
The 10 coolest papers from CVPR 2018
The 2018 Conference on Computer Vision and Pattern Recognition (CVPR) took place last week in Salt Lake City, USA. It’s the world’s top conference in the field of computer vision. This year, CVPR received 3,300 main conference paper submissions and accepted 979. Over 6,500 attended the conference and boy was it epic! 6500 people were packed into this room:

CVPR 2018 Grand Ballroom
Every year, CVPR brings in great people and their great research; there’s always something new to see and learn. Of course, there’s always those papers that publish new ground breaking results and bring in some great new knowledge into the field. These papers often shape the new state-of-the-art across many of the sub-domains of computer vision.
Lately though, what’s been really fun to see is those out-of-the-box and creative papers! With this fairly recent rush of deep learning in computer vision, we’re still discovering all the possibilities. Many papers will present totally new applications of deep networks in vision. They may not be the most fundamentally ground-breaking works, but they’re fun to see and offer a creative and enlightening perspective to the field, often sparking new ideas from the new angle they present. All in all, they’re pretty cool!
Here, I’m going to show you what I thought were the 10 coolest papers at CVPR 2018. We’ll see new applications that have only recently been made possible by using deep networks, and others that offer a new twist on how to use them. You might just pick up some new ideas yourself along the way ;). Without further adieu, let’s dive in!
Training Deep Networks with Synthetic Data: Bridging the Reality Gap by Domain Randomization
This paper comes from Nvidia and goes full throttle on using synthetic data to train Convolutional Neural Networks (CNNs). They created a plugin for Unreal Engine 4 which will generate synthetic training data. The real key is that they randomize many of the variables that training data can have including:
- number and types of objects
- number, types, colors, and scales of distractors
- texture on the object of interest, and background photograph
- location of the virtual camera with respect to the scene
- angle of the camera with respect to the scene
- number and locations of point lights
They showed some pretty promising results that demonstrate the effectiveness of pre-training with synthetic data; a result that previously has not been achieved. It may shed some light on how to go about generating and using synthetic data if you’re short on that important resource.
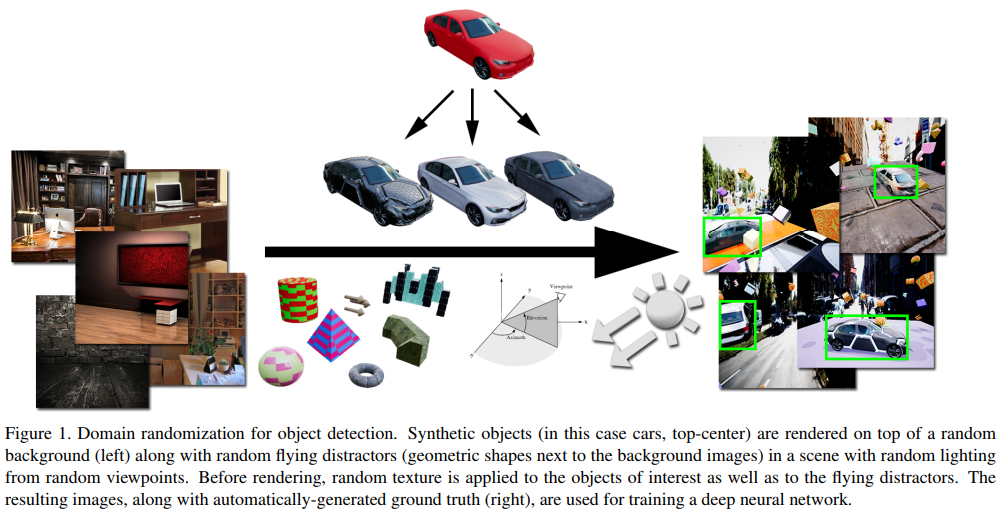
Figure from the paper: Training Deep Networks with Synthetic Data: Bridging the Reality Gap by Domain Randomization
WESPE: Weakly Supervised Photo Enhancer for Digital Cameras
This one’s clever! They train a Generative Adversarial Network (GAN) to automatically aesthetically enhance photographs. The cool part is that it is weakly supervised; you don’t need input-output image pairs! All you need to train the network is a set of “good” looking images (for the output ground truth) and a set of “bad” looking images that you want to enhance (for the input images). The GAN is then trained to generate an aesthetically enhancing version of the input, often greatly enhancing the color and contrast of the image.
It’s quick and easy to use because you don’t need exact pairs of images, and you end up with a “generic” image enhancer at the end. I also like that it’s a weakly supervised approach. Unsupervised learning seems quite far away. But for many sub-domains in computer vision, weak supervision seems like a promising and profitable direction.

Figure from the paper: WESPE: Weakly Supervised Photo Enhancer for Digital Cameras
Efficient Interactive Annotation of Segmentation Datasets with Polygon-RNN++
One of the main reasons deep networks work so well is the availability of large and fully annotated datasets. For many computer vision tasks however, such data is both time consuming and expensive to acquire. In particular, segmentation data requires the class labeling of each and every pixel in the images. As you can imagine….. this can take forever for big datasets!
Polygon-RNN++ allows you to set rough polygon points around each object in the image, and then the network will automatically generate the segmentation annotation! The paper shows that this method actually generalizes quite well and can be used to create quick and easy annotations for segmentation tasks!

Figure from the paper: Efficient Interactive Annotation of Segmentation Datasets with Polygon-RNN++
Creating Capsule Wardrobes from Fashion Images
Hhmmm what should I wear today? Wouldn’t it be great if someone or something could answer that question for you each morning, so that you wouldn’t have to? Well then say hello to Capsule Wardrobes!
In this paper, the authors design a model that, given an inventory of candidate garments and accessories, can assemble a minimal set of items that provides maximal mix-and-match outfits. It’s basically trained using objective functions that are designed to capture the key ingredients of visual compatibility, versatility, and user-specific preference. With wardrobe capsules, it’s easy to get the best looking outfit that fits your taste from your wardrobe!

Figure from the paper: Creating Capsule Wardrobes from Fashion Images
Super SloMo: High Quality Estimation of Multiple Intermediate Frames for Video Interpolation
Ever wanted to film something super cool, in super slow motion? Well then look no further than Super SloMo from Nvdia! Their CNN estimates intermediate video frames and is capable of transforming standard 30fps videos into awesome looking slow motion at 240fps! The model estimates the optical flow between frames and uses it to cleanly interpolate video frames so that the slow motion video looks crisp and sharp.

A bullet going through an egg, super SloMo!
Who Let The Dogs Out? Modeling Dog Behavior From Visual Data
Probably the coolest research paper name ever! The idea here was to try and model the thoughts and actions of a dog. The authors attach a number of sensors to the dog’s limbs to collect data for its movement; they also attach a camera to the dog’s head to get the same first-person view of the world that the dog does. A set of CNN feature extractors are used to get image features from the video frames, which are then passed to a set of LSTMs along with the sensor data to learn and predict the dog’s actions. The very new and creative application, along with the unique way the task was framed and carried out make this paper an awesome read! Hopefully, it can inspire future research creativity with the way we collect data and apply deep learning techniques.
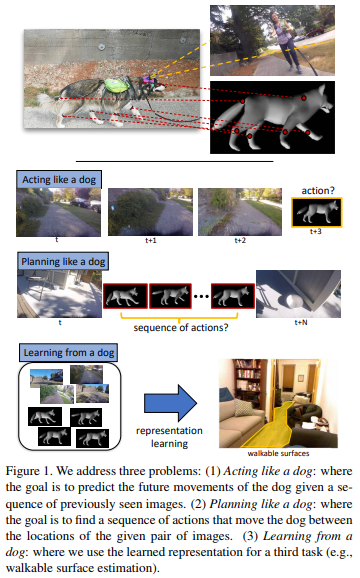
Figure from the paper: Who Let The Dogs Out? Modeling Dog Behavior From Visual Data
Learning to Segment Every Thing
There’s been a lot of great computer vision research coming from Kaiming He’s group (previously at Microsoft Research, now at Facebook AI Research) over the last few years. What’s been great about their papers is the combination of creativity and simplicity. Both ResNets and Mask R-CNN weren’t the craziest or complex research ideas. They were simple and easy to implement, yet highly effective in practice. This one here is no different.
Learning to Segment Every Thing is an extension of the Mask R-CNN which gives the network the ability to segment objects from classes not seen during training! This is extremely useful for obtaining quick and cheap annotations for datasets. The fact that it can get some generally strong baseline segments of unseen object classes is critical for being able to deploy such segmentation networks in the wild since in such an environment there may be many unseen object classes. Overall, it’s definitely a step in the right direction of how we can think to get the most out of our deep network models.
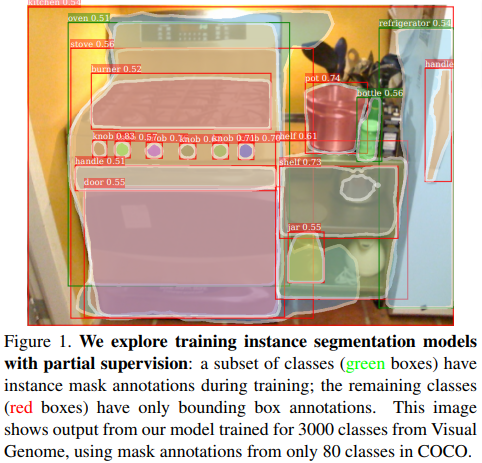
Figure from the paper: Learning to Segment Every Thing
This paper should win the award for best timing with it being publishing right when the FIFA World Cup is on! It really is one of the “cooler” applications of computer vision at CVPR. In a nutshell, the authors trained a model that, given a video of a soccer game, can output a dynamic 3D reconstruction of that game. That means you can then view it anywhere using Augmented Reality!
The really clever part is the combined use of many different types of information. The network is trained using video game data from which the 3D meshes can fairly easily be extracted. At test time, the bounding boxes, poses, and trajectories (across multiple frames) of the players are extracted in order to segment the players. These 3D segments can then easily be projected onto any plane (in this case you can just make any virtual soccer field!) for watching a soccer game in AR! In my view, it’s sort of a clever way of using synthetic data for training. Either way it’s a fun application!

Figure from the paper: Soccer on Your Tabletop
LayoutNet: Reconstructing the 3D Room Layout from a Single RGB Image
This one is a computer vision application that many of us have likely thought of at one time or another: use a camera to take a picture of something, and then reconstruct that thing in digital 3D. That’s exactly what this paper is going for, specifically for 3D reconstructing rooms. They use panorama images as input in order to get a full view of the room. The output is a 3D reconstructed room layout with fairly good accuracy! The model is powerful enough to generalize to rooms of different shapes and containing many different furniture items. It’s an interesting and fun application that you don’t see too many researchers working on in computer vision, so it’s nice to see.

Figure from the paper: LayoutNet: Reconstructing the 3D Room Layout from a Single RGB Image
Learning Transferable Architectures for Scalable Image Recognition
Last but not least is what many consider to be the future of deep learning: Neural Architecture Search (NAS). The basic idea behind NAS is that instead of manually designing the network architecture, we can use another network to “search” for the best model structure. The search will be cleverly based on a reward function that rewards the model for performing well on the data set it is being validated on. The authors show in the paper that such an architecture can achieve better accuracy than manually designed models. This will be huge in the future especially for design specific applications since all we’ll have to really focus on is designed a good NAS algorithm, rather than hand designing a specific network for our specific application. A well designed NAS algorithm will be flexible enough to find a good network for any specific task.
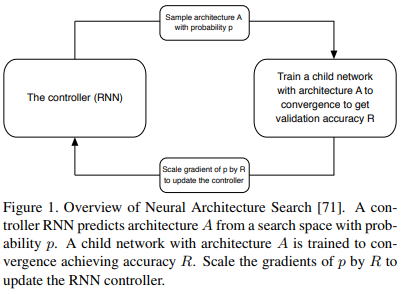
Figure from the paper: Learning Transferable Architectures for Scalable Image Recognition
Conclusion
Thanks for reading! Hopefully you learned something new and useful, and maybe even picked up some new ideas for your own work! If you enjoyed reading, feel free to hit the clap button so other people can see this post and hop on the learning train with us!
原文連結:https://towardsdatascience.com/the-10-coolest-papers-from-cvpr-2018-11cb48585a49