
python學習----網頁圖片文字識別(簡單)
在接觸python後想對圖片進行一些處理 python實現的程式碼很簡單 但是關鍵在於一些包的匯入
我使用的python 軟體是 pycharm 可以在setting中去下載requests這個包
在安裝包PIL 和pytesseract這兩個包的時候 出現了許多狀況 直接影響了我的學習進度
首先 pycharm 在setting中無法直接安裝PIL這個包 但是能可以下載pillow這個包 可以說pillow是PIL的升級版吧
然後就是下載pytesseract 這個包了 我們可以選擇使用pip 命令列進行下載 : pip install pytesseract
之後就是阻礙我進度的來了
我們下載了PIL 和pytesseract 這兩個包後是無法執行程式的 或者說 他依然還會報錯 是因為 我們還得下載Tesseract-ocr 這個識別引擎 網上都有安裝包 在這裡就不詳細描述了 下載安裝後 因為我們進行的是中文文字的識別 所以還得有一箇中文語言包(或著 可以在安裝tesseract-ocr時 直接選擇下載所有的語言包 等待時間較長):chi_sim.traineddata

然後這樣子執行還是會報錯 首先你的配置ocr的環境 (最好放在最上面,我的老師告訴我這個還有優先順序問題)
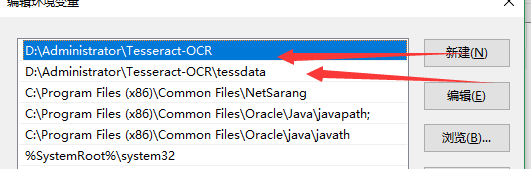
然後在path中新建一個
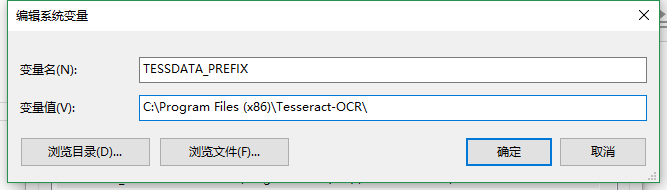
然後進入pytesseract.py檔案中進行修改tesseract_cmd
將等號後面的地址 換成在你電腦上的位置 前面加上r 是為了防止轉義

# 匯入包
import requests
from PIL import Image
import pytesseract
# 模仿瀏覽器 進行訪問
headers = {"User-Agent": " Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)"}
# 獲取網址 ( 該網址是我所讀學校的官網上圖片 所以我進行了處理 刪掉了一點內容)
url = " http:/*******edu.cn/_upload/article/images/13/d0/55f5bd084947b5f0bd5870f507fd/739926cd-a4ec-4ad9-bec0-d044e3db47c4.jpg"
# 獲取圖片 對圖片進行處理
res =requests.get(url = url , headers =headers)
f = open ("c.jpg", "wb")
f.write(res.content)
f.close()
# 圖片文字識別
text = pytesseract.image_to_string(Image.open("c.jpg"),lang = "chi_sim")
print(text)
最後我終於成功地執行出來了 哈哈哈
