
python--檔案流讀寫
在講述fileinput模組之前,首先說一下python內建的檔案API—open()函式以及與其相關的函式。
我這裡主要講講其中四個比較重要和常用的方法,更多的方法,可以參考:菜鳥教程http://www.runoob.com/python/file-methods.html
(1)file = open(file_name [, access_mode][, buffering])
引數解析:
1. file_name:
file_name變數是一個需要訪問的檔名稱的字串值,在應用中需要用單引號或者雙引號將檔名包裹起來。
2. access_mode:
access_mode決定了開啟檔案的模式:只讀,寫入,追加等。這個引數是非強制的,預設檔案訪問模式為只讀(r)
詳細模式可以參考:菜鳥教程http://www.runoob.com/python/python-files-io.html
3. buffering:
這個引數用於設定快取區的大小。如果buffering的值被設為0,就不會有快取。如果buffering的值取1,訪問檔案時會寄存行。如果將buffering的值設為大於1的整數,這個整數就為快取區的快取大小。如果取負值,寄存區的緩衝大小則為系統預設。
(2)file.flush()方法
用於重新整理緩衝區,,即將緩衝區中的資料立刻寫入檔案,同時清空緩衝區
flush()方法在爬蟲中也用得挺多,在爬蟲過程由於種種原因,程式中斷,寫入快取的資料沒有寫入磁碟很可惜,所以可以手動新增flush()方法
(3)file.close()方法
關閉檔案,並將緩衝區的資料寫入檔案中。
檔案的快取機制
在寫入檔案內容的時候,在我們呼叫python的write()函式對檔案進行寫入的時候,python解析器會呼叫作業系統的write方法,但值得注意的是,不是馬上儲存到磁碟中的,是先寫到核心的緩衝區裡面,只有當我們主動呼叫flush()函式或者close()函式的時候,才會將緩衝區的內容寫入磁碟中。另外當寫入的資料量大於或者等於緩衝區的大小的時候,寫緩衝會自動同步到磁碟。
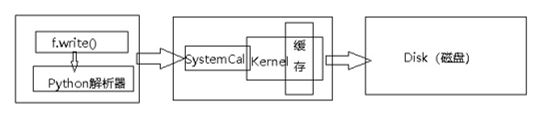
例如:
寫20萬行資料結果
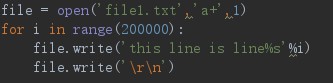
file = open('file1.txt','a+') for i in range(200000): file.write('this line is line%s'%i) file.write('\r\n')
pycharm報出如下的提示
![]()

因為我設定的buffering是預設的系統的快取大小,所以當寫到1999856行時,就剛好到系統的快取區大小,因為所需要寫的資料大於快取區的大小,所以這些內容直接就寫入了磁碟,而1998856後面的資料在寫入的時候還是先寫到了快取區中,而這些資料的大小顯然是小於快取區大小的,所以被儲存在快取區中,並沒有寫到磁碟。
使用flush()方法後,所有在快取區的資料都會寫入到磁碟中

如果我直接在呼叫open()方法的時候像下面這樣設定buffering為1,就無需擔心快取的問題了
(4)file.seek(offset [,whence]) 檔案指標
當檔案進行寫入或者讀取的時候,檔案指標會根據具體的內容進行移動。
引數解析:
offset:偏移量,代表需要移動偏移的位元組數
whence:可選引數,預設值為 0。作用是給offset引數設定起始值,表示要從哪個位置開始偏移。0代表從檔案開頭開始算起,1代表從當前位置開始算起,2代表從檔案末尾算起。
例如以下案例:
file = open('file.txt','a+',1) for i in range(200): file.write('this line is line%s'%i) file.write('\r\n') for line in file: print(line) file.close()
終端沒有列印任何資料
如果將程式碼順序修改一下
file = open('file.txt','a+',1) for i in range(200): file.write('this line is line%s'%i) file.write('\r\n') file.close() f = open('file.txt','r+') for line in f: print(line) f.close()
終端打印出資料
那麼怎麼用seek()方法呢?
import os file = open('file.txt','a+',1) for i in range(200): file.write('this line is line%s'%i) file.write('\r\n') file.seek(0,os.SEEK_SET) for line in file: print(line) file.close()
同樣也能打印出資料
上面,我用了os模組的SEEK_SET
os模組有這些內容:
os.SEEK_SET:表示檔案的相對起始位置
os.SEEK_CUR:表示檔案的相對當前位置
os.SEEK_END:表示檔案的相對結束位置
關於fileinput模組
fileinput可以對檔案進行細緻化的處理,比直接的open方法有更多檔案操擴充套件。可以一次性迭代一個或者多個檔案,並對檔案進行修改。
主要的函式有:
1. input([files[,inplace[,backup]]]) 幫助迭代多個輸入流中的行
2. filename() 返回當前檔案的名稱
3.nestfile() 關閉當前檔案並移動到下一個檔案
4. close() 關閉序列(多個檔案
5. lineno() 返回(多個檔案累計的)當前行號
6. filelineno() 返回在當前檔案的行好
7. isfirstline() 檢查當前是否是當前檔案中的第一行
8. isstdin() 檢查最後一行是否來自sys.stdin
可以理解,fileinput模組重點是對多檔案的讀取和適當時候的修改。而沒有直接的寫操作
1. input()方法
這個函式是fileinput模組中最重要的一個函式,引數相對複雜一點。
官方的定義:
fileinput.input([files[, inplace[, backup[, bufsize[, mode[, openhook]]]]]])

input(files=None, inplace=False, backup='', bufsize=0, mode='r', openhook=None)
1)files列表,可以是一個檔案,也可以是多個檔案的列表形式
2)inplace 是否對檔案進行就地修改。預設為False,設定為False跟檔案的open區別不大
3)mode 讀取的格式
官方:FileInput opening mode must be one of 'r', 'rU', 'U' and 'rb' (b:二進位制位元組模式和U:unicode模式)
4)backup 檔案備份,為原本的檔案做一份備份,不作任何修改,其實就是複製。備份的檔名是原本的檔名+備份檔名。注意備份檔案需要把檔案的格式也寫進去。一般backup需要與引數inplace一起使用才有意義。而在設定了inplace=True,一般同時會設定backup引數來備份原本的檔案內容。
例子:在每一行文字的前面新增 ‘#行號’字樣
單個檔案案例:
for line in fileinput.input('file.txt',inplace=True,mode='r',backup='file_back.txt'): num = fileinput.filelineno() print('#%s'%num+' '+line)
如果inplace設定為True,即就地修改,必須要有print函式將讀取的資料重新寫回當前的檔案中,否則檔案的資料最後會變成空。所以使用inplace時候必須很小心。
備份後的檔案目錄
多個檔案案例
for line in fileinput.input(files=['file.txt','file1.txt'],inplace=True,mode='r',backup='file_back.txt'):
num = fileinput.filelineno()
print('#%s'%num+' '+line
通常fileinput模組會結合re模組一起使用,例如在對日誌的分析中會很有用
例如,這裡有一個monoodb的log檔案內容

希望獲取日期為11-13的日誌
import fileinput import re for line in fileinput.input('mongolog.txt',mode='r',inplace=True,backup='log_backup.txt'): pattern = '2018-11-13' if re.search(pattern,line): print(line)
獲取結果在原log.txt檔案中,備份檔案中的內容與原檔案相同
