
索引與優化
http://www.cnblogs.com/hustcat/archive/2009/10/28/1591648.html
寫在前面:索引對查詢的速度有著至關重要的影響,理解索引也是進行資料庫效能調優的起點。考慮如下情況,假設資料庫中一個表有10^6條記錄,DBMS的頁面大小為4K,並存儲100條記錄。如果沒有索引,查詢將對整個表進行掃描,最壞的情況下,如果所有資料頁都不在記憶體,需要讀取10^4個頁面,如果這10^4個頁面在磁碟上隨機分佈,需要進行10^4次I/O,假設磁碟每次I/O時間為10ms(忽略資料傳輸時間),則總共需要100s(但實際上要好很多很多)。如果對之建立B-Tree索引,則只需要進行log100(10^6)=3次頁面讀取,最壞情況下耗時30ms。這就是索引帶來的效果,很多時候,當你的應用程式進行SQL查詢速度很慢時,應該想想是否可以建索引。進入正題:
第二章、索引與優化
1、選擇索引的資料型別
MySQL支援很多資料型別,選擇合適的資料型別儲存資料對效能有很大的影響。通常來說,可以遵循以下一些指導原則:
(1)越小的資料型別通常更好:越小的資料型別通常在磁碟、記憶體和CPU快取中都需要更少的空間,處理起來更快。(2)簡單的資料型別更好:整型資料比起字元,處理開銷更小,因為字串的比較更復雜。在MySQL中,應該用內建的日期和時間資料型別,而不是用字串來儲存時間;以及用整型資料型別儲存IP地址。
(3)儘量避免NULL:應該指定列為NOT NULL,除非你想儲存NULL。在MySQL中,含有空值的列很難進行查詢優化,因為它們使得索引、索引的統計資訊以及比較運算更加複雜。你應該用0、一個特殊的值或者一個空串代替空值。
1.1、選擇識別符號
選擇合適的識別符號是非常重要的。選擇時不僅應該考慮儲存型別,而且應該考慮MySQL是怎樣進行運算和比較的。一旦選定資料型別,應該保證所有相關的表都使用相同的資料型別。
(1) 整型:通常是作為識別符號的最好選擇,因為可以更快的處理,而且可以設定為AUTO_INCREMENT。
(2) 字串:儘量避免使用字串作為識別符號,它們消耗更好的空間,處理起來也較慢。而且,通常來說,字串都是隨機的,所以它們在索引中的位置也是隨機的,這會導致頁面分裂、隨機訪問磁碟,聚簇索引分裂(對於使用聚簇索引的儲存引擎)。
2、索引入門
對於任何DBMS,索引都是進行優化的最主要的因素。對於少量的資料,沒有合適的索引影響不是很大,但是,當隨著資料量的增加,效能會急劇下降。
如果對多列進行索引(組合索引),列的順序非常重要,MySQL僅能對索引最左邊的字首進行有效的查詢。例如:
假設存在組合索引it1c1c2(c1,c2),查詢語句select * from t1 where c1=1 and c2=2能夠使用該索引。查詢語句select * from t1 where c1=1也能夠使用該索引。但是,查詢語句select * from t1 where c2=2不能夠使用該索引,因為沒有組合索引的引導列,即,要想使用c2列進行查詢,必需出現c1等於某值。
2.1、索引的型別
索引是在儲存引擎中實現的,而不是在伺服器層中實現的。所以,每種儲存引擎的索引都不一定完全相同,並不是所有的儲存引擎都支援所有的索引型別。
2.1.1、B-Tree索引
假設有如下一個表:
| CREATE TABLE People ( last_name varchar(50) not null, first_name varchar(50) not null, dob date not null, gender enum('m', 'f') not null, key(last_name, first_name, dob) ); |
其索引包含表中每一行的last_name、first_name和dob列。其結構大致如下:
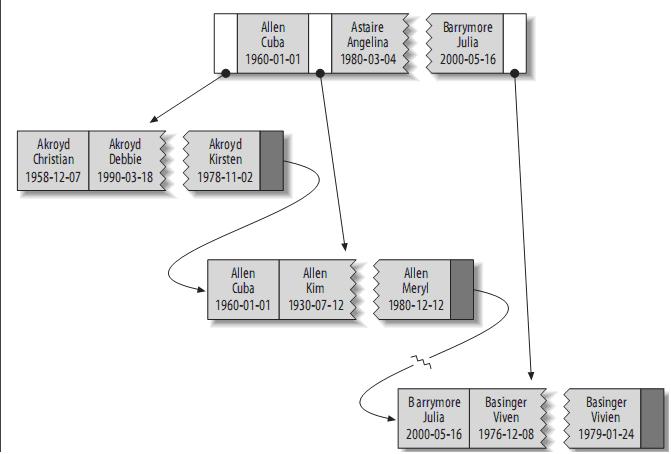
索引儲存的值按索引列中的順序排列。可以利用B-Tree索引進行全關鍵字、關鍵字範圍和關鍵字字首查詢,當然,如果想使用索引,你必須保證按索引的最左邊字首(leftmost prefix of the index)來進行查詢。
(1)匹配全值(Match the full value):對索引中的所有列都指定具體的值。例如,上圖中索引可以幫助你查找出生於1960-01-01的Cuba Allen。
(2)匹配最左字首(Match a leftmost prefix):你可以利用索引查詢last name為Allen的人,僅僅使用索引中的第1列。
(3)匹配列字首(Match a column prefix):例如,你可以利用索引查詢last name以J開始的人,這僅僅使用索引中的第1列。
(4)匹配值的範圍查詢(Match a range of values):可以利用索引查詢last name在Allen和Barrymore之間的人,僅僅使用索引中第1列。
(5)匹配部分精確而其它部分進行範圍匹配(Match one part exactly and match a range on another part):可以利用索引查詢last name為Allen,而first name以字母K開始的人。
(6)僅對索引進行查詢(Index-only queries):如果查詢的列都位於索引中,則不需要讀取元組的值。
由於B-樹中的節點都是順序儲存的,所以可以利用索引進行查詢(找某些值),也可以對查詢結果進行ORDER BY。當然,使用B-tree索引有以下一些限制:
(1) 查詢必須從索引的最左邊的列開始。關於這點已經提了很多遍了。例如你不能利用索引查詢在某一天出生的人。
(2) 不能跳過某一索引列。例如,你不能利用索引查詢last name為Smith且出生於某一天的人。
(3) 儲存引擎不能使用索引中範圍條件右邊的列。例如,如果你的查詢語句為WHERE last_name="Smith" AND first_name LIKE 'J%' AND dob='1976-12-23',則該查詢只會使用索引中的前兩列,因為LIKE是範圍查詢。
2.1.2、Hash索引
MySQL中,只有Memory儲存引擎顯示支援hash索引,是Memory表的預設索引型別,儘管Memory表也可以使用B-Tree索引。Memory儲存引擎支援非唯一hash索引,這在資料庫領域是罕見的,如果多個值有相同的hash code,索引把它們的行指標用連結串列儲存到同一個hash表項中。
假設建立如下一個表:
CREATE TABLE testhash (
fname VARCHAR(50) NOT NULL,
lname VARCHAR(50) NOT NULL,
KEY USING HASH(fname)
) ENGINE=MEMORY;
包含的資料如下: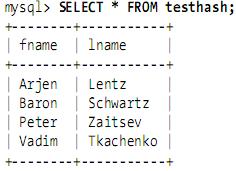
假設索引使用hash函式f( ),如下:
| f('Arjen') = 2323 f('Baron') = 7437 f('Peter') = 8784 f('Vadim') = 2458 |
此時,索引的結構大概如下:
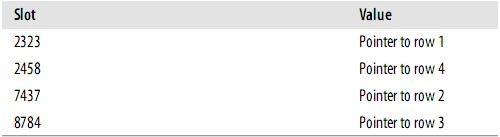
Slots是有序的,但是記錄不是有序的。當你執行
mysql> SELECT lname FROM testhash WHERE fname='Peter';
MySQL會計算’Peter’的hash值,然後通過它來查詢索引的行指標。因為f('Peter') = 8784,MySQL會在索引中查詢8784,得到指向記錄3的指標。
因為索引自己僅僅儲存很短的值,所以,索引非常緊湊。Hash值不取決於列的資料型別,一個TINYINT列的索引與一個長字串列的索引一樣大。
Hash索引有以下一些限制:
(1)由於索引僅包含hash code和記錄指標,所以,MySQL不能通過使用索引避免讀取記錄。但是訪問記憶體中的記錄是非常迅速的,不會對性造成太大的影響。
(2)不能使用hash索引排序。
(3)Hash索引不支援鍵的部分匹配,因為是通過整個索引值來計算hash值的。
(4)Hash索引只支援等值比較,例如使用=,IN( )和<=>。對於WHERE price>100並不能加速查詢。
2.1.3、空間(R-Tree)索引
MyISAM支援空間索引,主要用於地理空間資料型別,例如GEOMETRY。
2.1.4、全文(Full-text)索引
全文索引是MyISAM的一個特殊索引型別,主要用於全文檢索。
3、高效能的索引策略
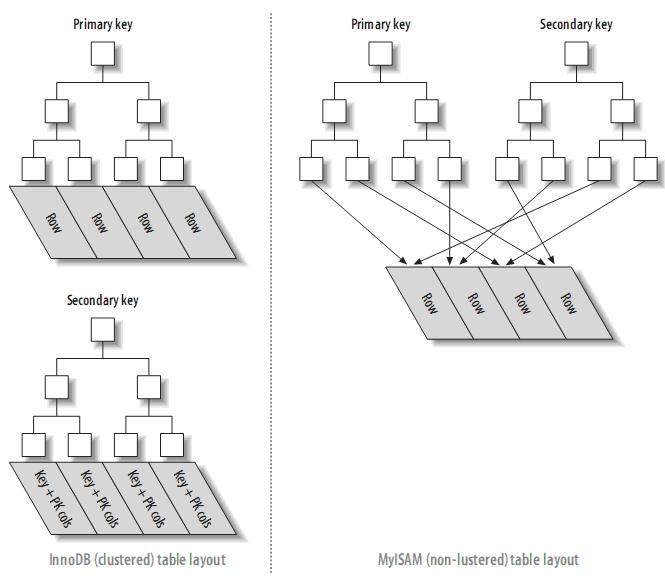
3.1、聚簇索引(Clustered Indexes)
聚簇索引保證關鍵字的值相近的元組儲存的物理位置也相同(所以字串型別不宜建立聚簇索引,特別是隨機字串,會使得系統進行大量的移動操作),且一個表只能有一個聚簇索引。因為由儲存引擎實現索引,所以,並不是所有的引擎都支援聚簇索引。目前,只有solidDB和InnoDB支援。
聚簇索引的結構大致如下: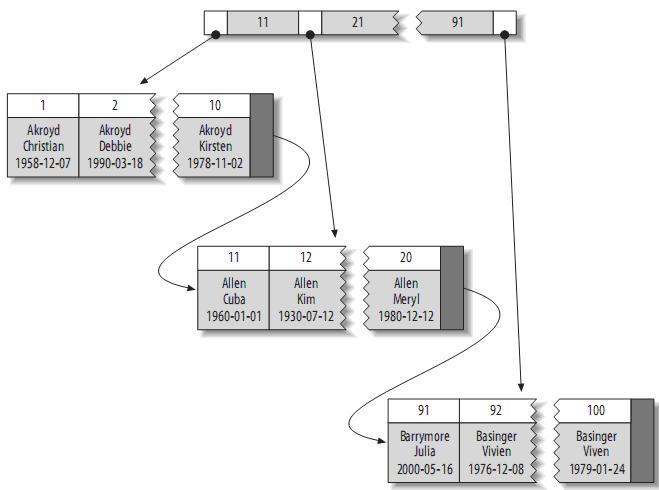
注:葉子頁面包含完整的元組,而內節點頁面僅包含索引的列(索引的列為整型)。一些DBMS允許使用者指定聚簇索引,但是MySQL的儲存引擎到目前為止都不支援。InnoDB對主鍵建立聚簇索引。如果你不指定主鍵,InnoDB會用一個具有唯一且非空值的索引來代替。如果不存在這樣的索引,InnoDB會定義一個隱藏的主鍵,然後對其建立聚簇索引。一般來說,DBMS都會以聚簇索引的形式來儲存實際的資料,它是其它二級索引的基礎。
3.1.1、InnoDB和MyISAM的資料佈局的比較
為了更加理解聚簇索引和非聚簇索引,或者primary索引和second索引(MyISAM不支援聚簇索引),來比較一下InnoDB和MyISAM的資料佈局,對於如下表:
| CREATE TABLE layout_test ( col1 int NOT NULL, col2 int NOT NULL, PRIMARY KEY(col1), KEY(col2) ); |
假設主鍵的值位於1---10,000之間,且按隨機順序插入,然後用OPTIMIZE TABLE進行優化。col2隨機賦予1---100之間的值,所以會存在許多重複的值。
(1) MyISAM的資料佈局
其佈局十分簡單,MyISAM按照插入的順序在磁碟上儲存資料,如下: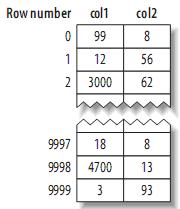
注:左邊為行號(row number),從0開始。因為元組的大小固定,所以MyISAM可以很容易的從表的開始位置找到某一位元組的位置。
據些建立的primary key的索引結構大致如下: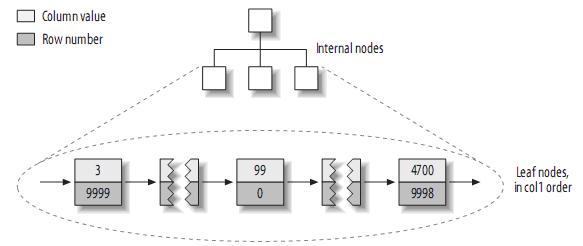
注:MyISAM不支援聚簇索引,索引中每一個葉子節點僅僅包含行號(row number),且葉子節點按照col1的順序儲存。
來看看col2的索引結構: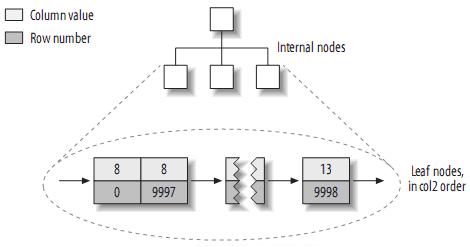
實際上,在MyISAM中,primary key和其它索引沒有什麼區別。Primary key僅僅只是一個叫做PRIMARY的唯一,非空的索引而已。
(2) InnoDB的資料佈局
InnoDB按聚簇索引的形式儲存資料,所以它的資料佈局有著很大的不同。它儲存表的結構大致如下: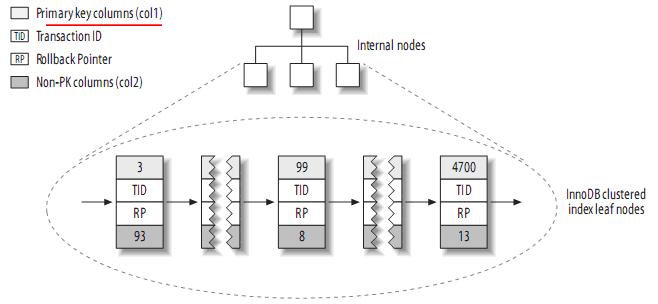
注:聚簇索引中的每個葉子節點包含primary key的值,事務ID和回滾指標(rollback pointer)——用於事務和MVCC,和餘下的列(如col2)。
相對於MyISAM,二級索引與聚簇索引有很大的不同。InnoDB的二級索引的葉子包含primary key的值,而不是行指標(row pointers),這減小了移動資料或者資料頁面分裂時維護二級索引的開銷,因為InnoDB不需要更新索引的行指標。其結構大致如下: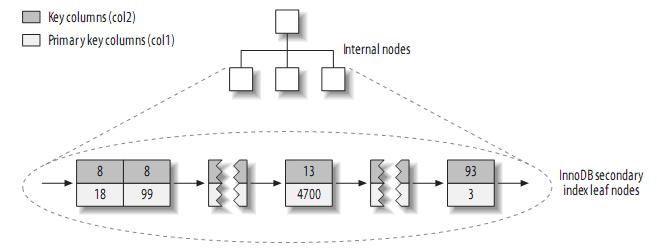
聚簇索引和非聚簇索引表的對比:
3.1.2、按primary key的順序插入行(InnoDB)
如果你用InnoDB,而且不需要特殊的聚簇索引,一個好的做法就是使用代理主鍵(surrogate key)——獨立於你的應用中的資料。最簡單的做法就是使用一個AUTO_INCREMENT的列,這會保證記錄按照順序插入,而且能提高使用primary key進行連線的查詢的效能。應該儘量避免隨機的聚簇主鍵,例如,字串主鍵就是一個不好的選擇,它使得插入操作變得隨機。
3.2、覆蓋索引(Covering Indexes)
如果索引包含滿足查詢的所有資料,就稱為覆蓋索引。覆蓋索引是一種非常強大的工具,能大大提高查詢效能。只需要讀取索引而不用讀取資料有以下一些優點:
(1)索引項通常比記錄要小,所以MySQL訪問更少的資料;
(2)索引都按值的大小順序儲存,相對於隨機訪問記錄,需要更少的I/O;
(3)大多資料引擎能更好的快取索引。比如MyISAM只快取索引。
(4)覆蓋索引對於InnoDB表尤其有用,因為InnoDB使用聚集索引組織資料,如果二級索引中包含查詢所需的資料,就不再需要在聚集索引中查找了。
覆蓋索引不能是任何索引,只有B-TREE索引儲存相應的值。而且不同的儲存引擎實現覆蓋索引的方式都不同,並不是所有儲存引擎都支援覆蓋索引(Memory和Falcon就不支援)。
對於索引覆蓋查詢(index-covered query),使用EXPLAIN時,可以在Extra一列中看到“Using index”。例如,在sakila的inventory表中,有一個組合索引(store_id,film_id),對於只需要訪問這兩列的查詢,MySQL就可以使用索引,如下:
| mysql> EXPLAIN SELECT store_id, film_id FROM sakila.inventory\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: inventory type: index possible_keys: NULL key: idx_store_id_film_id key_len: 3 ref: NULL rows: 5007 Extra: Using index 1 row in set (0.17 sec) |
在大多數引擎中,只有當查詢語句所訪問的列是索引的一部分時,索引才會覆蓋。但是,InnoDB不限於此,InnoDB的二級索引在葉子節點中儲存了primary key的值。因此,sakila.actor表使用InnoDB,而且對於是last_name上有索引,所以,索引能覆蓋那些訪問actor_id的查詢,如:
| mysql> EXPLAIN SELECT actor_id, last_name -> FROM sakila.actor WHERE last_name = 'HOPPER'\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: actor type: ref possible_keys: idx_actor_last_name key: idx_actor_last_name key_len: 137 ref: const rows: 2 Extra: Using where; Using index |
3.3、利用索引進行排序
MySQL中,有兩種方式生成有序結果集:一是使用filesort,二是按索引順序掃描。利用索引進行排序操作是非常快的,而且可以利用同一索引同時進行查詢和排序操作。當索引的順序與ORDER BY中的列順序相同且所有的列是同一方向(全部升序或者全部降序)時,可以使用索引來排序。如果查詢是連線多個表,僅當ORDER BY中的所有列都是第一個表的列時才會使用索引。其它情況都會使用filesort。
| create table actor( actor_id int unsigned NOT NULL AUTO_INCREMENT, name varchar(16) NOT NULL DEFAULT '', password varchar(16) NOT NULL DEFAULT '', PRIMARY KEY(actor_id), KEY (name) ) ENGINE=InnoDB insert into actor(name,password) values('cat01','1234567'); insert into actor(name,password) values('cat02','1234567'); insert into actor(name,password) values('ddddd','1234567'); insert into actor(name,password) values('aaaaa','1234567'); |
| mysql> explain select actor_id from actor order by actor_id \G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: actor type: index possible_keys: NULL key: PRIMARY key_len: 4 ref: NULL rows: 4 Extra: Using index 1 row in set (0.00 sec)
mysql> explain select actor_id from actor order by password \G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: actor type: ALL possible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 4 Extra: Using filesort 1 row in set (0.00 sec)
mysql> explain select actor_id from actor order by name \G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: actor type: index possible_keys: NULL key: name key_len: 18 ref: NULL rows: 4 Extra: Using index 1 row in set (0.00 sec) |
當MySQL不能使用索引進行排序時,就會利用自己的排序演算法(快速排序演算法)在記憶體(sort buffer)中對資料進行排序,如果記憶體裝載不下,它會將磁碟上的資料進行分塊,再對各個資料塊進行排序,然後將各個塊合併成有序的結果集(實際上就是外排序)。對於filesort,MySQL有兩種排序演算法。
(1)兩遍掃描演算法(Two passes)
實現方式是先將須要排序的欄位和可以直接定位到相關行資料的指標資訊取出,然後在設定的記憶體(通過引數sort_buffer_size設定)中進行排序,完成排序之後再次通過行指標資訊取出所需的Columns。
注:該演算法是4.1之前採用的演算法,它需要兩次訪問資料,尤其是第二次讀取操作會導致大量的隨機I/O操作。另一方面,記憶體開銷較小。
(3) 一次掃描演算法(single pass)
該演算法一次性將所需的Columns全部取出,在記憶體中排序後直接將結果輸出。
注:從 MySQL 4.1 版本開始使用該演算法。它減少了I/O的次數,效率較高,但是記憶體開銷也較大。如果我們將並不需要的Columns也取出來,就會極大地浪費排序過程所需要的記憶體。在 MySQL 4.1 之後的版本中,可以通過設定 max_length_for_sort_data 引數來控制 MySQL 選擇第一種排序演算法還是第二種。當取出的所有大欄位總大小大於 max_length_for_sort_data 的設定時,MySQL 就會選擇使用第一種排序演算法,反之,則會選擇第二種。為了儘可能地提高排序效能,我們自然更希望使用第二種排序演算法,所以在 Query 中僅僅取出需要的 Columns 是非常有必要的。
當對連線操作進行排序時,如果ORDER BY僅僅引用第一個表的列,MySQL對該表進行filesort操作,然後進行連線處理,此時,EXPLAIN輸出“Using filesort”;否則,MySQL必須將查詢的結果集生成一個臨時表,在連線完成之後進行filesort操作,此時,EXPLAIN輸出“Using temporary;Using filesort”。
3.4、索引與加鎖
索引對於InnoDB非常重要,因為它可以讓查詢鎖更少的元組。這點十分重要,因為MySQL 5.0中,InnoDB直到事務提交時才會解鎖。有兩個方面的原因:首先,即使InnoDB行級鎖的開銷非常高效,記憶體開銷也較小,但不管怎麼樣,還是存在開銷。其次,對不需要的元組的加鎖,會增加鎖的開銷,降低併發性。
InnoDB僅對需要訪問的元組加鎖,而索引能夠減少InnoDB訪問的元組數。但是,只有在儲存引擎層過濾掉那些不需要的資料才能達到這種目的。一旦索引不允許InnoDB那樣做(即達不到過濾的目的),MySQL伺服器只能對InnoDB返回的資料進行WHERE操作,此時,已經無法避免對那些元組加鎖了:InnoDB已經鎖住那些元組,伺服器無法解鎖了。
來看個例子:
| create table actor( actor_id int unsigned NOT NULL AUTO_INCREMENT, name varchar(16) NOT NULL DEFAULT '', password varchar(16) NOT NULL DEFAULT '', PRIMARY KEY(actor_id), KEY (name) ) ENGINE=InnoDB insert into actor(name,password) values('cat01','1234567'); insert into actor(name,password) values('cat02','1234567'); insert into actor(name,password) values('ddddd','1234567'); insert into actor(name,password) values('aaaaa','1234567'); |
| SET AUTOCOMMIT=0; BEGIN; SELECT actor_id FROM actor WHERE actor_id < 4 AND actor_id <> 1 FOR UPDATE; |
該查詢僅僅返回2---3的資料,實際已經對1---3的資料加上排它鎖了。InnoDB鎖住元組1是因為MySQL的查詢計劃僅使用索引進行範圍查詢(而沒有進行過濾操作,WHERE中第二個條件已經無法使用索引了):
| mysql> EXPLAIN SELECT actor_id FROM test.actor -> WHERE actor_id < 4 AND actor_id <> 1 FOR UPDATE \G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: actor type: index possible_keys: PRIMARY key: PRIMARY key_len: 4 ref: NULL rows: 4 Extra: Using where; Using index 1 row in set (0.00 sec)
mysql> |
表明儲存引擎從索引的起始處開始,獲取所有的行,直到actor_id<4為假,伺服器無法告訴InnoDB去掉元組1。
為了證明row 1已經被鎖住,我們另外建一個連線,執行如下操作:
| SET AUTOCOMMIT=0; BEGIN; SELECT actor_id FROM actor WHERE actor_id = 1 FOR UPDATE; |
該查詢會被掛起,直到第一個連線的事務提交釋放鎖時,才會執行(這種行為對於基於語句的複製(statement-based replication)是必要的)。
如上所示,當使用索引時,InnoDB會鎖住它不需要的元組。更糟糕的是,如果查詢不能使用索引,MySQL會進行全表掃描,並鎖住每一個元組,不管是否真正需要。
http://www.cnblogs.com/hustcat/archive/2009/10/28/1591648.html