
kafka結合Spark-streming的直連(Direct)方式
阿新 • • 發佈:2018-11-16
說明:此程式使用的scala編寫
在spark-stream+kafka使用的時候,有兩種連線方式一種是Receiver連線方式,一種是Direct連線方式。
兩種連線方式簡介:
Receiver接受固定時間間隔的資料(放在記憶體中),達到固定的時間才進行處理,效率極並且容易丟失資料。通過高階API,不用管理偏移量,由zk管理,若是拉取的資料超過,executor記憶體大小,訊息會存放到磁碟上面。0.10之後被捨棄。 弊端:效率極並且容易丟失資料
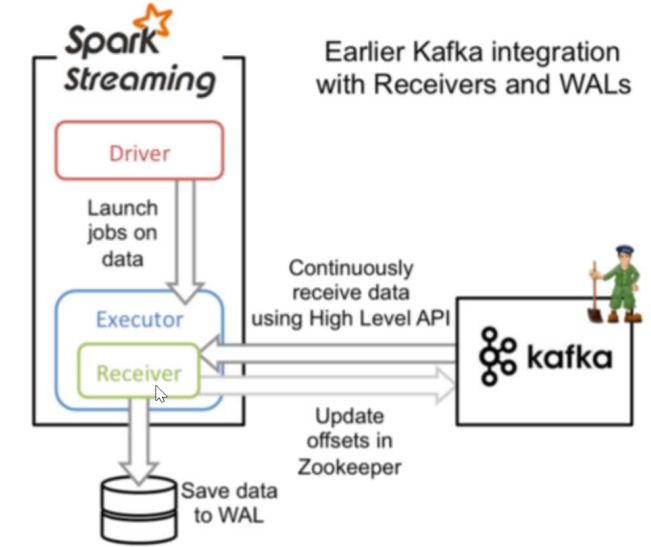
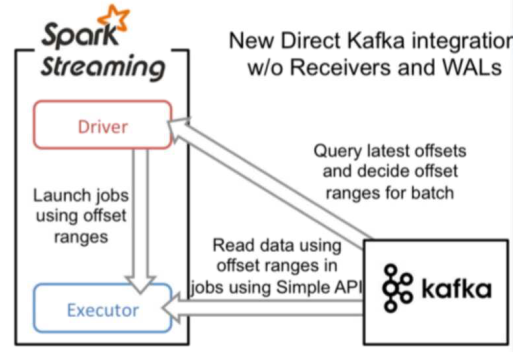
兩者的區別:
Receiver連線方式:他使用的是高階API實現Offset自動管理,不需要我們管理,所以他的靈活性特別差,不好,而且他處理資料的時候,如果某一時刻所傳來的資料量特別大那麼就會造成磁碟溢寫的情況,他通過WALs進行磁碟的寫入。 直連方式:他使用的是底層的API實現Offset我們開發人員管理,這樣的話,他的靈活性很好,並且可以保證資料的安全性,而且不用孤單行資料量過大。 現在主要使用的Direct直連的方式,而不在使用receiver方式 直連程式碼如下:importkafka.common.TopicAndPartition import kafka.message.MessageAndMetadata import kafka.serializer.StringDecoder import kafka.utils.{ZKGroupTopicDirs, ZkUtils} import org.I0Itec.zkclient.ZkClient import org.apache.spark.SparkConf import org.apache.spark.rdd.RDD import org.apache.spark.streaming.dstream.InputDStreamimport org.apache.spark.streaming.kafka.{HasOffsetRanges, KafkaUtils, OffsetRange} import org.apache.spark.streaming.{Duration, StreamingContext} import redis.clients.jedis.Jedis object KafkaDirectConsumer { def main(args: Array[String]): Unit = { // 建立streaming val conf = new SparkConf().setAppName("demo").setMaster("local[2]") val ssc = new StreamingContext(conf, Duration(5000)) // 建立 // 指定消費者組 val groupid = "gp01" // 消費者 val topic = "tt1" // 建立zk叢集連線 val zkQuorum = "spark101:2181,spark102:2181,spark103:2181" // 建立kafka的叢集連線 val brokerList = "spark101:9092,spark102:9092,spark103:9092" // 建立消費者的集合 // 在streaming中可以同時消費多個topic val topics: Set[String] = Set(topic) // 建立一個zkGroupTopicDir物件 // 此物件裡面存放這zk組和topicdir的對應資訊 // 就是在zk中寫入kafka的目錄 // 傳入 消費者組,消費者,會根據傳入的引數生成dir然後存放在zk中 val TopicDir = new ZKGroupTopicDirs(groupid, topic) // 獲取存放在zk中的dir目錄資訊 /gp01/offset/tt val zkTopicPath: String = s"${TopicDir.consumerOffsetDir}" // 準備kafka的資訊、 val kafkas = Map( // 指向kafka的叢集 "metadata.broker.list" -> brokerList, // 指定消費者組 "group.id" -> groupid, // 從頭開始讀取資料 "auto.offset.reset" -> kafka.api.OffsetRequest.SmallestTimeString ) // 建立一個zkClint客戶端,用host 和 ip 建立 // 用於從zk中讀取偏移量資料,並更新偏移量 // 傳入zk叢集連線 val zkClient = new ZkClient(zkQuorum) // 拿到zkClient後去,zk中查詢是否存在檔案 // /gp01/offset/tt/0/10001 // /gp01/offset/tt/1/20001 // /gp01/offset/tt/2/30001 val clientOffset = zkClient.countChildren(zkTopicPath) // 建立空的kafkaStream 裡面用於存放從kafka接收到的資料 var kafkaStream: InputDStream[(String, String)] = null // 建立一個存放偏移量的Map // TopicAndPartition [/gp01/offset/tt/0,10001] var fromOffsets: Map[TopicAndPartition, Long] = Map() // 判斷,是否婦女放過offset,若是存放過,則直接從記錄的 // 偏移量開始讀 if (clientOffset > 0) { // clientOffset的數量就是 分割槽的數目量 for (i <- 0 until clientOffset) { // 取出 /gp01/offset/tt/i/ 10001 -> 偏移量 val paratitionOffset = zkClient.readData[String](s"${zkTopicPath}/${i}") // tt/ i val tp = TopicAndPartition(topic, i) // 新增到存放偏移量的Map中 fromOffsets += (tp -> paratitionOffset.toLong) } // 現在已經把偏移量全部記錄在Map中了 // 現在讀kafka中的訊息 // key 是kafka的kay,為null, value是kafka中的訊息 // 這個會將kafka的訊息進行transform 最終kafka的資料都會變成(kafka的key,message)這樣的tuple val messageHandlers = (mmd: MessageAndMetadata[String, String]) => (mmd.key(), mmd.message()) // 通過kafkaUtils來建立DStream // String,String,StringDecoder,StringDecoder,(String,String) // key,value,key的解碼方式,value的解碼方式,(接受的資料格式) kafkaStream = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder, (String, String)]( ssc, kafkas, fromOffsets, messageHandlers ) } else { // 若是不存在,則直接從頭讀 // 根據kafka的配置 kafkaStream = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkas, topics) } // 偏移量範圍 var offsetRanges = Array[OffsetRange]() kafkaStream.foreachRDD { kafkaRDD => // 得到kafkaRDD,強轉為HasOffsetRanges,獲得偏移量 // 只有Kafka可以強轉為HasOffsetRanges offsetRanges = kafkaRDD.asInstanceOf[HasOffsetRanges].offsetRanges // 觸發Action,這裡去第二個值為真實的資料 val mapRDD = kafkaRDD.map(_._2) /*=================================================*/
// mapRDD為資料,在這裡對資料操作
// 在這裡寫你自己的業務處理程式碼程式碼
// 此程式可以直接拿來使用,經歷過層層考驗
/*=================================================*/ // 儲存更新偏移量 for (o <- offsetRanges) { // 獲取dir val zkPath = s"${zkTopicPath}/${o.partition}" ZkUtils.updatePersistentPath(zkClient, zkPath, o.untilOffset.toString) } } ssc.start() ssc.awaitTermination() } }
以上為Direct直連方式的程式碼,直接可以使用的,根據自己的叢集,和topic,groupid等配置稍作修改即可。