為1:1。
在設定權重時,需要考慮default queue和使用者命名的queue的權重,這些沒有在xml檔案中指定,但是它們的權重都是1.
佇列還可以被配置minimum maximum Resources以及可以執行的最大的apps的數量
FairScheduler支援preemption(搶佔),當queue佔用的資源大於它應得的,那麼排程器可以殺掉queue對應的containers,將yarn.scheduler.fair.preemption設定成true即可。
佇列放置
可以再hadoop應用內部指定配置mapreduce.job.queuename來指定要使用的佇列,例如mapreduce.job.eng。如果不指定,則按規則來匹配佇列,例如:

FairScheduler和CapacityScheduler的異同
相同:
(1)以佇列劃分資源
(2)設定最低保證和最大使用上限
(3)在某個佇列空閒時可以將資源共享給其他佇列。
不同:
(1)Fair Scheduler佇列內部支援多種排程策略,包括FIFO、Fair(佇列中的N個作業,每個獲得該佇列1 / N的資源)、DRF(Dominant Resource Fairness)(多種資源型別e.g. CPU,記憶體 的公平資源分配策略)
(2)Fair Scheduler支援資源搶佔。當佇列中有新的應用提交時,系統排程器理應為它回收資源,但是考慮到共享的資源正在進行計算,所以排程器採用先等待再強制回收的策略,即等待一段時間後入股仍沒有獲得資源,那麼從使用共享資源的佇列中殺死一部分任務,通過yarn.scheduler.fair.preemption設定為true,開啟搶佔功能。
(3)Fair Scheduler中有一個基於任務數量的負載均衡機制,該機制儘可能將系統中的任務分配到各個節點
(4)Fair Scheduler可以為每個佇列單獨設定排程策略(FIFO Fair DRF)
(5)Fair Scheduler由於可以採用Fair演算法,因此可以使得小應用快速獲得資源,避免了餓死的情況。
Hierarchical queues with pluggable policies
FairScheduler支援層次佇列(hierarchical queues),所有佇列都從root佇列開始,root佇列的孩子佇列公平地共享可用的資源。孩子佇列再把可用資源公平地分配給他們的孩子佇列。apps可能只會在葉子佇列被排程。此外,使用者可以為每個佇列設定不同的共享資源的策略,內建的佇列策略包括 FifoPolicy, FairSharePolicy (default), and DominantResourceFairnessPolicy。
使用者可以通過繼承org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.SchedulingPolicy實現自己定義的策略。
(4)Delay Scheduling&Dominant Resource Fairness
CapacityScheduler和FairScheduler都支援Delay Scheduling和DRF
不同的apps對CPU和記憶體的需求量不一樣,有的可能需要大量的CPU和一點點記憶體,有的可能正相反。這會使排程變得複雜。YARN解決的方法是Dominant Resource Fairness,即看app主要需要的資源是什麼,用它作為該app對叢集使用的度量。
參考:
(1)《Hadoop The Definitive Guide 4th》
(2)官方文件
http://hadoop.apache.org/docs/r2.7.2/hadoop-yarn/hadoop-yarn-site/CapacityScheduler.html
http://hadoop.apache.org/docs/r2.7.2/hadoop-yarn/hadoop-yarn-site/FairScheduler.html