
Python爬蟲實踐 -- 記錄我的第二隻爬蟲
1、爬蟲基本原理
我們爬取中國電影最受歡迎的影片《紅海行動》的相關資訊。其實,爬蟲獲取網頁資訊和人工獲取資訊,原理基本是一致的。

人工操作步驟:
1. 獲取電影資訊的頁面
2. 定位(找到)到評分資訊的位置
3. 複製、儲存我們想要的評分資料
爬蟲操作步驟:
1. 請求並下載電影頁面資訊
2. 解析並定位評分資訊
3. 儲存評分資料
綜合言之,原理圖如下:
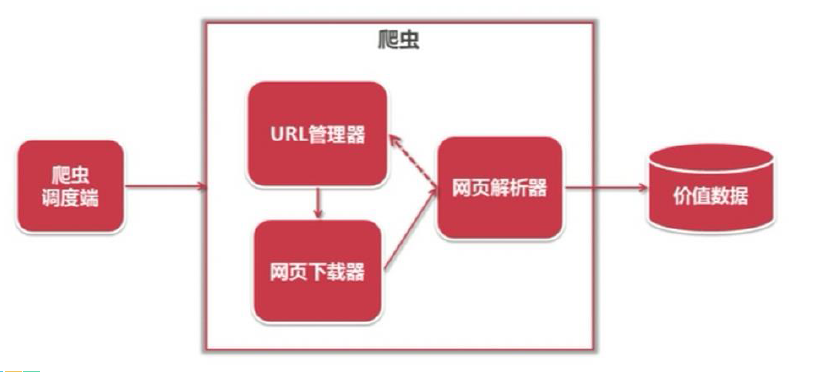
2、爬蟲的基本流程
簡單來說,我們向伺服器傳送請求後,會得到返回的頁面;通過解析頁面之後,我們可以抽取我們想要的那部分資訊,並存儲在指定的文件或資料庫中。這樣,我們想要的資訊就被我們“爬”下來啦~

3、安裝python依賴包 Requests+Xpath
Python 中爬蟲相關的包很多:Urllib、requsts、bs4……我們從簡單 requests+xpath 上手!更高階的 BeautifulSoup 還是有點難的。
然後我們安裝 requests+xpath 的應用包以爬取豆瓣電影:
在Windows 終端分別輸入以下兩行程式碼:
pip install requestspip install lxml
4、程式碼整理--獲取豆瓣電影目標網頁並解析
我們要爬取豆瓣電影《紅海行動》相關資訊,目標地址是:https://movie.douban.com/subject/26861685/
給定 url 並用 requests.get() 方法來獲取頁面的text,用 etree.HTML() 來解析下載的頁面資料“data”。
1 url = 'https://movie.douban.com/subject/26861685/'
2 data = requests.get(url).text
3 s=etree.HTML(data)
5、獲取電影名稱
獲取元素的Xpath資訊並獲得文字:
1 file=s.xpath('元素的Xpath資訊/text()')
這裡的“元素的Xpath資訊”是需要我們手動獲取的,獲取方式為:定位目標元素,在網站上依次點選:右鍵 > 檢查
快捷鍵“shift+ctrl+c”,移動滑鼠到對應的元素時即可看到對應網頁程式碼:
在電影標題對應的程式碼上依次點選 右鍵 > Copy > Copy XPath,獲取電影名稱的Xpath:
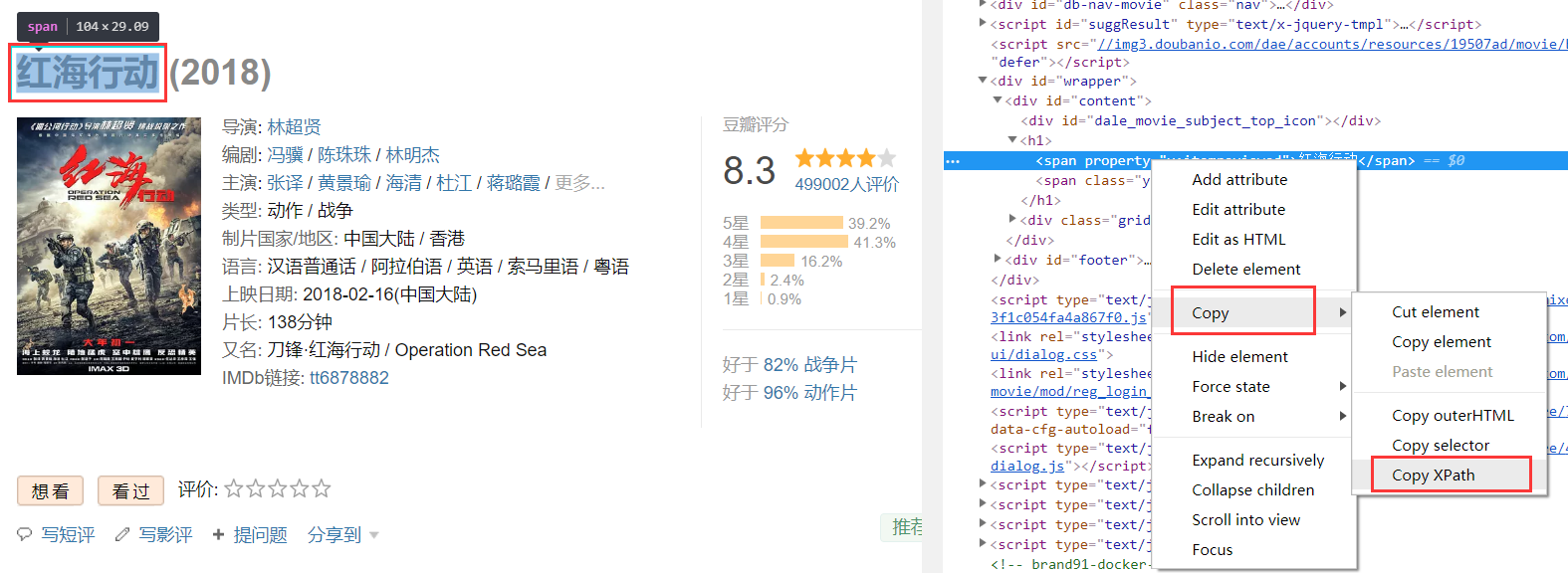
這樣我們就把元素中的Xpath資訊複製下來了:
//*[@id="content"]/h1/span[1]
放到程式碼中並列印資訊:
film=s.xpath('//*[@id="content"]/h1/span[1]/text()')
print(film)6、 程式碼以及執行結果
以上完整程式碼如下:
import requests from lxml
import etree url = 'https://movie.douban.com/subject/26861685/'
data = requests.get(url).text
s=etree.HTML(data)
film=s.xpath('//*[@id="content"]/h1/span[1]/text()') print(film)
在 Pycharm 中執行完整程式碼及結果如下:

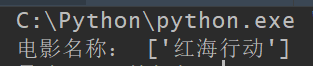
至此,我們完成了爬取豆瓣電影《紅海行動》中“電影名稱”資訊的程式碼編寫,可以在 Pycharm 中執行。
7、 獲取其它元素資訊
除了電影的名字,我們還可以獲取導演、主演、電影片長等資訊,獲取的方式是類似的。程式碼如下:
director=s.xpath('//*[@id="info"]/span[1]/span[2]/a/text()') #導演
actor1=s.xpath('//*[@id="info"]/span[3]/span[2]/span[1]/a/text()') #主演1
actor2=s.xpath('//*[@id="info"]/span[3]/span[2]/span[2]/a/text()') #主演2
actor3=s.xpath('//*[@id="info"]/span[3]/span[2]/span[3]/a/text()') #主演3
time=s.xpath(‘//*[@id="info"]/span[12]/text()') #電影片長
觀察上面的程式碼,發現獲取不同“主演”資訊時,區別只在於“span[x]”中“x”的數字大小不同。實際上,要一次性獲取所有“主演”的資訊時,用不加數字的“a”表示即可。程式碼如下:
actor=s.xpath('//*[@id="info"]/span[3]/span[2]/a/text()') #主演完整程式碼如下:
import requests
from lxml import etree
url = 'https://movie.douban.com/subject/26861685/'
data = requests.get(url).text
s=etree.HTML(data)
film=s.xpath('//*[@id="content"]/h1/span[1]/text()') #導演
director=s.xpath('//*[@id="info"]/span[1]/span[2]/a/text()') #導演
actor=s.xpath('//*[@id="info"]/span[3]/span[2]/a/text()') #主演
time=s.xpath('//*[@id="info"]/span[12]/text()') #電影片長
print('電影名稱:',film)
print('導演:',director)
print('主演:',actor)
print('片長:',time)
在 Pycharm 中執行完整程式碼結果如下:

8、 關於解析神器 Xpath
Xpath 即為 XML 路徑語言(XML Path Language),它是一種用來確定 XML 文件中某部分位置的語言。
Xpath 基於 XML 的樹狀結構,提供在資料結構樹中找尋節點的能力。起初 Xpath 的提出的初衷是將其作為一個通用的、介於 Xpointer 與 XSL 間的語法模型。但是Xpath 很快的被開發者採用來當作小型查詢語言。
可以閱讀該文件瞭解更多關於 Xpath 的知識。
Xpath解析網頁的流程:
1.首先通過Requests庫獲取網頁資料
2.通過網頁解析,得到想要的資料或者新的連結
3.網頁解析可以通過 Xpath 或者其它解析工具進行,Xpath 在是一個非常好用的網頁解析工具

常見的網頁解析方法比較

- 正則表示式使用比較困難,學習成本較高
- BeautifulSoup 效能較慢,相對於 Xpath 較難,在某些特定場景下有用
- Xpath 使用簡單,速度快(Xpath是lxml裡面的一種),是入門最好的選擇