
[轉帖]nvidia nvlink互聯與nvswitch介紹
阿新 • • 發佈:2018-11-15
nvidia nvlink互聯與nvswitch介紹
https://www.chiphell.com/thread-1851449-1-1.html
差不多在一個月前在年度gtc會議上,老黃公開了dgx-2,這臺售價高達399k美元,重達350磅的怪獸是專門為了加速ai負載而研製的,他被授予了“世界最大的gpu”稱號。為什麼它被賦予這個名字,它又是如何產生的,我們需要把時間倒退到幾年之前。
動機
在nvidia推出目前這個方案之前,為了獲得更多的強力計算節點,多個GPU通過PCIe Switch直接與CPU相連。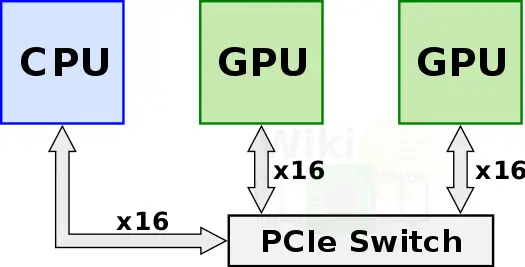
他們之間的pcie 3.0*16有接近32GB/s的雙向頻寬,但是當訓練資料不停增長的時候,這個互聯方案本身卻成為了致命的系統瓶頸。如果不改進這個互聯頻寬,那麼新時代GPU帶來的額外效能就沒法發揮出來,從而無法滿足現實需求負載的增長。
NVLink
為了解決這個問題,nvidia開發了一個全新的互聯構架nvlink。單條nvlink是一種雙工雙路通道,其通過組合32條配線,從而在每個方向上可以產生8對不同的配對(2bi*8pair*2wire=32wire),第一版的實現被稱為nvlink 1.0,與P100 GPU一同釋出。一塊P100上,集成了4條nvlink。每條link具備雙路共40GB/s的頻寬,整個晶片具備整整160GB/s的頻寬。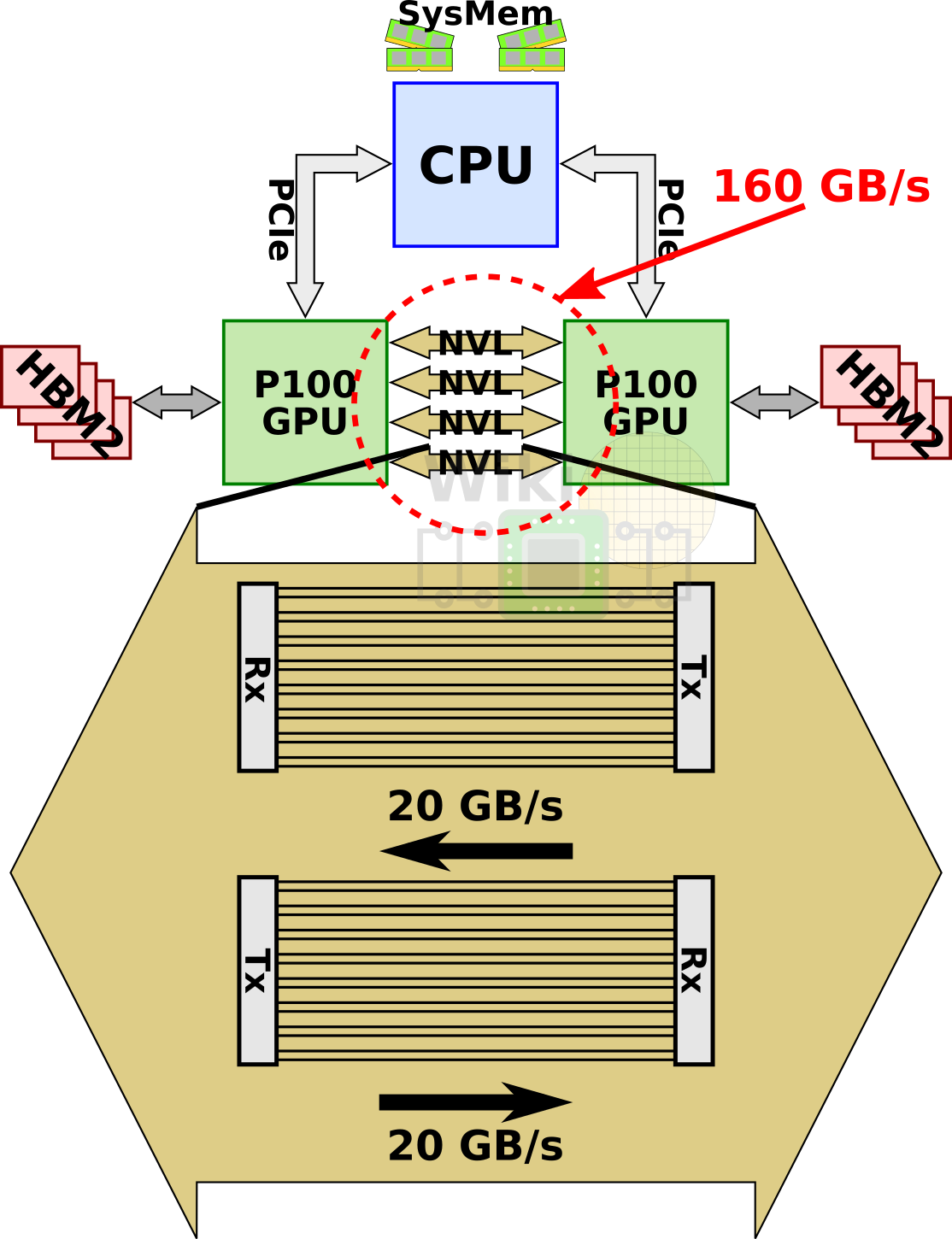
當然,nvlink不僅僅只是限定在GPU之間互聯上。IBM將nvlink 1.0新增到他們基於Power8+微架構的Power處理器上,這一舉措使得P100可以直接通過nvlink於CPU相連,而無需通過pcie。通過與最近的power8+ cpu相連,4GPU的節點可以配置成一種全連線的mesh結構。
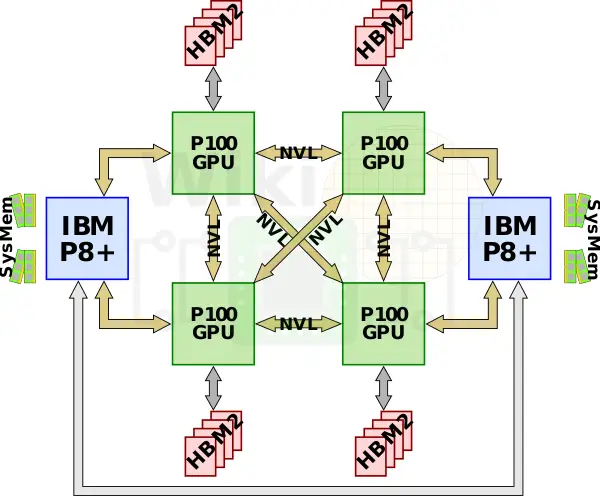
DGX-1
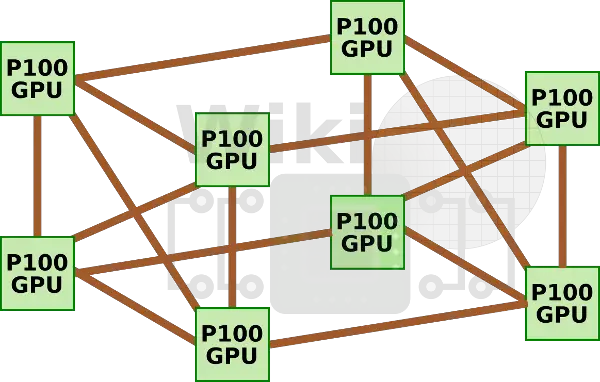
第一種nvidia專門為AI加速訂製的機器叫做dgx1,它集成了八塊p100與兩塊志強e5 2698v4,但是因為每塊GPU只有4路nvlink,這些GPU構成了一種混合的cube-mesh網路拓撲結構,GPU被4塊4塊分為兩組,然後在互相連線。
同時,因為GPU需要的pcie通道數量超過了晶片組所能提供的數量,所以每一對GPU將連線到一組pcie switch上與志強相連,然後兩塊志強再通過qpi匯流排連線。
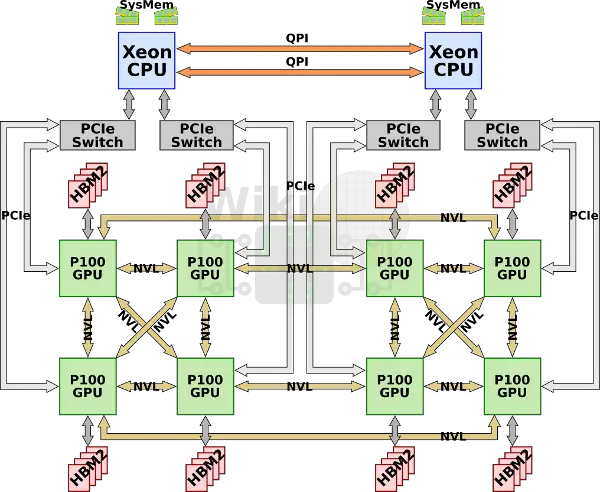
6塊P100,每塊16GB HBM2視訊記憶體,總計128GB視訊記憶體和512GB DDR4-2133系統記憶體。
nvlink 2.0
nvlink的第二個版本與gv100一同而來。IBM計劃在Power9 cpu上給與支援。nvlink 2.0提升了訊號的傳輸率,從20Gb/s到了25Gb/s,雙通道總計50GB/s,pre nvlink。同時進一步提升了nvlink數到6路。這些舉措讓v100的總頻寬從p100的160GB/s提升到了300GB/s。
順便說下,除了頻寬的增長,nvidia還添加了數個新的operational feature到協議本身。其中最有意思的一個特性是引入了coherency operation快取一致性操作,它允許CPU在讀取資料時快取GPU視訊記憶體訊號,這將極大的降低訪問延遲。
去年nvidia將原始dgx-1升級到v100架構。因為主要的cube-mesh拓撲結構並沒有變化,所以多出來的link用來倍化一些GPU之間的互聯。
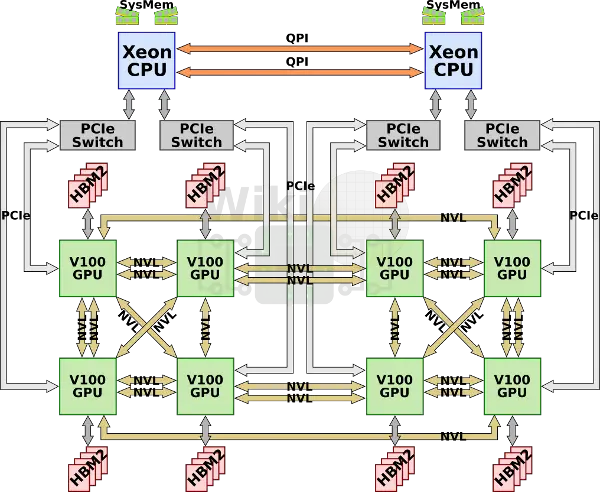

DGX-2
最近的GTC2018釋出的dgx-2,其加倍了v100的數量,最終高達16塊v100。同時hbm2升級到32GB/塊,一共高達512GB,cpu升級為雙路2.7G 24核 志強白金8168.
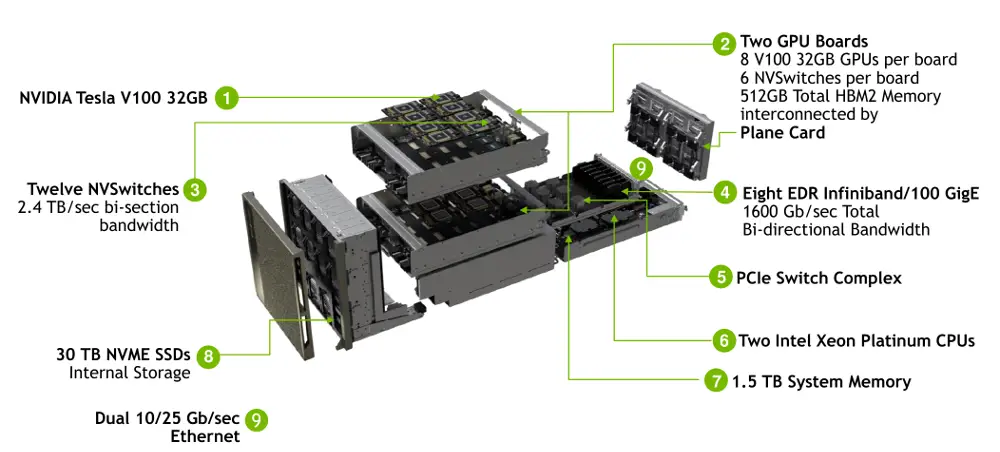
升級到16塊GPU,對於系統而言也要做出巨大的改變,特別是更快更大的網際網路絡頻寬。
NVSwitch
那麼dgx-2中裝載的是什麼呢,是一塊新的asic - nvswitch。nvswitch是一塊獨立的nvlink晶片,其提供了高達18路nvlink的介面。這塊晶片據說已經開發了兩年之久。其支援nvlink 2.0,也就意味著每個介面均能提供雙通道高達50GB/s的頻寬,那麼這塊晶片總計能夠提供900GB/s的頻寬。這塊晶片功率100w,基於臺積電12nm FinFet FFN nvidia訂製工藝,來源於增強的16nm節點,擁有2b個電晶體。

這塊die封裝在1940個pin大小為4cm2的BGA晶片中,其中576個針腳專門服務於18路的nvlink,剩下的陣腳則用於電源,或者其他I/O介面,比如用於管理埠的x4 pcie,I2c,GPIO等等。

通過nvswitch提供的18路介面,nvswitch能夠讓nvidia設計出完全無阻塞的全互聯16路GPU系統。每塊v100中的6路nvlink將分別連線到6塊nvswitch上面。這樣8塊v100與6塊nvsiwtch完全連線,構成一個基板。
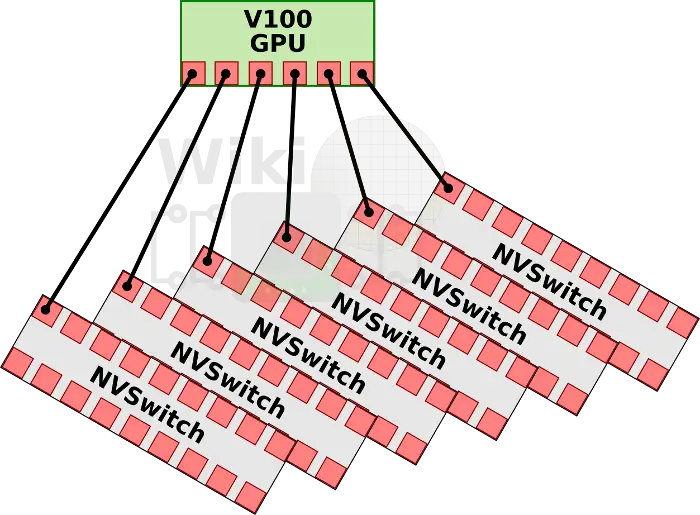
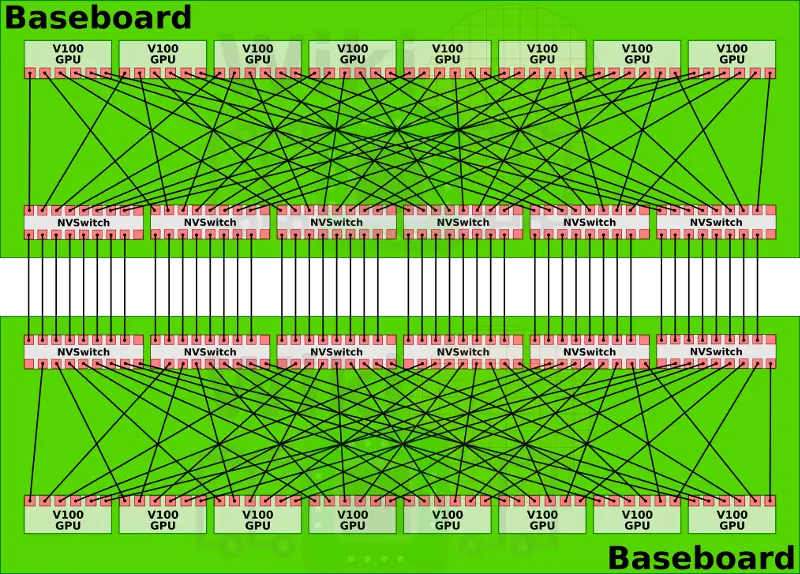
dgx2擁有兩塊基板,這兩塊基板則是通過nvswitch剩餘的另一側介面完全互聯在一起,這就構成了一個16路全連線的GPU構架。
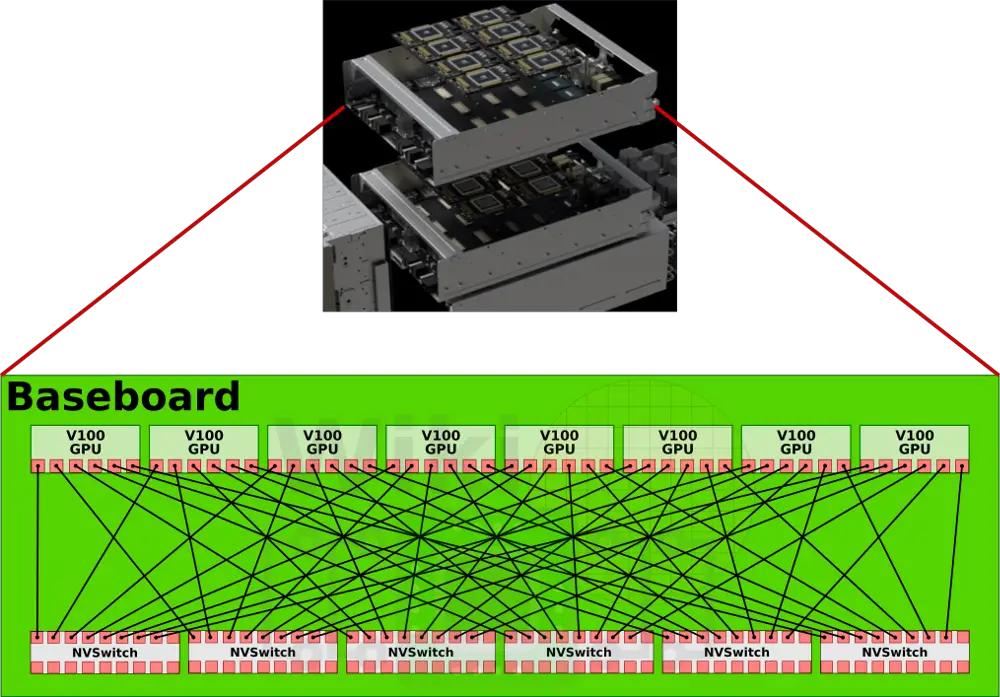
兩塊基板之間的nvswitch之間都有八路link互聯,16塊GPU每塊有6路nvlink的情況下,其總雙路頻寬達到2400GB/s。有趣的是,其實nvswitch有18路介面nvidia卻只用到了其中16路。一種可能性是nv留下兩路用於支援ibm的power9處理器(dgx1和2都是用的志強)。在這個複雜的結構中,power9處理器可能分別接在兩塊基板的nvsiwtch上,這樣GPU也與Power9處於全連線狀態。如果CPU直接與nvswitch相連,那麼pcie就不再擔任cpu與gpu相連的責任。目前nvidia還沒有向其他廠商開放nvswitch,如果他們決定開放,將會產生一些新型態的,可能更加規模龐大的結算節點。
在原始的dgx-1中,執行GPU之間的事務處理需要一個額外的hop,這將導致遠端訪問的不一致性。在很多負載中,這會讓利用統一定址變得困難,產生了一些不確定性。在dgx2中,每一塊gpu都可以於另外一塊gpu以相同的速度和一致性延遲交流。大型的AI負載能夠通過並行化的模型技術得到巨大的提升。回到GTC中,nvidia賦予的名稱“世界最大的GPU”。在實踐中,因為每塊GPU和其他夥伴直接互聯,統一定址也變的簡單有效。現在,可以合併512GiB高速頻寬的視訊記憶體,將他虛擬化成一塊統一的記憶體。無論是GPU本身還是nvswitch都有相應的演算法用於實現這一統一的記憶體系統。在程式層面,整臺機器將會被當作一塊GPU和一個整體的視訊記憶體,這個視訊記憶體子系統將會自行管理視訊記憶體layout,提供最優化的組織架構。