
Scrapy框架的安裝(windows)
用anaconda安裝
這種方法是最快的。前提是安裝了anaconda。
方法:命令列執行 conda install scrapy

詢問是否安裝新的包 ,輸入y回車即可。
整個過程非常省心。
———————————————————————————————————————————
不使用anaconda的話,可以看下面的方法:
常規安裝
首先在命令列測試一下:
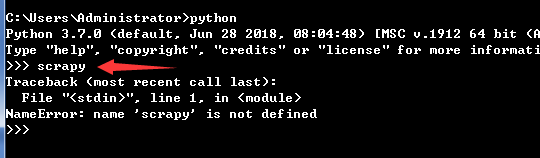
這說明scrapy框架還沒有安裝。
由於主要使用pip安裝,所以我們先檢查一下:

第一步:安裝wheel
pip install wheel
第二步:安裝 lxml
http://www.lfd.uci.edu/~gohlke/pythonlibs/#lxml

下載好以後,把路徑複製一下:
然後使用pip install + 路徑 進行安裝

第三步:安裝pyOpenSSL
從官方網站 https://pypi.python.org/pypi/pyOpenSSL#downloads 找到對應版本的whl檔案。

下載之後同樣把路徑和名稱複製一下,然後用pip install +路徑來安裝:

第四步:安裝 Twisted
這是一個非同步框架,是scrapy的核心。
從 http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted 找到對應版本的whl檔案下載:

按照上面的方法,同樣用pip安裝就可以了。
官方網站 https://sourceforge.net/projects/pywin32/files/pywin32/ 從222版本開始後,只在github上釋出了,所以我們找到github上的地址:
https://github.com/mhammond/pywin32/releases
注意:選擇最接近本機環境版本的安裝包來進行安裝,不然可能會失敗。

下載後直接執行安裝,然後狂點下一步即可,路徑會預設安裝在python的目錄下。
第六步:安裝Scrapy
pip install scrapy


大功告成!
試一下:

這代表以及安裝成功。
測試
建立第一個爬蟲:
scrapy startproject papapa #建立一個爬蟲專案
cd papapa #進入到爬蟲專案目錄
scrapy genspider baidu www.baidu.com#建立一個具體的爬蟲
scrapy crawl baidu #執行爬蟲


最後執行:
scrapy genspider baidu www.baidu.com

很悲劇,報錯了。發生了“ImportError:DLL load failed:作業系統無法執行%1 ”的錯誤。
查了一下,解決辦法如下:把C:\Windows\System32目錄下的libeay32.dll和ssleay32.dll刪除即可(但是可能會對其他依賴這兩個DLL的軟體有影響)。
我這兒沒有ssleay32.dll,只刪除了一個。
再來試試:

這回可以了。
執行爬蟲:
scrapy crawl baidu

穩哪。