
如何突破汽車之家的"CSS ::before 偽元素混淆"反採集策略
如何突破汽車之家的"CSS ::before 偽元素混淆"反採集策略
釋出時間:2018-08-28 來源:未知 瀏覽:
http://www.site-digger.com/html/articles/20180828/663.html
分析汽車之家車型引數列表,發現頁面上有部分字元在HTML原始碼(執行時)中卻找不到,很奇怪。仔細分析,原來是通過CSS :before 偽元素加了混淆,如下圖示例:
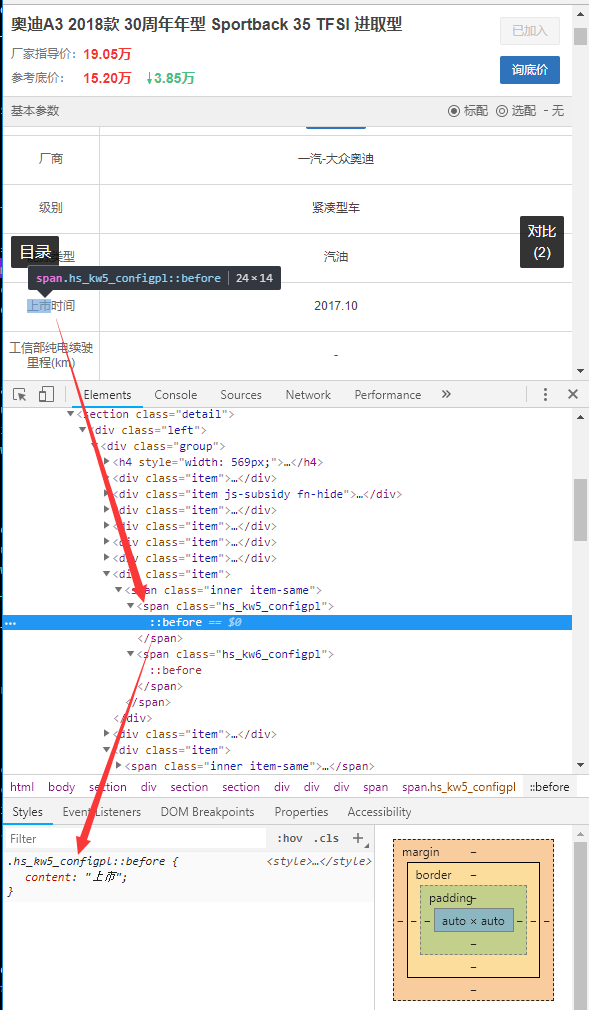
核心程式碼如下所示:
view plaincopy to clipboardprint?
- HTML程式碼:
- CSS程式碼:
- .hs_kw5_configpl::before {
- content: "上市";
- }
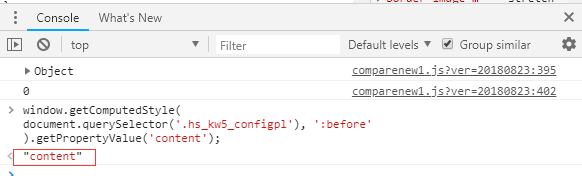
熟悉DOM操作的同學知道,可以通過元素的getPropertyValue('content')方法來獲取CSS偽元素的content屬性,如下是示例程式碼:
view plaincopy to clipboardprint?
- window.getComputedStyle(
- document.querySelector('.hs_kw5_configpl'), ':before'
- ).getPropertyValue('content');
在Console裡測試一下,你會發現很奇怪,竟然獲取不到有效值(如下圖所示),本應該返回"上市",卻返回了"content"。
看來哪裡又被動了手腳,TA是怎麼做到的?
仔細分析發現一個路徑包含GetModelConfig1.ashx的Aajx應答資料裡含有JS程式碼,分析程式碼發現該上述SPAN元素是JS動態建立的,並發現相關可疑程式碼,如下所示(格式化後):
view plaincopy to clipboardprint?
- function(element, pseudoElt) {
- if (pseudoElt != undefined && typeof(pseudoElt) == 'string' && pseudoElt.toLowerCase().indexOf(':before') > -1) {
- var obj = {};
- // 重點是下面這句
- obj.getPropertyValue = function(x) {
- return x;
- };
- return obj;
- } else {
- return window.hs_fuckyou(element, pseudoElt);
- }
- };
原來是getPropertyValue()方法被偷樑換柱(改寫)了!難怪呼叫無法獲取預期的值。
繼續分析JS程式碼,重點看SPAN元素的動態建立的過程,其中有如下程式碼:
view plaincopy to clipboardprint?
- function poL_(ctw_, RXe_) {
- tPn_[\u0027\u0027 + ILC_ + iSW_ + uIo_ + pEA_ + GEv_ + Ewc_ + EPk_ + Zfo_ + sfd_ + UkX_](XZS_(ctw_) + URD_() + \u0027\"\u0027 + RXe_ + \u0027\" }\u0027, 0);
- // 可以將\u0027替換成'
通過多次攔截應答修改資料(例如,修改為如下程式碼)測試發現,該函式的第二個引數Rxe_即為::before偽元素的content屬性值,第一個引數是一個索引。
view plaincopy to clipboardprint?
- function poL_(ctw_, RXe_) {
- // 看看ctw_和Rxe_引數具體是什麼
- console.log(ctw_ + '->' + RXe_));
- tPn_[\u0027\u0027 + ILC_ + iSW_ + uIo_ + pEA_ + GEv_ + Ewc_ + EPk_ + Zfo_ + sfd_ + UkX_](XZS_(ctw_) + URD_() + \u0027\"\u0027 + RXe_ + \u0027\" }\u0027, 0);
PS:攔截修改HTTP應答資料可以用Fiddler實現,也可以用mitmproxy,這裡我們選擇後者,因為它支援外掛Python指令碼來實現資料修改功能。
如下圖所示為控制檯打印出的"索引->字元"對映表:
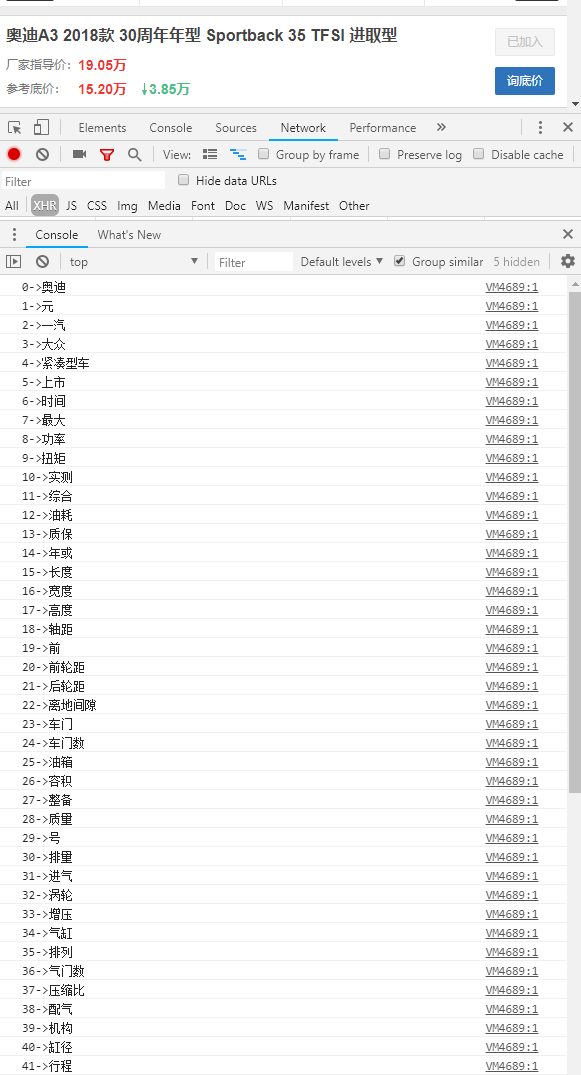
現在離成功很近了。這個索引數字具體有什麼意義呢?
例如,“上市”的索引為5,上面我們看到“上市”對應SPAN元素是 ,大膽猜測,對應的就是class中的數字5。經多次驗證,無誤。
現在思路有了:
(1)通過Selenium載入頁面(以自動完成資料動態載入,自動執行JS程式碼),並配置所有流量走mitmproxy;
(2)使用mitmproxy捕獲GetModelConfig1.ashx的應答資料,找到poL_(ctw_, RXe_)函式,注入我們的JS程式碼,以曝出對應的"索引和混淆字元"對映表;
(3)利用該表即可還原混淆為明文;
需要注意的是,上述程式碼中的函式名(poL_)以及引數名(ctw_, RXe_)是動態變化的,但是經過多次觀察發現是有規律的,通過如下方法可以定位該函式:
view plaincopy to clipboardprint?
- 查詢如下字串:
- '+ \u0027\" }\u0027'
- 定位前面出現的第一個function,即要注入的目標
- 例如 function poL_(ctw_, RXe_)
- 用正則表示式可以表述為:
- r'''''\s+(function\s+[^\{\}\(\)]+\(([^\{\}\(\)]+),([^\{\}\(\)]+)\)\{)[a-z\d\-\_]+\_\[.+?\+\s*\\u0027\\"\s*\}\\u0027'''
程式碼自動注入這裡我們採用mitmproxy來實現,注入指令碼modify_response.py程式碼如下所示:
view plaincopy to clipboardprint?
- # coding: utf-8
- # modify_response.py
- import re
- from mitmproxy import ctx
- def response(flow):
- """修改應答資料
- """
- if 'GetModelConfig' in flow.request.url:
- # 汽車之家字元混淆(CSS :before 偽元素)破解
- ctx.log.info('*' * 120 + '\n Found {}.'.format(flow.request.url))
- m = re.compile(r'''''\s+(function\s+[^\{\}\(\)]+\(([^\{\}\(\)]+),([^\{\}\(\)]+)\)\{)[a-z\d\-\_]+\_\[.+?\+\s*\\u0027\\"\s*\}\\u0027''', re.IGNORECASE).search(flow.response.text)
- if m:
- # 提取函式名和引數
- function_name = m.groups()[0]
- param1 = m.groups()[1]
- param2 = m.groups()[2]
- ctx.log.info('Crack "CSS :before" in {}: "{}"'.format(function_name, flow.request.url))
- # 替換後的內容
- replacement = function_name + "document.body.appendChild(document.createTextNode('[' + {} + ']->{{' + {} + '}};'));".format(param1, param2)
- #replacement = function_name + "console.log({} + '->' + {});".format(param1, param2)
- flow.response.text = flow.response.text.replace(function_name, replacement)
注入成功,頁面載入完畢後,在頁面底部會打印出我們想要的對映表:
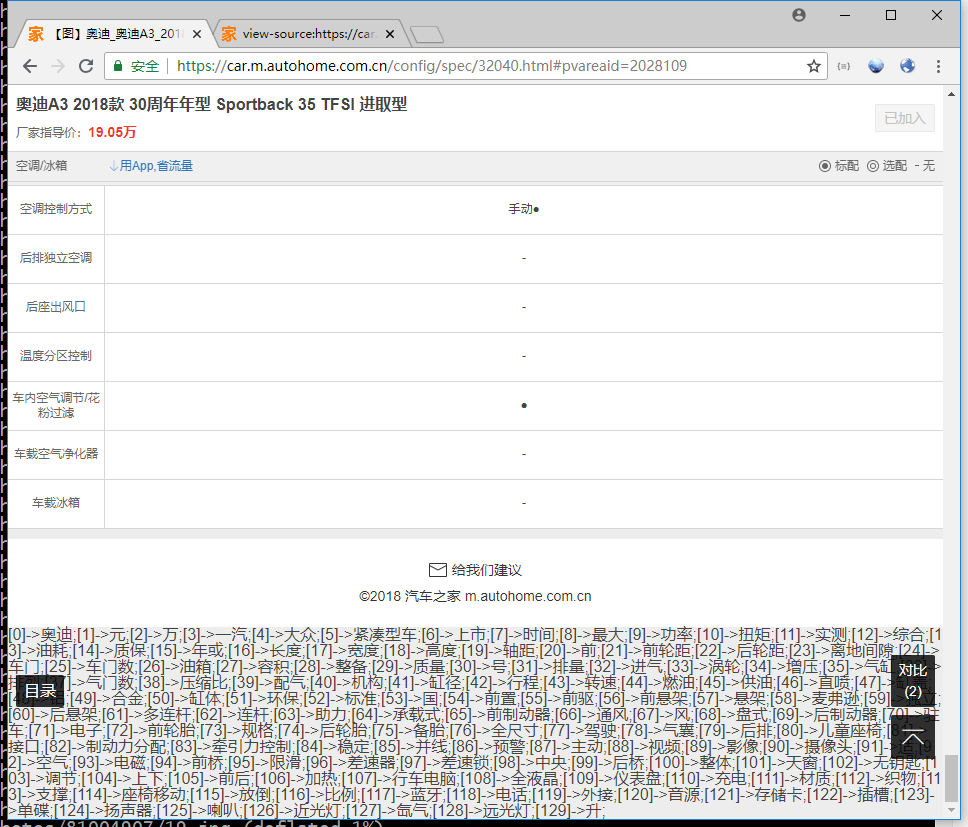
有了這個對映表,就可以還原出明文了,程式碼如下所示:
view plaincopy to clipboardprint?
- def restore_css_confusion(html):
- """還原混淆字元
- html - 要處理的HTML文件原始碼;
- """
- confusions = {}
- for index, string in re.compile(r'\[(\d+)\]->\{([^<>\;]+)\};').findall(html):
- confusions[index] = common.normalize(string)
- # 逐一替換
- for span, index in re.compile(r'()').findall(html):
- original_text = confusions[index]
- print 'Restore "{}" into "{}"'.format(span, original_text)
- html = html.replace(span, original_text)
- return html
還原之後就可以提取到正確的引數資訊了,如下圖所示:
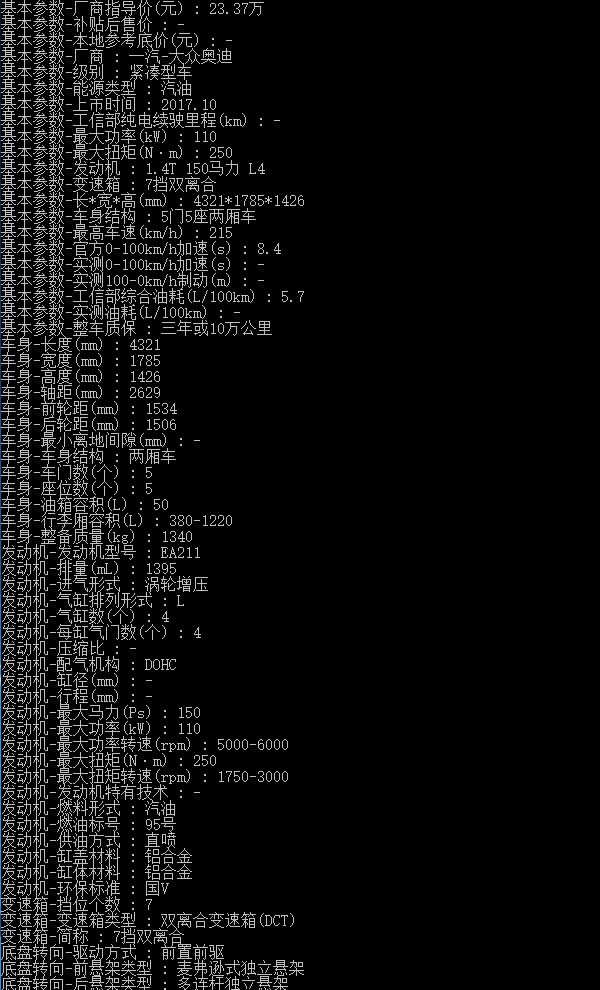
最後,這裡有個演示視訊,可以看到實際的執行過程:
https://v.qq.com/x/page/e07680qdz2r.html
特別說明:該文章為鯤鵬資料原創文章 ,您除了可以發表評論外,還可以轉載到別的網站,但是請保留源地址,謝謝!!(尊重他人勞動,我們共同努力)