
Java基本數據類型轉換
1:基本數據類型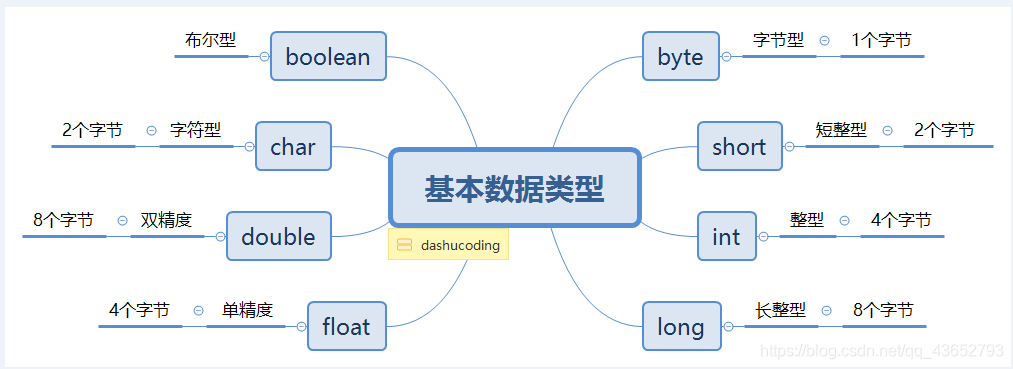
2:引用數據類型
二:基本數據的類型轉換
基本數據類型中,布爾類型boolean占有一個字節,由於其本身所代碼的特殊含義,boolean類型與其他基本類型不能進行類型的轉換(既不能進行自動類型的提升,也不能強制類型轉換), 否則,將編譯出錯。
1.基本數據類型中數值類型的自動類型提升
數值類型在內存中直接存儲其本身的值,對於不同的數值類型,內存中會分配相應的大小去存儲。如:byte類型的變量占用8位,int類型變量占用32位等。相應的,不同的數值類型會有與其存儲空間相匹配的取值範圍。具體如下所示: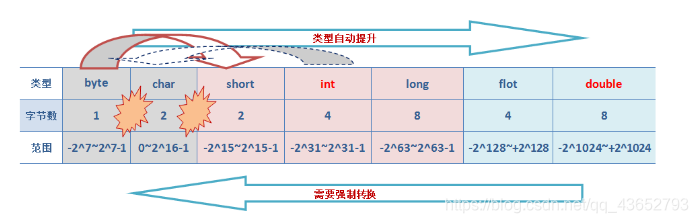
圖中依次表示了各數值類型的字節數和相應的取值範圍。在Java中,整數類型(byte/short/int/long)中,對於未聲明數據類型的×××,其默認類型為int型。在浮點類型(float/double)中,對於未聲明數據類型的浮點型,默認為double型。

接下來我們看看如下一個較為經典例子:
package com.corn.testcast; public class TestCast { public static void main(String[] args) { byte a = 1000; // 編譯出錯 Type mismatch: cannot convert from int to byte float b = 1.5; // 編譯出錯 Type mismatch: cannot convert from double to float byte c = 3; // 編譯正確 } }
是不是有點奇怪?按照上面的思路去理解,將一個int型的1000賦給一個byte型的變量a,編譯出錯,提示"cannot convert from int to byte"是對的,1.5默認是一個double型,將一個double類型的值賦給一個float類型,編譯出錯,這也是對的。但是最後一句:將一個int型的3賦給一個byte型的變量c,居然編譯正確,這是為什麽呢?
原因在於:jvm在編譯過程中,對於默認為int類型的數值時,當賦給一個比int型數值範圍小的數值類型變量(在此統一稱為數值類型k,k可以是byte/char/short類型),會進行判斷,如果此int型數值超過數值類型k,那麽會直接編譯出錯。因為你將一個超過了範圍的數值賦給類型為k的變量,k裝不下嘛,你有沒有進行強制類型轉換,當然報錯了。但是如果此int型數值尚在數值類型k範圍內,jvm會自定進行一次隱式類型轉換,將此int型數值轉換成類型k。如圖中的虛線箭頭。這一點有點特別,需要稍微註意下。
在其他情況下,當將一個數值範圍小的類型賦給一個數值範圍大的數值型變量,jvm在編譯過程中俊將此數值的類型進行了自動提升。在數值類型的自動類型提升過程中,數值精度至少不應該降低(整型保持不變,float->double精度將變高)。
package com.corn.testcast;
public class TestCast {
public static void main(String[] args) {
long a = 10000000000; //編譯出錯: The literal 10000000000 of type int is out of range
long b = 10000000000L; //編譯正確
int c = 1000;
long d = c;
float e = 1.5F;
double f = e;
}
}如上:定義long類型的a變量時,將編譯出錯,原因在於10000000000默認是int類型,同時int類型的數值範圍是-2^31 ~ 2^31-1,因此,10000000000已經超過此範圍內的最大值,故而其自身已經編譯出錯,更談不上賦值給long型變量a了。
此時,若想正確賦值,改變10000000000自身默認的類型即可,直接改成10000000000L即可將其自身類型定義為long型。此時再賦值編譯正確。
將值為1000的int型變量c賦值給long型變量d,按照上文所述,此時直接發生了自動類型提升, 編譯正確。同理,將e賦給f編譯正確。
接下來,還有一個地方需要註意的是:char型其本身是unsigned型,同時具有兩個字節,其數值範圍是0 ~ 2^16-1,因為,這直接導致byte型不能自動類型提升到char,char和short直接也不會發生自動類型提升(因為負數的問題),同時,byte當然可以直接提升到short型。
2.基本數據類型中的數值類型強制轉換
當我們需要將數值範圍較大的數值類型賦給數值範圍較小的數值類型變量時,由於此時可能會丟失精度(1講到的從int到k型的隱式轉換除外),因此,需要人為進行轉換。我們稱之為強制類型轉換。
首先我們看一下如下的例子:
package com.corn.testcast;
public class TestCast {
public static void main(String[] args) {
byte p = 3; // 編譯正確:int到byte編譯過程中發生隱式類型轉換
int a = 3;
byte b = a; // 編譯出錯:cannot convert from int to byte
byte c = (byte) a; // 編譯正確
float d = (float) 4.0;
}
}byte p =3;編譯正確在1中已經進行了解釋。接下來將一個值為3的int型變量a賦值給byte型變量b,發生編譯錯誤。這兩種寫法之間有什麽區別呢?
區別在於前者3是直接量,編譯期間可以直接進行判定,後者a為一變量,需要到運行期間才能確定,也就是說,編譯期間為以防萬一,當然不可能編譯通過了。此時,需要進行強制類型轉換。
強制類型轉換所帶來的結果是可能會丟失精度,如果此數值尚在範圍較小的類型數值範圍內,對於整型變量精度不變,但如果超出範圍較小的類型數值範圍內,很可能出現一些意外情況。
如下經典例子:
package com.corn.testcast;
public class TestCast {
public static void main(String[] args) {
int a = 233;
byte b = (byte) a;
System.out.println("b:" + b); // 輸出:-23
}
}為什麽結果是-23?需要從最根本的二進制存儲考慮。
233的二進制表示為:24位0 + 11101001,byte型只有8位,於是從高位開始舍棄,截斷後剩下:11101001,由於二進制最高位1表示負數,0表示正數,其相應的負數為-23。
3.進行數學運算時的數據類型自動提升與可能需要的強制類型轉換
如下代碼:
package com.corn.testcast;
public class TestCast {
public static void main(String[] args) {
byte a = 3 + 5; // 編譯正常 編譯成 3+5直接變為8
int b = 3, c = 5;
byte d = b + c; // 編譯錯誤:cannot convert from int to byte
byte e = 10, f = 11;
byte g = e + f; // 編譯錯誤 +直接將10和11類型提升為了int
byte h = (byte) (e + f); //編譯正確
}
}當進行數學運算時,數據類型會自動發生提升到運算符左右之較大者,以此類推。當將最後的運算結果賦值給指定的數值類型時,可能需要進行強制類型轉換。
最後感興趣的朋友可以加群一起閑聊qq群947405150,一起交流技術群947405150.
Java基本數據類型轉換