
技術 | Python從零開始系列連載(二十九)
阿新 • • 發佈:2018-11-16
寫爬蟲防止被封的關鍵有以下幾點:
● 偽裝請求報頭(request header)● 減輕訪問頻率,速度
● 使用代理IP
一般第一點都能做到,第二點減輕訪問頻率就會大大增加任務時間,而使用代理就能在不增加任務時長避免被封的關鍵(實際情況卻是任務時間因為代理的使用而增加的,但這裡不細說,知道就好)。
下面我們從 國內高匿代理IP 獲得代理IP資料。
import os
import time
import requests
from bs4 import BeautifulSoup
#num獲取num頁 國內高匿ip的網頁中代理資料
def fetch_proxy(num):
#修改當前工作資料夾
os.chdir(r'/Users/apple888/PycharmProjects/proxy IP')
api = 'http://www.xicidaili.com/nn/{}'
header = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/'
'537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'
fp = open('host.txt', 'a+', encoding=('utf-8'))
for i in range(num+1):
api = api.format(1)
respones = requests.get(url=api, headers=header)
soup = BeautifulSoup(respones.text, 'lxml')
container = soup.find_all(name='tr'
for tag in container:
try:
con_soup = BeautifulSoup(str(tag),'lxml')
td_list = con_soup.find_all('td')
ip = str(td_list[1])[4:-5]
port = str(td_list[2])[4:-5]
IPport = ip + '\t' + port + '\n'
fp.write(IPport)
except Exception as e:
print('No IP!')
time.sleep(1)
fp.close()我們準備抓 國內高匿代理IP網 的十個頁面的代理
fetch_proxy(10)
當前工作目錄下的檔案,你看!!有host.txt
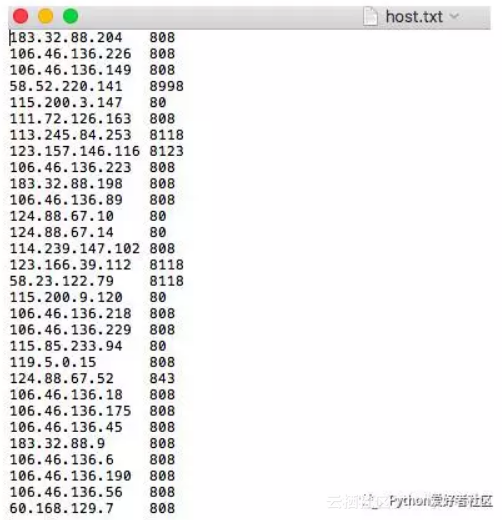
開啟host.txt,收集到了很多代理IP
但是有代理IP還不行,因為我們不知道這代理能不能用,是否有效。
下面我們用百度網進行檢驗(大公司不怕咱們短時間內高頻率訪問),上程式碼:
import os
import time
import requests
from bs4 import BeautifulSoup
def test_proxy():
N = 1
os.chdir(r'/Users/apple888/PycharmProjects/proxy IP')
url = 'https://www.baidu.com'
fp = open('host.txt', 'r')
ips = fp.readlines()
proxys = list()
for p in ips:
ip = p.strip('\n').split('\t')
proxy = 'http:\\' + ip[0] + ':' + ip[1]
proxies = {'proxy': proxy}
proxys.append(proxies)
for pro in proxys:
try:
s = requests.get(url, proxies=pro)
print('第{}個ip:{} 狀態{}'.format(N,pro,s.status_code))
except Exception as e:
print(e)
N+=1執行該程式碼,效果如下
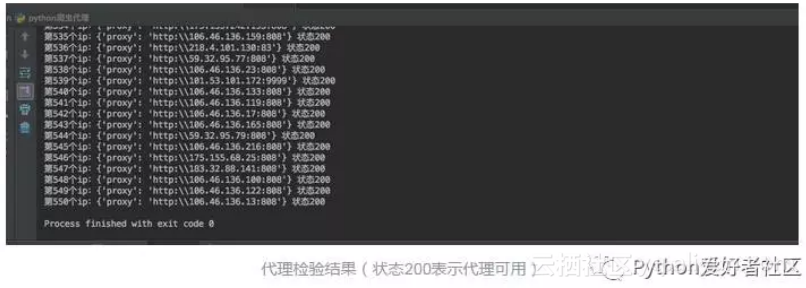
代理Ip池生成函式
#生成代理池子,num為代理池容量
def proxypool(num):
n = 1
os.chdir(r'/Users/apple888/PycharmProjects/proxy IP')
fp = open('host.txt', 'r')
proxys = list()
ips = fp.readlines()
while n<num:
for p in ips:
ip = p.strip('\n').split('\t')
proxy = 'http:\\' + ip[0] + ':' + ip[1]
proxies = {'proxy': proxy}
proxys.append(proxies)
n+=1
return proxys下面開始爬豆瓣電影的電影資料,我們要獲取 電影名、演員、評分。
電影標籤頁 https://movie.douban.com/tag/
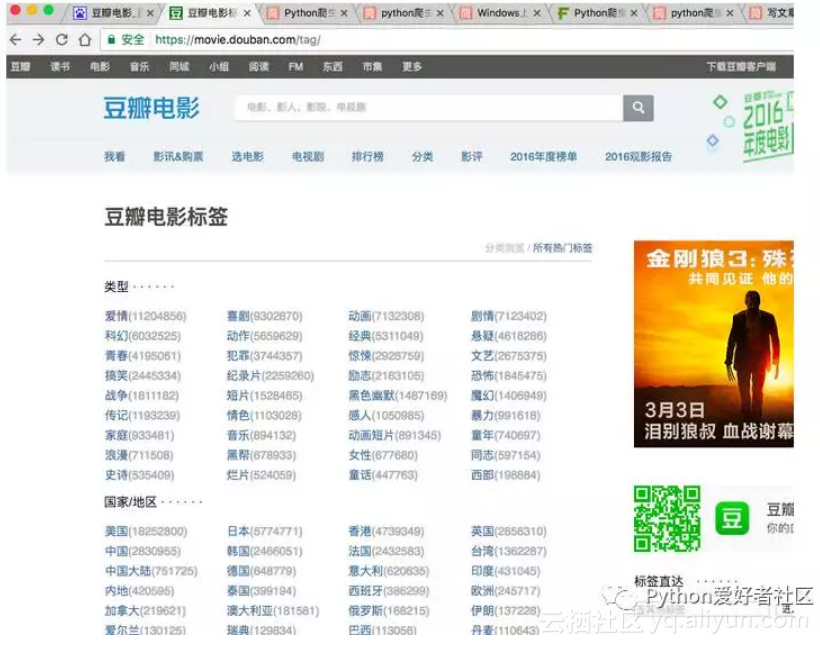
爛片詳情頁https://movie.douban.com/tag/爛片
爛片詳情頁
我們就只爬爛片標籤頁的部分資料吧,網頁連結規律如下
第一頁https://movie.douban.com/tag/爛片?start=0
第二頁https://movie.douban.com/tag/爛片?start=20
第三頁https://movie.douban.com/tag/爛片?start=40
開始上程式碼
def fetch_movies(tag, pages, proxys):
os.chdir(r'/Users/apple888/PycharmProjects/proxy IP/豆瓣電影')
url = 'https://movie.douban.com/tag/愛情?start={}'
headers = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/'
'537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Mobile Safari/537.36'}
#用csv檔案儲存資料
csvFile = open("{}.csv".format(tag), 'a+', newline='', encoding='utf-8')
writer = csv.writer(csvFile)
writer.writerow(('name', 'score', 'peoples', 'date', 'nation', 'actor'))
for page in range(0, pages*(20+1), 20):
url = url.format(tag, page)
try:
respones = requests.get(url, headers=headers, proxies=random.choice(proxys))
while respones.status_code!=200:
respones = requests.get(url, headers=headers, proxies=random.choice(proxys))
soup = BeautifulSoup(respones.text, 'lxml')
movies = soup.find_all(name='div', attrs={'class': 'pl2'})
for movie in movies:
movie = BeautifulSoup(str(movie), 'lxml')
movname = movie.find(name='a')
# 影片名
movname = movname.contents[0].replace(' ', '').strip('\n').strip('/').strip('\n')
movInfo = movie.find(name='p').contents[0].split('/')
# 上映日期
date = movInfo[0][0:10]
# 國家
nation = movInfo[0][11:-2]
actor_list = [act.strip(' ').replace('...', '') for act in movInfo[1:-1]]
# 演員
actors = '\t'.join(actor_list)
# 評分
score = movie.find('span', {'class': 'rating_nums'}).string
# 評論人數
peopleNum = movie.find('span', {'class': 'pl'}).string[1:-4]
writer.writerow((movname, score, peopleNum, date, nation, actors))
except:
continue
print('共有{}頁,已爬{}頁'.format(pages, int((page/20))))執行上述寫好的程式碼
import time
start = time.time()
proxyPool= proxypool(50)
fetch_movies('爛片', 111, proxyPool)
end = time.time()
lastT = int(end-start)
print('耗時{}s'.format(lastT))Perfect
原文釋出時間為:2018-11-16