
基於Kafka構建事件溯源模式的微服務
本文中我們將討論如何借助Kafka實現分布式消息管理,使用事件溯源(Event Sourcing)模式實現原子化數據處理,使用CQRS模式(Command-Query Responsibility Segregation )實現查詢職責分離,使用消費者群組解決單點故障問題,理解分布式協調框架Zookeeper的運行機制。整個應用的代碼實現使用Go語言描述。
第一部分 引子、環境準備、整體設計及實現
第二部分 消息消費者及其集群化
第三部分 測試驅動開發、Docker部署和持續集成
第一部分 引子、環境準備、整體設計及實現
為什麽需要微服務
微服務本身並不算什麽新概念,它要解決的問題在軟件工程歷史中早已經有人提出:解耦、擴展性、靈活性,解決“爛架構”膨脹後帶來的復雜度問題。
Conway‘s law(康威定律)
Any organization that designs a system (defined broadly) will produce a design whose structure is a copy of the organization‘s communication structure.(任何組織在設計一套系統(廣義概念上的系統)時,所交付的設計方案在結構上都與該組織的通信結構保持一致)
-- Melvyn Conway, 1967
基於Kafka構建事件溯源模式的微服務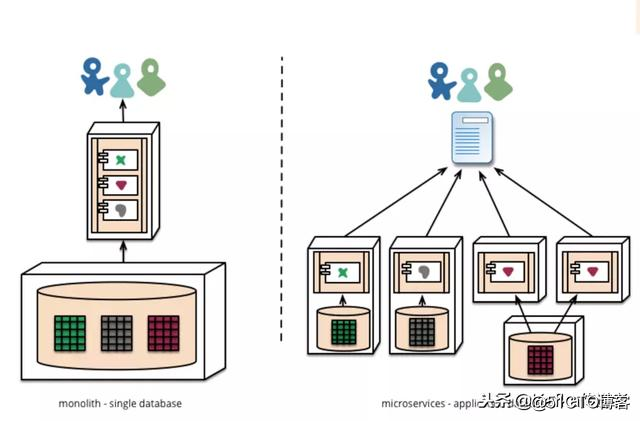
為了趕進度加程序員就像用水去滅油鍋裏的火一樣,原因在於:溝通成本 = n(n-1)/2,溝通成本隨著項目或者組織的人員增加呈指數級增長。很多項目在經過一段時間的發展之後,都會有不少恐龍級代碼,無人敢挑戰。比如一個類的規模就多達數千行,核心方法近千行,大量重復代碼,每次調整都以失敗告終。龐大的系統規模導致團隊新成員接手困難,項目組人員增加導致的代碼沖突問題,系統復雜度的增加導致的不確定上線風險、引入新技術困難等。
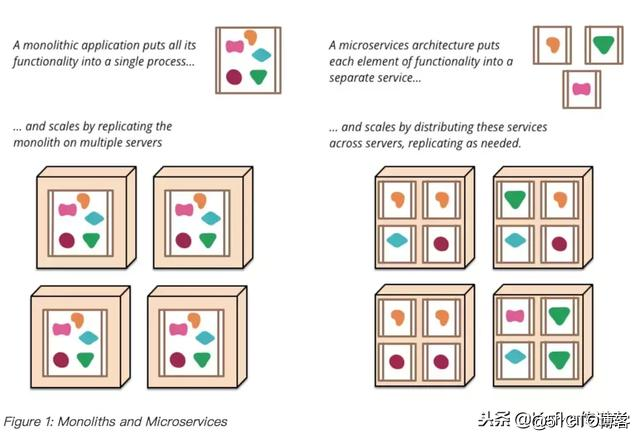
微服務 (Microservices)是解決這些困難的眾多方案之一。它本質上是一種軟件架構風格,它是以專註於單一責任與功能的小型功能區塊 (Small Building Blocks) 為基礎,利用模組化的方式組合出復雜的大型應用程序,各功能區塊使用與語言無關 (Language-Independent/Language agnostic) 的 API 集相互通訊。
Event Sourcing(事件溯源)
真正構建一個微服務是非常具有挑戰性的。其中一個最重要的挑戰就是原子化————如何處理分布式數據,如何設計服務的粒度。例如,常見的客戶、工單場景,如果拆分成兩個服務,查詢都變成了一個難題:
select * from order o, customer c where o.customer_id = c.id and o.gross_amount > 50000 and o.status = ‘PAID‘ and c.country = ‘INDONESIA‘;
在DDD領域(Domain-Driven Design,領域驅動設計)有一種架構風格被廣泛應用,即CQRS (Command Query Responsibility Seperation,命令查詢職責分離)。CQRS最核心的概念是Command、Event,“將數據(Data)看做是事實(Fact)。每個事實都是過去的痕跡,雖然這種過去可以遺忘,但卻無法改變。” 這一思想直接發展了Event Source,即將這些事件的發生過程記錄下來,使得我們可以追溯業務流程。CQRS對設計者的影響,是將領域邏輯,尤其是業務流程,皆看做是一種領域對象狀態遷移的過程。這一點與REST將HTTP應用協議看做是應用狀態遷移的引擎,有著異曲同工之妙。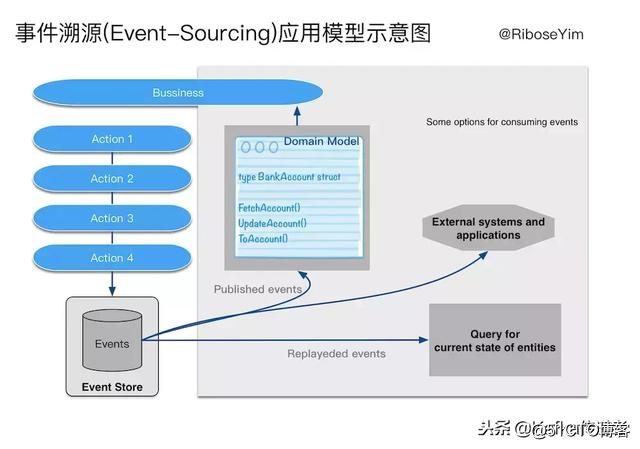
實現方案
Kafka in a Nutshell
Apache Kafka是由Apache軟件基金會開發的一個開源消息中間件項目,由Scala寫成。Kafka最初是由LinkedIn開發,並於2011年初開源。2012年10月從Apache Incubator畢業。該項目的目標是為處理實時數據提供一個統一、高吞吐、低延遲的平臺。Kafka使用Zookeeper作為其分布式協調框架,很好的將消息生產、消息存儲、消息消費的過程結合在一起。同時借助Zookeeper,kafka能夠生產者、消費者和broker在內的所以組件在無狀態的情況下,建立起生產者和消費者的訂閱關系,並實現生產者與消費者的負載均衡。
Kafka Core Words
Broker:Kafka集群包含一個或多個服務器,這種服務器被稱為broker
Topic:每條發布到Kafka集群的消息都有一個類別,這個類別被稱為Topic。Topic相當於數據庫中的Table,行數據以log的形式存儲,非常類似Git中commit log。物理上不同Topic的消息分開存儲,邏輯上一個Topic的消息雖然保存於一個或多個broker上但用戶只需指定消息的Topic即可生產或消費數據而不必關心數據存於何處。
Partition:Parition是物理上的概念,每個Topic包含一個或多個Partition.
Producer:消息生產者,負責發布消息到Kafka broker
Consumer:消息消費者,向Kafka broker讀取消息的客戶端。
Consumer Group:每個Consumer屬於一個特定的Consumer Group(可為每個Consumer指定group name,若不指定則屬於默認的group)。
整體設計
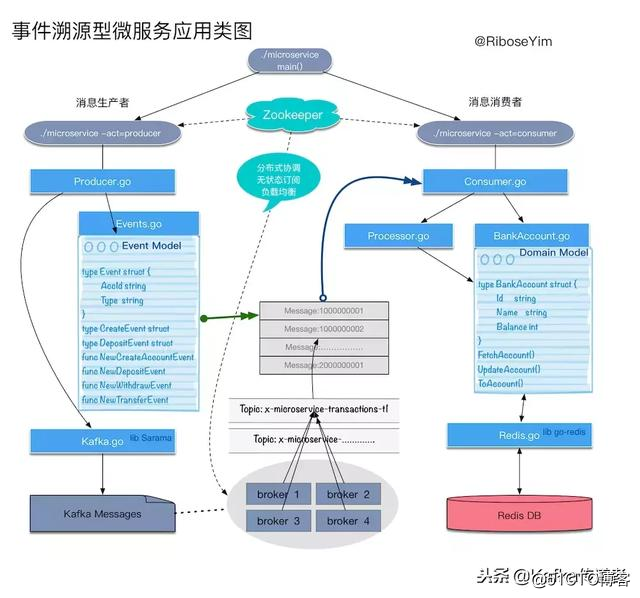
案例:假設一個銀行賬戶系統。經過一段時間的經營發展,該行客戶數量和交易規模都有了巨大的增長,系統內部變得異常復雜,每一個部分都變得沈重不堪。我們嘗試對他的業務單元進行解耦,例如將余額計算邏輯從原有的核心系統拆分出來。根據銀行賬戶業務特點,我們設計一個生產者——負責根據業務事件觸發生成一個事件,所有事件基於Kafka存儲,再設計一個消費者——負責從Kafka抓去未處理事件,通過調用業務邏輯處理單元完成後續持久化操作。這樣一個賬戶的所有業務操作都可以有完整的快照歷史,符合金融業務Audit(審計)的需要。而且通過使用事件,我們可以很方便地重建數據。
業務事件列表:
CreateEvent:開戶
DepositEvent:存款
WithdrawEvent:取款
TransferEvent:轉賬
領域模型:賬戶(Account)
holder‘s name:持有人名稱
balance:余額
registration date:開戶日期
......
領域模型:事件(Event)
name:事件名稱
ID:序號
......
環境準備
第一步,啟動ZooKeeper:
$ wget http://mirror.bit.edu.cn/apache/kafka/0.10.1.0/kafka_2.10-0.10.1.0.tgz
$ tar -xvf kafka_2.10-0.10.1.0.tgz
$ cd kafka_2.10-0.10.1.0
$ bin/zookeeper-server-start.sh config/zookeeper.properties
$ netstat -an | grep 2181
tcp46 0 0 *.2181 *.* LISTEN 第二步,啟動Kafka
$ bin/kafka-server-start.sh config/server.properties
[2017-06-13 14:03:08,168] INFO New leader is 0 (kafka.server.ZookeeperLeaderElector$LeaderChangeListener)
[2017-06-13 14:03:08,172] INFO Kafka version : 0.10.1.0 (org.apache.kafka.common.utils.AppInfoParser)
[2017-06-13 14:03:08,172] INFO Kafka commitId : 3402a74efb23d1d4 (org.apache.kafka.common.utils.AppInfoParser)
[2017-06-13 14:03:08,173] INFO [Kafka Server 0], started (kafka.server.KafkaServer)
$ lsof -nP -iTCP -sTCP:LISTEN | sort -n
$ netstat -an | grep 9092
tcp46 0 0 *.9092 *.* LISTEN第三步,創建topic
$ bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partition 1 --topic x-microservice-transactions-t1
Created topic "x-microservice-transactions-t1".另外,運行多個Kafka 實例
Kafka多實例非常簡單,只需要復制文件 server.properties,稍作修改即可。
config/server-1.properties:
broker.id=1
listeners=PLAINTEXT://:9093
log.dir=/tmp/kafka-logs-1
config/server-2.properties:
broker.id=2
listeners=PLAINTEXT://:9094
log.dir=/tmp/kafka-logs-2
// 啟動多個broker,須指定不同的屬性文件
$ bin/kafka-server-start.sh config/server-1.properties
$ bin/kafka-server-start.sh config/server-2.propertiesdomain model
package main
// domain model: bank_account.go
type BankAccount struct {
Id string
Name string
Balance int
}
//定義下列函數:
//1. FetchAccount(id) 從Redis讀取賬戶實例信息
//2. updateAccount(id, data) 更新指定賬戶信息
//3. ToAccount(map) 將從Redis讀到的賬戶信息轉換為模型數據,return *BankAccount object.Kafka & Redis library
// main.go
import (
"github.com/go-redis/redis" // Redis通訊庫:go-redis
)
var (
Redis = initRedis()
)
func initRedis() *redis.Client {
redisUrl := os.Getenv("REDIS_URL")
if redisUrl == "" {
redisUrl = "127.0.0.1:6379"
}
return redis.NewClient(&redis.Options{
Addr: redisUrl,
Password: "",
DB: 0,
})
}
package main
//kafka.go
import (
"encoding/json"
"fmt"
"github.com/Shopify/sarama" //Kafka通訊庫:Sarama
"os"
)
var (
brokers = []string{"127.0.0.1:9092"}
topic = "go-microservice-transactions"
topics = []string{topic}
)
func newKafkaConfiguration() *sarama.Config {
conf := sarama.NewConfig()
conf.Producer.RequiredAcks = sarama.WaitForAll
conf.Producer.Return.Successes = true
conf.ChannelBufferSize = 1
conf.Version = sarama.V0_10_1_0
return conf
}
func newKafkaSyncProducer() sarama.SyncProducer {
kafka, err := sarama.NewSyncProducer(brokers, newKafkaConfiguration())
if err != nil {
fmt.Printf("Kafka error: %s
", err)
os.Exit(-1)
}
return kafka
}
func newKafkaConsumer() sarama.Consumer {
consumer, err := sarama.NewConsumer(brokers, newKafkaConfiguration())
if err != nil {
fmt.Printf("Kafka error: %s
", err)
os.Exit(-1)
}
return consumer
}消息生產者Producer
package main
//消息生產者 producer.go
import (
"bufio"
"fmt"
"os"
"strconv"
"strings"
)
func mainProducer() {
var err error
reader := bufio.NewReader(os.Stdin)
kafka := newKafkaSyncProducer()
for {
fmt.Print("-> ")
text, _ := reader.ReadString(‘
‘)
text = strings.Replace(text, "
", "", -1)
args := strings.Split(text, "###")
cmd := args[0]
switch cmd {
case "create":
if len(args) == 2 {
accName := args[1]
event := NewCreateAccountEvent(accName)
sendMsg(kafka, event)
} else {
fmt.Println("Only specify create###Account Name")
}
default:
fmt.Printf("Unknown command %s, only: create, deposit, withdraw, transfer
", cmd)
}
if err != nil {
fmt.Printf("Error: %s
", err)
err = nil
}
}
}
// kafka.go
// 增加發送消息的方法
func sendMsg(kafka sarama.SyncProducer, event interface{}) error {
json, err := json.Marshal(event)
if err != nil {
return err
}
msgLog := &sarama.ProducerMessage{
Topic: topic,
Value: sarama.StringEncoder(string(json)),
}
partition, offset, err := kafka.SendMessage(msgLog)
if err != nil {
fmt.Printf("Kafka error: %s
", err)
}
fmt.Printf("Message: %+v
", event)
fmt.Printf("Message is stored in partition %d, offset %d
",
partition, offset)
return nil
}
package main
//啟動入口,main.go
func main() {
mainProducer()
}
$ go build
$ ./go-microservice
-> create
Only specify create###Account Name
-> create###Yanrui
Message: {Event:{AccId:49a23d27-4ffe-4c86-ab9a-fbc308ecff1c Type:CreateEvent} AccName:Yanrui}
Message is stored in partition 0, offset 0
->第二部分 消息消費者Consumer及其集群化
Consumer負責從Kafka加載消息隊列。另外,我們需要為每一個事件創建process()函數。
package main
//processor.go
import (
"errors"
)
func (e CreateEvent) Process() (*BankAccount, error) {
return updateAccount(e.AccId, map[string]interface{}{
"Id": e.AccId,
"Name": e.AccName,
"Balance": "0",
})
}
func (e InvalidEvent) Process() error {
return nil
}
func (e AcceptEvent) Process() error {
return nil
}
// other Process() codes ...
package main
//consumer.go
func mainConsumer(partition int32) {
kafka := newKafkaConsumer()
defer kafka.Close()
//註:開發環境中我們使用sarama.OffsetOldest,Kafka將從創建以來第一條消息開始發送。
//在生產環境中切換為sarama.OffsetNewest,只會將最新生成的消息發送給我們。
consumer, err := kafka.ConsumePartition(topic, partition, sarama.OffsetOldest)
if err != nil {
fmt.Printf("Kafka error: %s
", err)
os.Exit(-1)
}
go consumeEvents(consumer)
fmt.Println("Press [enter] to exit consumer
")
bufio.NewReader(os.Stdin).ReadString(‘
‘)
fmt.Println("Terminating...")
}Go語言通過goroutine提供了對於並發編程的直接支持,goroutine是Go語言運行庫的功能,作為一個函數入口,在堆上為其分配的一個堆棧。所以它非常廉價,我們可以很輕松的創建上萬個goroutine,但它們並不是被操作系統所調度執行。除了被系統調用阻塞的線程外,Go運行庫最多會啟動$GOMAXPROCS個線程來運行goroutine。
goroutines: A goroutine is a lightweight thread of execution.
channels: Channels are the pipes that connect concurrent goroutines. (<- operator)
for: for is Go’s only looping construct. Here are three basic types of for loops.
select: Go’s select lets you wait on multiple channel operations.
Non-Blocking Channel Operations
func consumeEvents(consumer sarama.PartitionConsumer) {
var msgVal []byte
var log interface{}
var logMap map[string]interface{}
var bankAccount *BankAccount
var err error
for {
//goruntine exec
select {
// blocking <- channel operator
case err := <-consumer.Errors():
fmt.Printf("Kafka error: %s
", err)
case msg := <-consumer.Messages():
msgVal = msg.Value
//
if err = json.Unmarshal(msgVal, &log); err != nil {
fmt.Printf("Failed parsing: %s", err)
} else {
logMap = log.(map[string]interface{})
logType := logMap["Type"]
fmt.Printf("Processing %s:
%s
", logMap["Type"], string(msgVal))
switch logType {
case "CreateEvent":
event := new(CreateEvent)
if err = json.Unmarshal(msgVal, &event); err == nil {
bankAccount, err = event.Process()
}
default:
fmt.Println("Unknown command: ", logType)
}
if err != nil {
fmt.Printf("Error processing: %s
", err)
} else {
fmt.Printf("%+v
", *bankAccount)
}
}
}
}
} 重構main
package main
//main.go
//支持producer和consumer啟動模式
import (
"flag"
...
)
func main() {
act := flag.String("act", "producer", "Either: producer or consumer")
partition := flag.String("partition", "0",
"Partition which the consumer program will be subscribing")
flag.Parse()
fmt.Printf("Welcome to go-microservice : %s
", *act)
switch *act {
case "producer":
mainProducer()
case "consumer":
if part32int, err := strconv.ParseInt(*partition, 10, 32); err == nil {
mainConsumer(int32(part32int))
}
}
}通過--act參數,可以啟動一個消費者進程。當進程運行時,他將從Kafka一個一個拿出消息進行處理,按照我們之前在每個事件定義的Process() 方法。
$ go build
$ ./go-microservice --act=consumer
Welcome to go-microservice : consumer
Press [enter] to exit consumer
Processing CreateEvent:
{"AccId":"49a23d27-4ffe-4c86-ab9a-fbc308ecff1c","Type":"CreateEvent","AccName":"Yanrui"}
{Id:49a23d27-4ffe-4c86-ab9a-fbc308ecff1c Name:Yanrui Balance:0}
Terminating...集群化消息消費者
問題:如果一個Consumer宕機了怎麽辦?(例如:程序崩潰、網絡異常等原因)
解決方案:將多個Consumer編組為集群實現高可用。具體來說就是打標簽,當有一個新的Log發送時,Kafka將其發送給其中一個實例。當該實例無法接收Log時,Kafka將Log傳遞給另一個包含相同標簽的Consumer。
註意:Kafka 版本 0.9 +,另外還需要使用sarama-cluster庫
#使用govendor獲取
govendor fetch github.com/bsm/sarama-cluster
//修改mainConsumer方法使用sarama-cluster library連接Kafka
config := cluster.NewConfig()
config.Consumer.Offsets.Initial = sarama.OffsetNewest
consumer, err := cluster.NewConsumer(brokers, "go-microservice-consumer", topics, config)
//topics定義
var (
topics = []string{topic}
)
//調整consumeEvents()
case err, more := <-consumer.Errors():
if more {
fmt.Printf("Kafka error: %s
", err)
}
//consumer.Messages() : MarkOffset
//consumer.go
//func mainConsumer(partition int32)
consumer.MarkOffset(msg, "") //增加的行
msgVal = msg.Value即使程序崩潰,MarkOffset也會將消息標記為 processed ,標簽包括元數據以及這個時間點的狀態。元數據可以被另外一個Consumer恢復數據狀態,也就能被重新消費。即即使同樣的消息被處理兩次,結果也是一樣的,這個過程理論上是 冪等 的(idempotent)。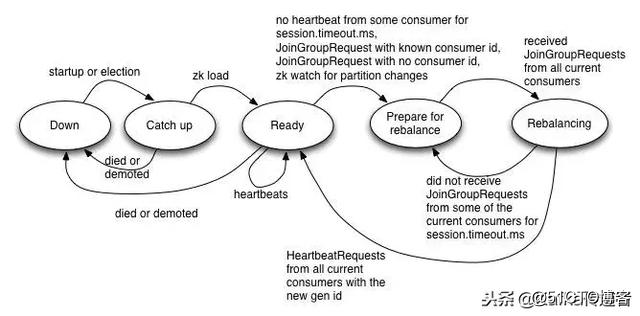
Kafka Consumers
//運行多個consumer實例
$ ./go-microservice --act=consumer
$ ./go-microservice --act=consumer
$ ./go-microservice --act=consumer第三部分:測試驅動開發、Docker部署和持續集成
使用vendor管理Golang項目依賴
用govendor fetch <url1> <url2>新增的第三方包直接被get到根目錄的vendor文件夾下,不會與其它的項目混用第三方包,完美避免多個項目同用同一個第三方包的不同版本問題。只需要對vendor/vendor.json進行版本控制,即可對第三包依賴關系進行控制。
$ //
$ go get -u github.com/kardianos/govendor
$ cd $PROJECT_PATH
$ govendor init
$ govendor add +external
$單元測試:ginkgo Test Suite
ginkgo
gomega
$ go get github.com/onsi/ginkgo/ginkgo
$ go get github.com/onsi/gomega
$ ginkgo bootstrap
Generating ginkgo test suite bootstrap for main in:
go_microservice_suite_test.go
package main_test
//go_microservice_suite_test.go,單元測試類
import (
"github.com/onsi/ginkgo"
"github.com/onsi/gomega"
)
var _ = Describe("Event", func() {
Describe("NewCreateAccountEvent", func() {
It("can create a create account event", func() {
name := "John Smith"
event := NewCreateAccountEvent(name)
Expect(event.AccName).To(Equal(name))
Expect(event.AccId).NotTo(BeNil())
Expect(event.Type).To(Equal("CreateEvent"))
})
})
})
$ ginkgo
Running Suite: go-microservice Suite
==========================
Random Seed: 1490709758
Will run 1 of 1 specs
Ran 1 of 1 Specs in 0.000 seconds
SUCCESS! -- 1 Passed | 0 Failed | 0 Pending | 0 Skipped PASS
Ginkgo ran 1 suite in 905.68195ms
Test Suite Passed單元測試的四個階段
Setup 啟動
Execution 執行
Verification 驗證
Teardown 拆卸
Docker部署
Docker 容器中需要包含下列組件:
Golang
Redis、Kafka
微服務依賴的其它組件
在根目錄創建一個Dockerfile
FROM golang:1.8.0
MAINTAINER Yanrui
//install our dependencies
RUN go get -u github.com/kardianos/govendor
RUN go get github.com/onsi/ginkgo/ginkgo
RUN go get github.com/onsi/gomega
//將整個目錄拷貝到容器
ADD . /go/src/go-microservice
//檢查工作目錄
WORKDIR /go/src/go-microservice
//安裝依賴項
RUN govendor sync
//測試
$ docker build -t go-microservice .
$ docker run -i -t go-microservice /bin/bash
$ ginkgo
.......................
.......Failed..........由於容器本地並沒有一個Redis實例運行在上面,這時運行ginkgo測試就會報錯。我們為什麽不在這個Dockerfile中包含一個Redis呢?這就違背了Docker分層解耦的初衷,我們可以通過docker-compose將兩個服務連接起來一起工作。
創建一個docker-compose.yml文件(與Dockerfile目錄一致):
version: "2.0"
services:
app:
environment:
REDIS_URL: redis:6379
build: .
working_dir: /go/src/go-microservice
links:
- redis
redis:
image: redis:alpine本地構建完成之後,再次運行 docker-compose run app ginkgo 測試通過。
Infrastructure as Code(基礎設施即代碼)
The enabling idea of infrastructure as code is that the systems and devices which are used to run software can be treated as if they, themselves, are software. — Kief Morris
雲帶來的好的一方面是它讓公司中的任何人都可以輕松部署、配置和管理他們需要的基礎設施。雖然很多基礎設施團隊采用了雲和自動化技術,卻沒有采用相應的自動化測試和發布流程。它們把這些當作一門過於復雜的腳本語言來使用。他們會為每一次具體的改動編寫手冊、配置文件和執行腳本,再針對一部分指定的服務器手工運行它們,也就是說每一次改動都還需要花費專業知識、時間和精力。這種工作方式意味著基礎設施團隊沒有把他們自己從日常的重復性勞動中解放出來。目前已經有很多商業雲平臺提供了Docker服務,只需要將自己的 git repository 鏈接到平臺,即可以自動幫你完成部署,在雲上完成集成測試。
docker-compose build
docker-compose run app ginkgo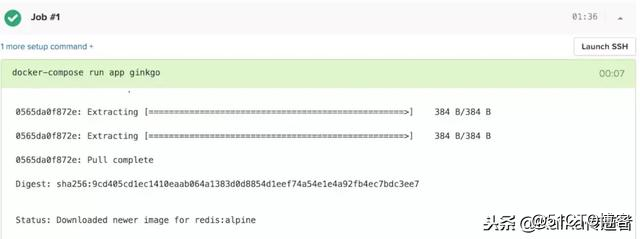
基於Kafka構建事件溯源模式的微服務