
sk buff封裝和解封裝網路資料包的過程詳解
阿新 • • 發佈:2018-11-16
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow
也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
可以說sk_buff結構體是Linux網路協議棧的核心中的核心,幾乎所有的操作都是圍繞sk_buff這個結構體進行的,它的重要性和BSD的mbuf類似(看過《 TCP/IP詳解 卷2》的都知道),那麼sk_buff是什麼呢?sk_buff就是網路資料包本身以及針對它的操作元資料。
想要理解sk_buff,最簡單的方式就是憑著自己對網路協議棧的理解封裝一個直到以太層的資料幀並且成功傳送出去,個人認為這比看程式碼/看文件或者在網上搜資料強多了。當然,網上已經有了大量的這方面的文章,但是我認為很多都太複雜了,它們都細化到了sk_buff結構體的每一個指標欄位,並且還都畫出了圖,但一般都逃不過《
因此,本文絕不深入到sk_buff的細節,但是相信這種簡單的方式可以讓自己在多年以後早已忘了什麼是Linux協議棧的情況下,瞬間理解Linux是如何通過sk_buff封裝資料包的。我們從網路的分層模型開始。
網路分層模型
這是一切的本質。網路被設計成分層的,所以網路的操作就可以稱作一個“棧”,這就是網路協議棧的名稱的由來。在具體的操作上,資料包最終形成的過程就是一層一層封裝的過程,在棧上形成一段連續的資料,我們可以稱作是一層一層的push操作。同樣的,資料包的解封裝的過程,則可以認為是一層一層的pop操作。
要想形成一個最終的資料包,即以太幀(不考慮其它的鏈路層)。要進行以下的操作:
1.分配一個skb結構體
2.分配資料包的資料區
3.在skb資料區定位應用層起始位置
4.拷貝資料到應用層(假設應用層協議沒有在socket介面之上被封裝)
5.在skb資料區定位傳輸層起始位置
6.設定傳輸層頭部欄位
7.在skb資料區定位IP層起始位置
8.設定IP層頭部欄位
9.在skb資料區定位以太層起始位置
10.設定以太頭部欄位
可以看出基本的模式,即“定位/設定”兩步驟操作,有點區別的是應用層操作,這是因為應用層的操作一般都是在socket介面之上完成的。但是既然本文講述的是skb的通用操作,就不再區分這個了。
在上面一小節,我們展示了skb的封裝邏輯,但是具體到介面層面,就涉及到了skb的核心操作。
1.分配skb
這個是由alloc_skb完成的,完成同一任務的介面形成一個介面族,但是alloc_skb是最基本的介面。該alloc_skb介面完成兩件事,即分配skb結構體以及skb資料包緩衝區,設定初始值。size引數表示skb的資料包緩衝區的大小,這個大小包括所有層的總和。如果該函式成功返回,那麼就相當於你已經有了一個大小為size的空資料包緩衝區以及操作該資料包緩衝區的skb元資料。如下圖所示:

2.初始定位(skb_reserve)
skb的逐層封裝的關鍵在於寫指標的定位,即這一層從哪個位置開始寫。從協議封裝的壓棧形象來看,這個定位應該是順序有規律的。初始定位十分重要,後面的定位就是例行公事了。初始定位當然是定位到應用層的末端,從這裡開始,逐層將協議頭push到skb的資料包緩衝區。初始定點陣圖示如下: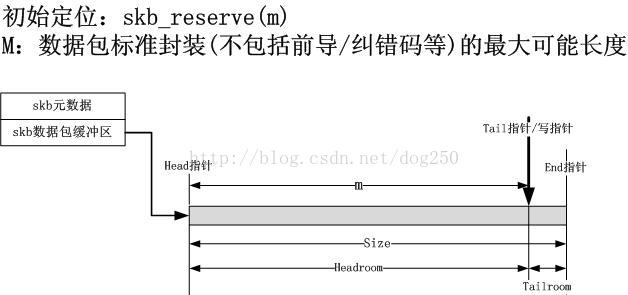
3.拷貝應用層資料(skb_push/copy)
當skb分配好了之後,需要將協議“棧”的位置定位在資料包的“最低處”,這是初始定位,這樣才可以把每一層的資料或者協議頭push到棧上,這個操作由skb_reserve來完成。應用層資料已經在socket之上封裝好了,那麼就把skb的資料包緩衝區寫指標定位到應用資料的開始處,此時的寫指標在應用層緩衝區的末尾,因此需要使用skb_push操作將寫指標定位到應用層開始處,這等於說壓入了應用層棧幀。skb_push介面是將一個協議棧幀壓入協議棧的介面,它返回一個position,該position就是skb資料包的寫指標,告訴呼叫者,這裡開始按照你的封裝邏輯封裝資料包,寫多少位元組呢?由skb_push的引數n指示。應用層的壓棧操作如下圖所示:
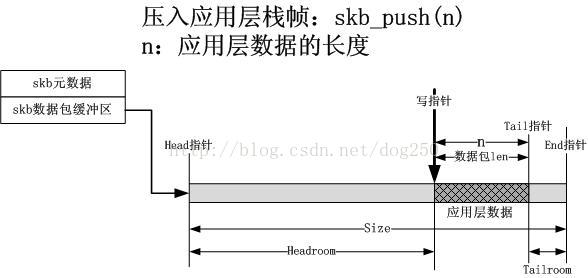
4.設定傳輸層頭部
和應用層的操作類似,這次需要把傳輸層棧幀壓入協議棧中,如下圖所示: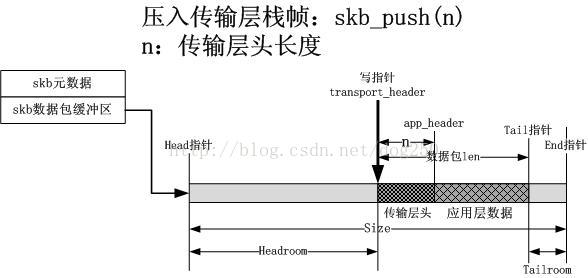
5.設定IP層頭部
和應用層以及傳輸層操作類似,這次需要把IP層的棧幀壓入協議棧中,如下圖所示: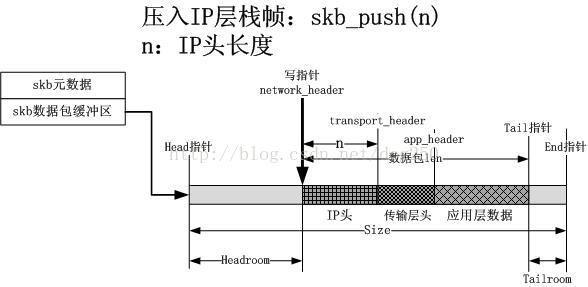
6.設定以太幀頭部
這個就不說了,和上述的類似...如下圖所示: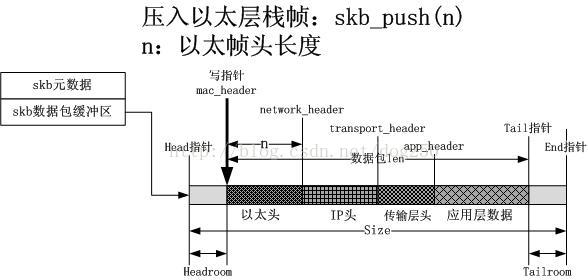
在skb_push返回的那一刻,一個棧幀被壓入了協議棧,然後該棧幀還仍未被寫入資料,也就是說還沒有完成封裝過程,具體的封裝過程由呼叫者自己實現。
skb_push導致了skb資料包緩衝區寫指標位置的前推,連帶的改變了好幾個變數,首先資料包的長度增加了n個位元組,其次縮小了headroom的空間,然後通過reset_XXX_header的呼叫,skb記住了某層協議頭在資料包中的位置(這點特別重要!比如在TSO/UFO的情況下,網絡卡驅動需要協議頭的位置資訊,用以計算校驗值,所以雖然skb不記住協議頭的位置,一個數據包也能完成封裝,但是對於協議棧的完整實現而言,卻是不正確的做法,畢竟網絡卡計算校驗碼已經成了一種事實上的標準[即便它違背了嚴格的分層原則!])
7.在應用資料後面追加PADDING
目前為止,從最後的圖示上可以看到,在skb資料包緩衝區中,還有兩塊區域沒有使用,一個headroom,一個是tailroom,這些是幹什麼用的呢?作為一個練習的例子,由於存在某種對齊原則,在封裝完成後,我需要在資料包的最後追加一些填充,或者說我需要在最前面加一個前導碼,或者最常見的,我要在資料包的最後加一個糾錯碼,此時應該怎麼辦呢?這個時候就需要headroom或者tailroom了,以在資料包最後追加資料為例,請看下圖:
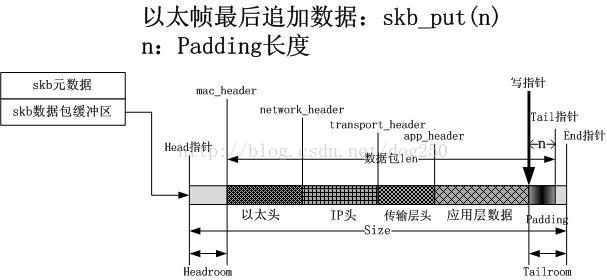
實際上,skb_put的操作就是,在資料包的末尾追加資料。至於說headroom如何使用,我就不多說了,其實還是skb_push,headroom有什麼用呢?前導碼,X over Y封裝,不一而足。
實際的例子
下面我給出一個實際的例子,封裝一個以太幀,然後傳送出去: skb = alloc_skb(1500, GFP_ATOMIC); skb->dev = dev; // 例行填充skb元資料 /* 保留skb區域 */ skb_reserve (skb, 2 + sizeof(struct ethhdr) + sizeof(struct iphdr) + sizeof(struct udphdr) + sizeof(app_data)); /* 構造資料區 */ p = skb_push(skb, sizeof(app_data)); memcpy(p, &app_data[0], sizeof(app_data)); p = skb_push(skb, sizeof(struct udphdr)); udphdr = (struct udphdr *)p; // 填充udphdr欄位,略 skb_reset_transport_header(skb); /* 構造IP頭 */ p = skb_push(skb, sizeof(struct iphdr)); iphdr = (struct iphdr*)p; // 填充iphdr欄位,略 skb_reset_network_header(skb); /* 構造以太頭 */ p = skb_push(skb, sizeof(struct ethhdr)); ethhdr = (struct ethhdr*)p; // 填充ethhdr欄位,略 skb_reset_mac_header(skb); /* 發射 */ dev_queue_xmit(skb);解封裝的過程和封裝的過程相反,解封裝的過程是協議棧棧幀逐層pop的過程,但是Linux協議棧並沒有用棧的術語來定義介面名字,而是使用了push的反義詞,即pull來定義的,skb_pull就是核心介面,和skb_push嚴格相對。我就不再一一畫圖了。
按照介面編碼而不是按照實現編碼
這好像是Effective C++裡面的一條,同樣也適合於skb的操作場景。典型的就是“如何讓skb記住IP層協議頭,傳輸層協議頭,mac頭的位置”,介面是:skb_reset_mac_headerskb_reset_network_headerskb_reset_transport_header /* 構造IP頭 */ p = skb_push(skb, sizeof(struct iphdr)); iphdr = (struct iphdr*)p; // 填充iphdr欄位,略 //skb_reset_network_header(skb); skb->network_header = p;protocol 0008 is buggy, dev eth2
這是怎麼回事?原因就在於skb紀錄的協議頭位置是錯誤的!難道以上的設定skb的network_header欄位的方式有何不妥嗎?當然不妥!這就是沒有按照介面編碼的惡果。
原因在於,系統設定skb的network_header欄位的方式有兩種,通過一個巨集來識別:NET_SKBUFF_DATA_USES_OFFSET。也就是說,可以通過相對於skb的head指標的偏移來定位協議頭的位置,也可以通過絕對地址來定位,具體使用哪一種取決於系統有沒有定義NET_SKBUFF_DATA_USES_OFFSET巨集,以上的skb->network_header = p明顯是通過絕對地址來定位的,一旦系統定義了NET_SKBUFF_DATA_USES_OFFSET巨集,肯定就不對了。既然巨集定義在編譯期確定,那麼通過定義介面就可以在編譯期唯一確定一種實現,程式設計師不必在乎是否定義了NET_SKBUFF_DATA_USES_OFFSET巨集,這就是通過介面程式設計的益處。如果基於skb的實現來程式設計,你不得不針對所有的情況編寫好幾套實現,而以上錯誤的實現只是其中一種,而且還用錯了場景!這是多麼痛的領悟!
NET_SKBUFF_DATA_USES_OFFSET巨集是一個細節問題,如果使用介面程式設計便不必關注這個細節,否則你就必須搞清楚系統為何這麼設計,即便這並不是你所關注的!為何呢?
由於指標的長度大小在32位系統和64位系統中是不一樣的,所以按理說skb中的指標型的元資料大小也會不同,且64位系統的將會是32位系統的兩倍,為了平滑掉這個差別,使元資料大小一致,就必須讓64位系統的對應指標型別變為4個位元組,而這是不可能的。因此在64位系統中,使用偏移來定位元資料,而偏移的型別為固定不變的unsigned int,即4個位元組。為了支援上述說法,skb中加入了一個新的層次,即定義了一種新的資料型別sk_buff_data_t,該型別在編譯期確定:
#if BITS_PER_LONG > 32#define NET_SKBUFF_DATA_USES_OFFSET 1#endif#ifdef NET_SKBUFF_DATA_USES_OFFSETtypedef unsigned int sk_buff_data_t;#elsetypedef unsigned char *sk_buff_data_t;#endif為何未竟全功
本文講述到此為止。事實上,sk_buff還有更多的,相當多的細節,但是不能再一一描述了,因為那樣就違背了本文一開始的初衷,即用最簡單的方式揭露本質,如果一一描述了,那麼本文將成為一個文件而非一篇感悟,時隔多年以後,相信自己也不會看下去的。關於sk_buff還有超級多的內容,僅僅結構體裡面豐富欄位的含義就夠折騰好久的了,加上它如何配合Linux各層協議的實現,內容就更加豐富了。不過最基本的,就是本文講述的,你得知道資料是怎樣塞到一個skb並封裝成一個可以被網絡卡實際傳送的資料包的。好了,基本就是這些。最後我來總結一下本文提到的幾個介面:
alloc_skb:分配一個skb;
skb_reserver:寫指標向後移動到一個位置p,確定為資料包尾部,自始,寫指標開始從該位置前移封裝資料包;
skb_push:寫指標前移n,更新資料包長度,從它返回的位置可以寫n個位元組資料-即封裝n位元組的協議;
skb_put:寫指標移動到資料包尾部,返回尾部指標,可以從此位置寫n位元組資料,同時更新尾指標和資料包長度;
...
給我老師的人工智慧教程打call!http://blog.csdn.net/jiangjunshow
