
pytorch啟用函式--LeakyReLU()
簡述
以前都是用ReLU(),第一見到LeakyReLU(),就研究了下原始碼中的註釋。
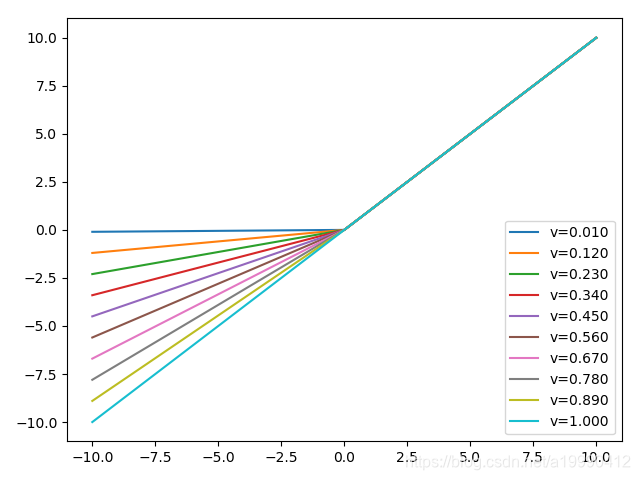
函式影象
LeakyReLU()是有一個引數的。
其實不難猜到,這個引數就是在小於0的部分的曲線的斜率。
程式碼
import torch
import torch.nn as nn
from torch.autograd import Variable
import matplotlib.pyplot as plt
import numpy as np
x = Variable(torch.linspace(-10, 10, 101))
varis = np.linspace( 相關推薦
pytorch啟用函式--LeakyReLU()
簡述 以前都是用ReLU(),第一見到LeakyReLU(),就研究了下原始碼中的註釋。 函式影象 LeakyReLU()是有一個引數的。 其實不難猜到,這個引數就是在小於0的部分的曲線的斜率。 程式碼 import torch import torch.nn
pytorch系列6 -- activation_function 啟用函式 relu, leakly_relu, tanh, sigmoid及其優缺點
主要包括: 為什麼需要非線性啟用函式? 常見的啟用函式有哪些? python程式碼視覺化啟用函式線上性迴歸中的變現 pytorch啟用函式的原始碼 為什麼需要非線性的啟用函式呢? 只是將兩個或多個線性網路層疊加,並不能學習一個新的東西,接下來通過簡
PyTorch基本用法(三)——啟用函式
文章作者:Tyan 部落格:noahsnail.com | CSDN | 簡書 本文主要是關於PyTorch的啟用函式。 import torch import torch.nn.fu
[PyTorch 學習筆記] 3.3 池化層、線性層和啟用函式層
> 本章程式碼:[https://github.com/zhangxiann/PyTorch_Practice/blob/master/lesson3/nn_layers_others.py](https://github.com/zhangxiann/PyTorch_Practice/blob/mas
Python3神經網路,經典簡單示例sigmoid啟用函式
選用了sigmoid作為啟用函式,作為輸出層的計算(多分類版本的logistic迴歸),影響輸出層的delta計算; 選用了squared-error作為損失函式(注:會影響calculate_loss函式的計算以及輸出層的delta計算) __author__ = '
caffe Python API 之啟用函式ReLU
import sys import os sys.path.append("/projects/caffe-ssd/python") import caffe net = caffe.NetSpec() net.data, net.label = caffe.layers.Data( name
誰擋了我的神經網路?(三)—— 啟用函式
誰擋了我的神經網路?(三)—— 啟用函式 這一系列文章介紹了在神經網路的設計和訓練過程中,可能提升網路效果的一些小技巧。前文介紹了在訓練過程中的一系列經驗,這篇文章將重點關注其中的啟用函式部分。更新於2018.11.1。 文章目錄 誰擋了我的神經網路?(三)
深度學習:卷積神經網路,卷積,啟用函式,池化
卷積神經網路——輸入層、卷積層、啟用函式、池化層、全連線層 https://blog.csdn.net/yjl9122/article/details/70198357?utm_source=blogxgwz3 一、卷積層 特徵提取 輸入影象是32*32*3,3是它的深度(即R
Sigmoid非線性啟用函式,FM調頻,膽機,HDR的意義
前幾天家裡買了個二手車子,較老,發現只有FM收音機,但音響效果不錯,車子帶藍芽轉FM,可以手機藍芽播放音樂,但經過幾次轉換以及對FM的質疑,所以懷疑音質是否會劇烈下降,抱著試試的態度放了一個手機上的音樂,結果感動的流淚了,為什麼以前手機帶的高保
啟用函式使用法則
sigmoid 、tanh 、ReLu tanh 函式或者雙曲正切函式是總體上都優於 sigmoid 函式的啟用函式。 基本已經不用 sigmoid 啟用函數了,tanh 函式在所有場合都優於 sigmoid 函式。 但有一個例外:在二分類的問題中,對於輸出層,因為y的值是 0 或 1,所
tensorflow中常用的啟用函式
啟用函式(activation function)執行時啟用神經網路中某一部分神經元,將啟用神經元的資訊輸入到下一層神經網路中。神經網路之所以能處理非線性問題,這歸功於啟用函式的非線性表達能力。啟用函式需要滿足資料的輸入和輸出都是可微的,因為在進行反向傳播的時候,需要對啟用函式求導。 在Te
神經網路常用啟用函式對比 sigmoid VS sofmax(附python原始碼)
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
深度學習幾種主流啟用函式總結
啟用函式的定義 加拿大蒙特利爾大學的Bengio教授在 ICML 2016 的文章[1]中給出了啟用函式的定義:啟用函式是對映 h:R→R,且幾乎處處可導。 啟用函式的性質 非線性: 當啟用函式是線性的時候,一個兩層的神經網路就可以逼近基本上所有的函數了。但是,如果啟
啟用函式 損失函式 優化器
均方差損失函式+Sigmoid的反向傳播演算法中,每一層向前遞推都要乘以σ′(z)(啟用函式的導數),得到梯度變化值。Sigmoid的這個曲線意味著在大多數時候,我們的梯度變化值很小,導致我們的W,b更新到極值的速度較慢,也就是我們的演算法收斂速度較慢。 使用交叉熵損失函式,得到的梯度表示式沒有
mxnet-Activation啟用函式
支援以下啟用函式: relu: Rectified Linear Unit, y=max(x,0)y=max(x,0)sigmoid: y=11+exp(−x)y=11+exp(−x)tanh: Hyperbolic tangent, y=exp(x)−exp(−x)exp(x)+exp(−x)y=exp(
啟用函式-Sigmoid, Tanh及ReLU
什麼是啟用函式 在神經網路中,我們會對所有的輸入進行加權求和,之後我們會在對結果施加一個函式,這個函式就是我們所說的啟用函式。如下圖所示。 為什麼使用啟用函式 我們使用啟用函式並不是真的啟用什麼,這只是一個抽象概念,使用啟用函式時為了讓中間輸出多樣化,能夠處理更復
形象的解釋神經網路啟用函式的作用是什麼
轉載自 形象的解釋神經網路啟用函式的作用是什麼 神經網路中啟用函式的作用 查閱資料和學習,大家對神經網路中啟用函式的作用主要集中下面這個觀點: 啟用函式是用來加入非線性因素的,解決性模型所不能解決的問題。 下面我分別從這個方面通過例子給出自己的理解~ @le
深度學習基礎--loss與啟用函式--廣義線性模型與各種各樣的啟用函式(配圖)
廣義線性模型是怎被應用在深度學習中? 深度學習從統計學角度,可以看做遞迴的廣義線性模型。廣義線性模型相對於經典的線性模型(y=wx+b),核心在於引入了連線函式g(.),形式變為:y=g(wx+b)。 深度學習時遞迴的廣義線性模型,神經元的啟用函式,即為廣義線性模型的連結函式
深度學習基礎--loss與啟用函式--Relu的變種
Relu的變種 softplus/softrelu softplus 是對 ReLU 的平滑逼近的解析函式形式。 softplus的公式: f(x)=ln(1+e^x) Relu與PRelu ai是增加的引數,ai=0;為ReLU,若ai取很小的固定值,則為
深度學習基礎--loss與啟用函式--Relu(Rectified Linear Units)
ReLu(Rectified Linear Units),即修正線性單元 它是不飽和的、線性的函式。可以認為是一種特殊的maxout。 Relu的優點 1)採用sigmoid和tanh等函式,算啟用函式時(指數運算),計算量大,反向傳播求誤差梯度時,求導涉及除法,計算量相