
基於資料探勘的高校個性化學生管理方案研究——以A高校資料集為例(未發表,使用或引用前請提前告知)
基於資料探勘的高校個性化學生管理方案研究——以A高校資料集為例
馬 鑫
摘 要:高校資訊系統中儲存著大量產生頻率非常迅速且型別繁雜的資料,傳統的高校學生管理模式已很難適用於我國現階段高校學生管理。依據資料探勘演算法理論,採用k-prototypes聚類演算法代替傳統的人工貼標籤方式,為預處理後的資料新增標籤,並在此標籤資料的基礎之上,通過分類迴歸樹CART對不同學生進行分類類別特徵挖掘,概括不同類別學生特徵,結合學生管理經驗提出有針對性的學生管理建議。
關鍵詞:資料探勘;資料預處理;k-prototypes;資料標籤;CART;個性化學生管理
中圖分類號:D630.99 文獻標識碼
Research on individualized student management plan based on CART DECISION TREE:Taking a university data set as an example
Abstract: The university information system stores a large number of unstructured data with very rapid frequency. The traditional college student management model has been difficult to apply to the current student management in China. According to the data mining algorithm theory, the k-prototypes algorithm is used instead of the traditional manual labeling method to label the pre-processed data. Based on the label data, the classification and classification feature mining of different students is carried out by the classification regression tree CART. The paper further summarizes the characteristics of different categories of students, and puts forward targeted student management suggestions based on student management experience.
Key words: data mining; Data preprocessing; k-prototypes; Data tag; CART; Personalized student management
0 引 言
高校學生從入學、軍訓、生活到畢業等整個的活動週期,在學校的各個資訊系統如圖書館管理、教務考核、學生管理、超市管理、宿舍管理、體育管理、就醫管理以及學生檔案管理等諸多資訊系統中都會儲存下各種結構的歷史資料。然而,傳統的資訊系統不論是在施行效率還是資料應用等多方面已不能滿足當代學生管理的要求。發掘高校資料中的潛在價值,找到學生舉動之間的內在聯絡,思索這些舉動背後的邏輯關係,做出適當的管理決策,實現對高校學生個性化的管理顯得尤為迫切。
本文將資料探勘演算法應用於高校學生管理系統,充分利用資料探勘相關技術,從已知資訊系統中儲存的與學生有關的大量歷史資料著手,挖掘資料當中潛在的有用資訊,進而對學生進行分類,總結同一類別不同物件之間的共同特徵,根據學生同一類別的共有特徵針對性的制定個性化的學生管理方案,實現以人為本的差異化管理模式,輔助確立及時、周全的教學管理體系。以期望提高高校學生管理工作精細化水平,促進高校管理工作的科學性,為高校教務工作舔磚加瓦。
1 資料預處理
資料預處理欲解決的問題是將未進行任何加工的資料轉換成適合進行分析的形式,通常耗費大量的時間和精力,且需要人為經驗的干預,是資料探勘過程當中十分重要的一步[1]。在進行資料探勘之前,需要對原始資料進行抽取、簡化、清洗和轉換等操作,提高資料探勘結果的準確度。
1.1 資料抽取
資料抽取是指從原始資料中目標資料來源體系必要的資料。現實當中,資料抽取主要是從關係型資料庫中抽取,包括:增量抽取和全量抽取兩種方式。本文為儘可能保留原始資料,採用增量抽取的方式進行抽取,將A校資訊系統中的資料原封不動的抽取出來,最大限度的保留資料的“原貌”。
1.2 資料簡化
本文研究的主要目的是對學生進行分類管理,對於student_guardian(監護人)、schoolsup(學校中額外的教育支出)、famsup(家庭中額外的教育支出)、paid(課程內的額外付費課程)、nursery(是否就讀過託兒所)、romantic(是否戀愛)、famrel(家庭關係質量)、freetime(課後空閒時間)、Dalc(上課期間飲酒)、Walc(週末飲酒)等與目的無關或者主觀性較大對挖掘結果造成影響的屬性進行刪除操作。
1.3 資料清洗
|
|||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||
|
資料清洗的目標是為之後的資料探勘提供完備有用正確的資料,提高資料探勘的效率[2]。相反,資料清洗不完善,結果也會存在諸多誤差。本文所用資料為資料庫中匯出資料,此中存在少量的缺失資料、錯誤的資料和重複資料。
缺失型資料主要集中在travel_time(空閒時間)、medu(母親學歷水平)以及fedu(父親學歷水平)等屬性值。本文采用插補法方式對缺失值進行處理,medu等定距型別資料通過計算均值進行插補,travel_time等非定距型別資料通過統計頻數進行插補[3]。例如:medu的取值型別有四種1、2、3、4,缺失值則為該屬性存在值的平均值2.5;travel_time當中通過統計發現空閒時間為1小時的頻率最高,則空缺位置的值填補為1。而重複型資料和同一屬性取值形式不同的錯誤型資料,本文的處理方式是通過SQL語句在資料庫中進行相應處理。
1.4 資料轉換
構造和新增index(物件編號)和G3(G1和G2兩學期的平均成績)兩個新的屬性,以使得資料更易於進行資料探勘,提高挖掘精度和高緯資料結構的理解[4]。
2 資料標籤的張貼
傳統的資料標籤張貼方式主要有自貼標籤、專家貼標籤和“羊毛出在豬身上(藉助某種客戶端通過使用者來實現)”等方式。然而,這些方式不但費時費力,而且在應用場景中也有諸多限制,例如:“羊毛出在豬身上”這種標籤張貼方式,不僅要求具備一個相應的客戶端,同時該客戶端需要具備一定基數的使用者[5]。
而本文則採用聚類的方式為每一個數據物件貼標籤。比較常見的聚類分析演算法所對應的資料型別主要包括數值資料、分類資料和混合型資料。k-prototypes演算法綜合了k-means演算法和k-modes演算法優點,採用一種嶄新的距離計算公式,能夠快速的處理混合資料集的聚類分析問題[6]。類似於k-means演算法當中的誤差平方和(SSE),k-prototypes演算法設定了一個最優函式,簇中心不斷進行迭代,直到目標函式值不發生變化。目標函式為:
E=l=1ki=1nuildxi,Ql (1)
上式中uil可理解為第i個物件分類屬性的權重,Ql可理解為當前迭代中的簇中心,xi為樣本中物件,n表示樣本中物件的個數,j表示物件的維數。
2.1 演算法設計
設X=X1,X2,X3,…,Xn表示學生表現資料集中n個學生物件(n=1, 2, 3, …, 395),在這其中Xi表示一個具有屬性A1,A2,A3,…,Am的學生資料物件(m=1,2,3,…,23)。對於數值型屬性值,採用連續型的值進行表示,分型別的屬性值採用有限且無任何順序的值的集合進行表示,即使用DomAj=aj1,aj2,…,ajt對分類屬性取值進行表示,其中t為Aj的可能取值的個數。綜上所述Xi可表示為常見的向量的形式[xi1,xi2,…,xim]。
設k為一個正整數,表示k-prototypes演算法需要將源資料集X聚類為k個簇,也即選擇k個初始聚類中心。該聚類演算法的聚類準則為最小化目標函式:
EY,Q=l=1ki=1nyildxi,Ql (2)
上式中dXi,Ql為差異度,其可定義如下:
dXi,Ql=j=1mdxij,qlj (3)
其中dxij,qlj的取值又可分為:
dxij,qlj=xijr-qljr2 ,m=rγlδxijc,qljc , m=c (4)
上式當中xijr和qljr為數值屬性,xijc和qljc為分類屬性,r和c分別為數值變數和分類變數的個數。同時,通過計算可以發現,當xijc=qljc時,δxijc,qljc的值為0,反之則δxijc,qljc為1;其中需要重點說明的是γl為混合資料型別當中分類屬性的權重,分類屬性相對重要,權重值則大;分類屬性相比於輸指數型不是那麼重要,權重則小。當xij為數值屬性時,qlj代表的是第l個簇中第j個屬性的均值;當xij是分類屬性時,qlj代表的是第l個簇中第j個屬性的對應模式。
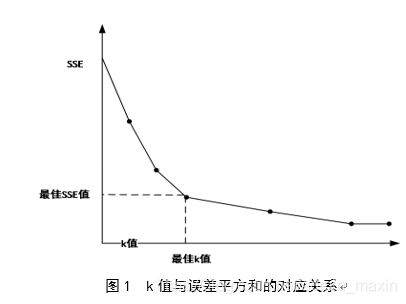
2.2 k值的選擇
聚類結果在很大程度上取決於k值的選擇,k值過大或過小都會對聚類結果產生巨大的影響。本文采取手肘法確定k的取值。該方法的核心思想是隨著初始聚類書k的輸入不斷增大,樣本資料的分類精細度會不斷提高,也即簇的聚類程度不斷提高,SSE逐漸減小。而且,當k小於樣本資料真實的聚類數時,隨著k數值的增長會大幅度的增加各個簇的聚合程度,SSE降低的幅度增大;當k在樣本真實的聚類數週邊浮動時,隨著k的增加,聚合程度的回報會銳減,後隨著k值輸入的增大麴線逐漸變得平緩。
因而,SSE和k的干係圖為手肘狀的外形,手肘狀的頂點對應的k值則為學生資料對應的真實聚類數。手肘法的主要判斷依據是SSE(誤差平方和):
SSE=i=1kp∈cip-mi2 (5)
上式中,ci表示第i個簇,p為簇ci中的樣本,mi是ci的質心(ci中整個樣本的均值),SSE也可代表全部樣本的聚類偏差,代表了聚類結果的好壞。
mi=1nij=1nipj (6)
此中ni表示第i個簇中樣本的個數,pj表示第i個簇中樣本物件的個數。在某個簇ci質心的計算過程中,數值型資料直接求均值,分型別資料則通過頻數的方式確定質心對應屬性的屬性值;分型屬性做差時,屬性值相同為0,不同為1。
2.3 聚類結果展示
通過迴圈遞增設定k值,為每一個聚類結果計算一個誤差平方和SSE,通過比較發現當k=6時聚類結果的反饋程度最高,也即k=6為聚類最佳k值。k-prototypes演算法的最終聚類結果如圖2,該演算法將本科生資料樣本分為6個簇,每個簇對應的比例分別為22.8%,22.5%,15.7%,14.4%,13.7%,10.9%,最小與最大簇之間的比值為2.09。

3 基於CART的分類特徵挖掘
單從聚類結果的視覺化資料當中很難找到某些確切的描述同一類別不同學生物件的共有特徵,因此本文采用分類迴歸樹CART決策樹對其進行特徵挖掘,選擇決策樹構建較為重要的前幾個特徵對不同學生類別進行描述,進而提出個性化的學生管理方案。
3.1 分類尺度確定
在決策樹當中有一個重要性程度非常高的問題,那就是如何選擇原始資料集當中哪一個特徵在劃分資料分類時起到相對重要的作用,即“樹”在“分叉”時應該參照什麼屬性進行“分叉”。本文采用CART(分類及迴歸樹),該演算法選取劃分資料的特徵時不同於傳統的ID3以及C4.5等決策樹演算法採取資訊熵來劃分資料集,至於如何分割,則由目的變數的型別決定。假設是分類變數,Gini或Twoing任意選擇,若為連續變數(數值),則自動確定方差來選擇分割點[7]。本文分類變數選用Gini係數確定分類尺度。
Gini係數[8]計算公式如下:
Gt=1-t1T2-t2T2-…-tnT2 (7)
上式中,t1,t2,…,tn代表每個類別的記錄數,T為總記錄數,本文資料中即樣本總量(理論上來說)。在CART演算法當中,採用Gini係數的減少量來確定當前節點的分裂標準:
∆Gt=Gt-n1N*Gt1-n2N*Gt2 (8)
其中,n1為左子樹的記錄數,n2為右子樹的記錄數,N=n1+n2。另外,由於CART演算法僅能建立二叉樹,則對於分類多與兩種的類別,首先需要先將多於的類別值合併為兩個,進而形成超類,然後計算∆Gt。以上的Gini係數是針對分型別變數,而針對連續型變數,必須首先將連續型變數升序排列,分別以相鄰兩個數值型資料的中心值作為分支尺度,分別計算左右子樹的∆Gt。
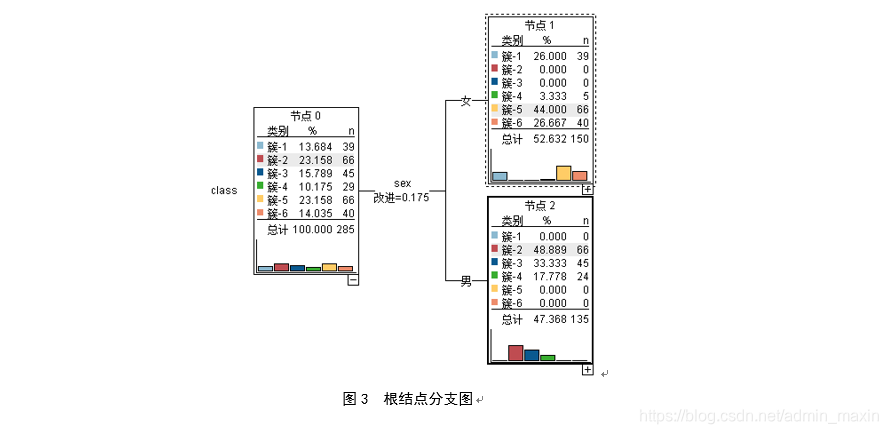
以根結點的劃分為例:第一步,計算全部資料的差異度Gt=1-392852-…-402852=0.819034,Gt1=0.666578,Gt2=0.618272;第二步,計算根結點以特徵sex(男or女)劃分後的∆Gt,∆Gt=0.8190-150/(285*0.6667)-135/(285*0.6183)≈0.175;第三步,遍歷資料集所有屬性及其對應的屬性值,計算出一系的∆Gt,最大的∆Gt對應的屬性和屬性值則為最佳分割點。
3.2 分類特徵挖掘
通過最終的決策樹視覺化結果分析,sex(學生性別)、activities(是否參加活動)、choose_reason(擇校原因)、medu(母親受教育程度)四個屬效能夠更加迅速的構建決策樹,且對決策樹的影響程度依次下降。需要特別指出的是,圖4中的“改進=0.175”指的是最佳分割點所對應的∆Gt。

4 特徵描述與管理方案研究
4.1 “天才型”學生
針對簇2,本文稱之為天才型學生。此類學生一般為男生、喜歡參加課外各種活動、擇校原因多為學校名氣、父母受教育程度高且多為大學及以上學歷、城鎮戶口、宿舍中有上網裝置以及成績優秀等共同特徵。針對此類學生,本文給出以下管理建議:
(1)善於引導
老師或者學校教學管理人員可為此類同學提供一些幫扶平臺,讓其能幫扶其他同學,這樣既可以給這類學生自信,又能給他們提供一份責任,傳播自己的各方面的成功經驗。
(2)懂得寬容
此類學生由於各方面能力出眾,父母疼愛,在自主能力和辨別能力上會有所欠缺,作為老師或學校教學管理人員應多一些寬容,培養這類學生自主安排學習和各方面實物的能力,畢竟知錯能改善莫大焉。
(3)培養寬鬆的師生關係
在這類學生的管理過程中,不管是老師還是其他的教學管理人員,都應該提升自己的創造力、想象力和創新性,在學生心目當中樹立亦師亦友的個人形象。
4.2 “自我否定型”學生
針對簇4,本文稱之為“自我否定型”學生。此類學生大多數為平時不愛參加課外活動、選擇某個學校看中的則是課程情況、父母受教育程度低、農村戶口、家庭條件較差、宿舍無上網裝置、成績極差的男生(佔比84%)。此類學生受到家庭對於教育觀念的曲解,其對學習有一種抵觸情緒,年齡相對於同一級的學生來說偏大,生活相對拮据;對外界缺乏一些瞭解的渠道(網際網路),過分的貶低自身的能力,是老師的“眼中釘,肉中刺”。針對這一類學生,本文給出以下管理建議:
(1)真誠的關心
這一類學生由於從小受到生活條件和家庭觀念等的約束,不能正確的認識自己的能力,過分的自卑,從小接觸的教學資源不足,學習能力較低,作為老師和教學管理人員應當為他們提供一個展示風采的平臺,引導其樹立起強大的自信心,幫助其逐漸建立起對學習的興趣。
(2)善於發現閃光點,並實時的給與讚賞[9]
逐漸的改變其對學習的認識,充當其與外界聯絡的“媒介”。
4.3 “理工型”學生
針對簇3,本文稱之為“理工型”學生。此類學生,一般為平時不愛參加活動、擇校主要是聽從家人的安排、父母受教育程度高、城鎮戶口、宿舍有固定上網裝置且成績較為優秀的男生。這個群體的學生被認為是“宅而木訥”但智商超高的一群人,喜歡挑戰電腦遊戲,狂熱於電子產品,缺少人際交往的一些必備常識(不願參加一些課外活動)。通過與“天才型”學生對比發現,該類學生課下花在學習上的時間更少,但成績卻出乎預料的好,微低於“天才型”學生。針對這一類學生,本文給出以下管理建議:
(1)學習之餘多體貼學生生活
此類學生雖然智商超高,但是生活不休邊幅,呆板無趣,影響他們的不是學習有多困難,而是怎樣與他人溝通交流。作為老師或學校的管理人員應多關心他們的生活,幫助其樹立正確的價值觀,處理好電子遊戲與學習之間的關係,防止該型別學生向更加糟糕的情況轉化,因為高校中因為遊戲而引發的留級和輟學時間屢見不鮮。
(2)激勵引導其多與外界接觸
幾天甚至幾周都不出宿舍不下床的高校學生大有人在,這不僅不利於學生自身的健康,人際關係的營造,也不利於學生的學習和自我提高。因而,老師和學校的相干管理人員都應當展開一些有利於學生之間彼此溝通和交流的活動,豐富該類學生的空閒生活,轉變其“電腦,宿舍,遊戲足以!”的思想觀念,全身心的投入到學習生活當中。
4.4 “勤奮自覺型”學生
針對簇1,本文稱之為“勤奮自覺型”學生。此類學生多為平時不願參加活動、擇校主要是衝著學校課程安排、父母學歷較高、城鎮戶口、宿舍有固定上網裝置、成績較低的女生。此類學生家庭條件良好,雖就智商來說可能不及“理工型”或“天才型”學生,但是卻認真刻苦,懂得“知識改變命運”的思想,能自覺維護上課紀律,在課堂上能與老師進行良性交流,能充分利用課下時間進行學習,懂得勞逸結合,日復一日的匆匆穿梭於宿舍和教室之間。針對這一類學生,本文給出以下建議:
(1)在該類學生當中樹立一種勤奮上進的形象
這一類學生由於勤奮上進,大把時間用來學習,以至於在一部分學生眼中她們是另類。這個時候老師和學校的相關管理人員應以身作則,勤奮是一種優秀的品質,樹立起身邊的榜樣。
(2)及時解答學習上的困惑
該類學生勤奮好學,能夠合理的安排自己的學生和生活,日常生活當中學習是其“主戰場”,而最令其頭疼的問題則是“這個地方實在是想不出來”“這種問題我應該怎麼考慮”“我應該從什麼角度入手”“從哪裡開始學習”等問題,這個時候學校相關管理人員或老師則應及時的為其解答疑難困惑,不定期開展一些學習經驗交流會,為其分享相關的學習經驗。
4.5 “學習方法欠佳型”學生
針對簇5,本文稱之為“學習方法欠佳型”學生。這一類學生多為空餘時間積極參加課外活動、擇校主要考慮的是學校名氣、父母學歷較高、城鎮戶口且家庭條件良好的女生(單親家庭佔比6.7%)。此類學生學習認真刻苦,有非常高的學習慾望,積極參加各類活動,渴望成為全能型學生,但成績總不理想,變化波動較大。針對這一類學生本文給出如下建議:
(1)授人以漁
這一類學生學習態度端正,對知識的渴求之高常人無法想象,但學習方法欠佳。老師或學校教學管理人員可充分發揮“天才型”學生的作用,開展一對一幫扶,逐漸的幫助這一類學生找到正確的學習方法。
(2)努力沒有錯,錯在方法
這一類學生花費在學習上的時間非常多,但效果幾乎為0,因此其開始懷疑自己的能力,懷疑自己是不是比別人笨,更嚴重的甚至有開始厭學的傾向,情況之嚴重應當引起足夠的重視。作為老師,可以多體貼這類學生,輔助他們找到合適自身的學習方法;作為學校教學管理人員,可以開展一些心理講座之類的活動,幫助有認識問題的學生走出誤區。
4.6 “偏執型”學生
針對簇6,本文稱之為“偏執型”學生。這一類學生多為平時不願參加活動、擇校主要聽從家人安排、父母雙方學歷較高、城鎮戶口、宿舍有固定上網裝置、成績良好且家庭條件優越的女生(單親家庭佔比20.4%)。此類學生及其富有主見,不愛學習,認為學習無用,經常曠課,一有空閒時間就用來“豐富自我”,經常去圖書館看一些小說之類的書籍,追劇等。她們高度自信,認為學習無用不如通過其他方式提高自己。這一類學生主要受教育功利性觀點的影響,認為教育的投入與產出不對等,覺得就算大學畢業也不好就業,就算就業了工資也不高,所以他們認為學習無用。這部分本科生的學習目的非常的膚淺,學習完全是被動的,其學習方式以應付為主,普遍認為無所謂,學習效率低下。針對這一類學生,本文提出以下建議:
(1)施壓
對學生不作為的舉動直接進行點名指責,或公開做反省。
(2)逼迫其直麵人生
作為老師,課堂上可以偶爾分享一些長期抱有學習無用態度且多年後一事無成得不到別人尊重的人的反例;作為學校教學管理人員,則可對這一類學生進行抽查點名,定期通報等方式,催促他們學習。
(3)規劃人生。
這個工作完全可以通過學校開設的相關課程進行講解,比如《大學生生涯規劃》等課程。
5 總結
將資料探勘引入高校資訊系統是現階段高校學生管理的發展趨勢[10-12]。本文從高校教務管理資訊系統中的歷史資料出發,在預處理資料的基礎之上,採用手肘法確定聚類最佳k值,進而通過聚類演算法k-prototypes演算法替換傳統的標籤張貼方式為每一資料物件新增標籤(省時省力,且準確性高);並應用分類迴歸樹CART演算法挖掘不同標籤之間的特有特徵,對同一標籤中不同物件之間的共有特徵做出精確描述,進而針對每一標籤提出針對性的個性化管理建議。
本文通過挖掘高校資訊系統中的資料,將資料轉化為知識,可以促進高校學生管理工作的提升,在構建符合現代高校學生教務管理新模式,全面提升學生培養質量方面具有一定的參考價值。
[參考文獻]
[1]黃航輝. 網際網路訪問資料預處理研究與應用[D].東華大學,2014.
[2]董瀟瀟,胡延,陳彥萍. 基於校園資料的大學生行為畫像研究與分析[J]. 計算機與數字工程,2018,46(06):1200-1204+1262.
[3]楊帆,龐新生. 處理缺失資料的分數插補法研究[J]. 統計與決策,2017(14):15-18.
[4]馮柳偉. 基於近鄰的聚類演算法研究[D].北京交通大學,2018.
[5]Ti S U, Yang M, Wang C X, et al. Classification and Regression Tree Based Traffic Merging for Method Self-driving Vehicles[J]. Acta Automatica Sinica, 2018.
[6]徐健. 基於改進型K-prototypes演算法的雲服務推薦研究[D].合肥工業大學,2017.
[7]李亞芳. K-means型社群發現方法研究[D].北京交通大學,2017.
[8]Ti S U, Yang M, Wang C X, et al. Classification and Regression Tree Based Traffic Merging for Method Self-driving Vehicles[J]. Acta Automatica Sinica, 2018.
[9]譚凱茵. 教育要滋潤學生的心田[J]. 讀與寫(教育教學刊),2018,15(05):177.
[10]葛璐瑤.改進的決策樹ID3演算法及應用[J/OL]. 電子技術與軟體工程,2018(13):153-154[2018-07-23].http://kns.cnki.net/kcms/detail/10.1108.TP.20180710.0913.212.html.
[11] Choubin B, Zehtabian G, Azareh A, et al. Precipitation forecasting using classification and regression trees (CART) model: a comparative study of different approaches[J]. Environmental Earth Sciences, 2018, 77(8):314.
[12]柯玲. 高校教務管理資訊化和科學化建設的思考[J]. 資訊科技與資訊化,2018(Z1):171-173.