
puppeteer爬蟲扒取資料後存入資料庫
阿新 • • 發佈:2018-11-17
puppeteer爬蟲扒取資料後存入資料庫
由於最近的工作內容接觸到了爬蟲與測試
所以這裡就記錄了一個小小的例子
爬蟲puppeteer + Koa2 + Mysql
是從之前koa2專案上增強了爬蟲的功能
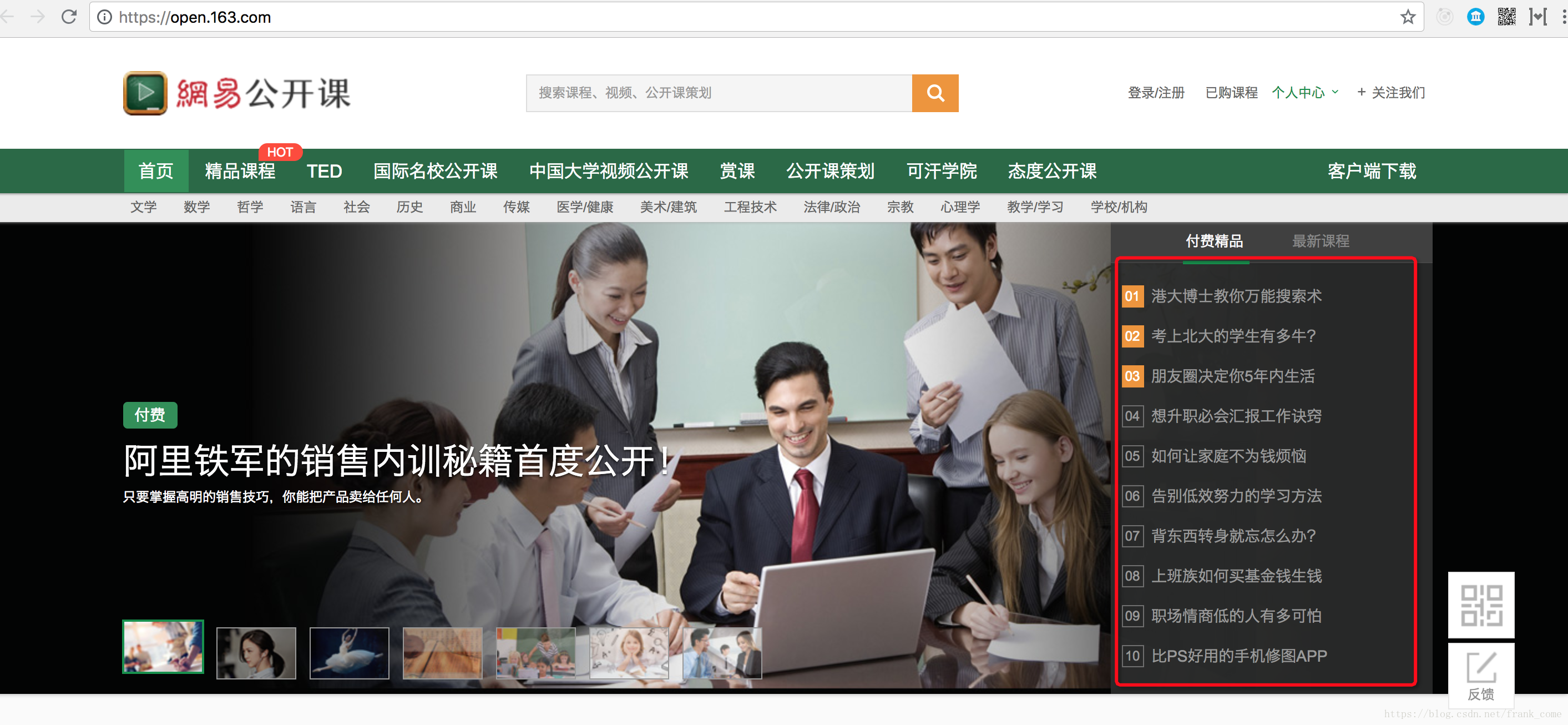
爬蟲是以網易公開課的例子為例
之前koa部落格地址:https://blog.csdn.net/frank_come/article/details/80805032
koa專案地址:https://github.com/WeForStudy/Lottery-node
紅圈部分是要扒取的資料
首先我們來看一下專案目錄
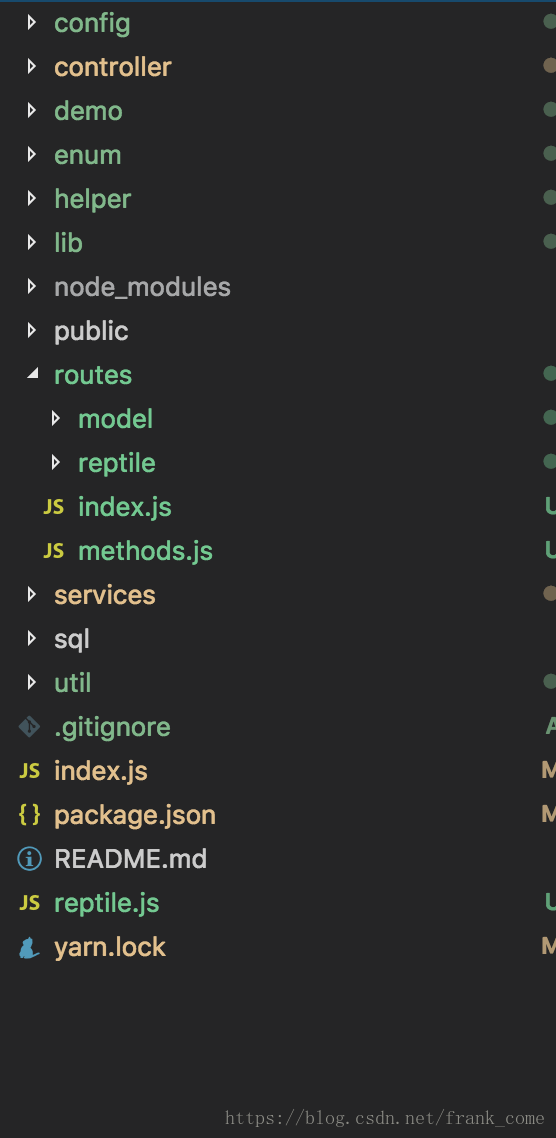
我們是在之前koa專案的基礎上添加了爬蟲的功能
新添的檔案
-
reptile.js
我們來看一下
const ReptileService = require('./services/reptile') const app = require('./index') const puppeteer = require('puppeteer'); (async() => { const browser = await puppeteer.launch(); const page = await browser.newPage(); const url = "https://open.163.com/" await page.goto(url); const courses = await page.evaluate(() => { const coursesList = Array.from( document.querySelectorAll('.j-hotlist .item') ) const getText = (e, selector) => { return e.querySelector(selector) && e.querySelector(selector).innerText } const data = coursesList.map(e => { const obj = { num: getText(e, '.icon'), text: getText(e, 'span'), } return obj }) return data }) // 拿到資料以後插入資料庫 await courses.map(async item => { const cV = JSON.stringify(item) const res = await ReptileService.add({ url, contentValue: cV, type: 1000, // 代表是內容 }, true) if (res) { console.log(`呼叫ReptileService新增物件成功,物件值為:${cV}`) } else { console.log(`呼叫ReptileService新增物件失敗,原因為:${res}`) } }) await page.close() await browser.close() app() })();
首先我們開啟網頁以後,開啟谷歌開發者工具(F12或者滑鼠右鍵選擇),分析一下資料所在的div結構,以本demo為例
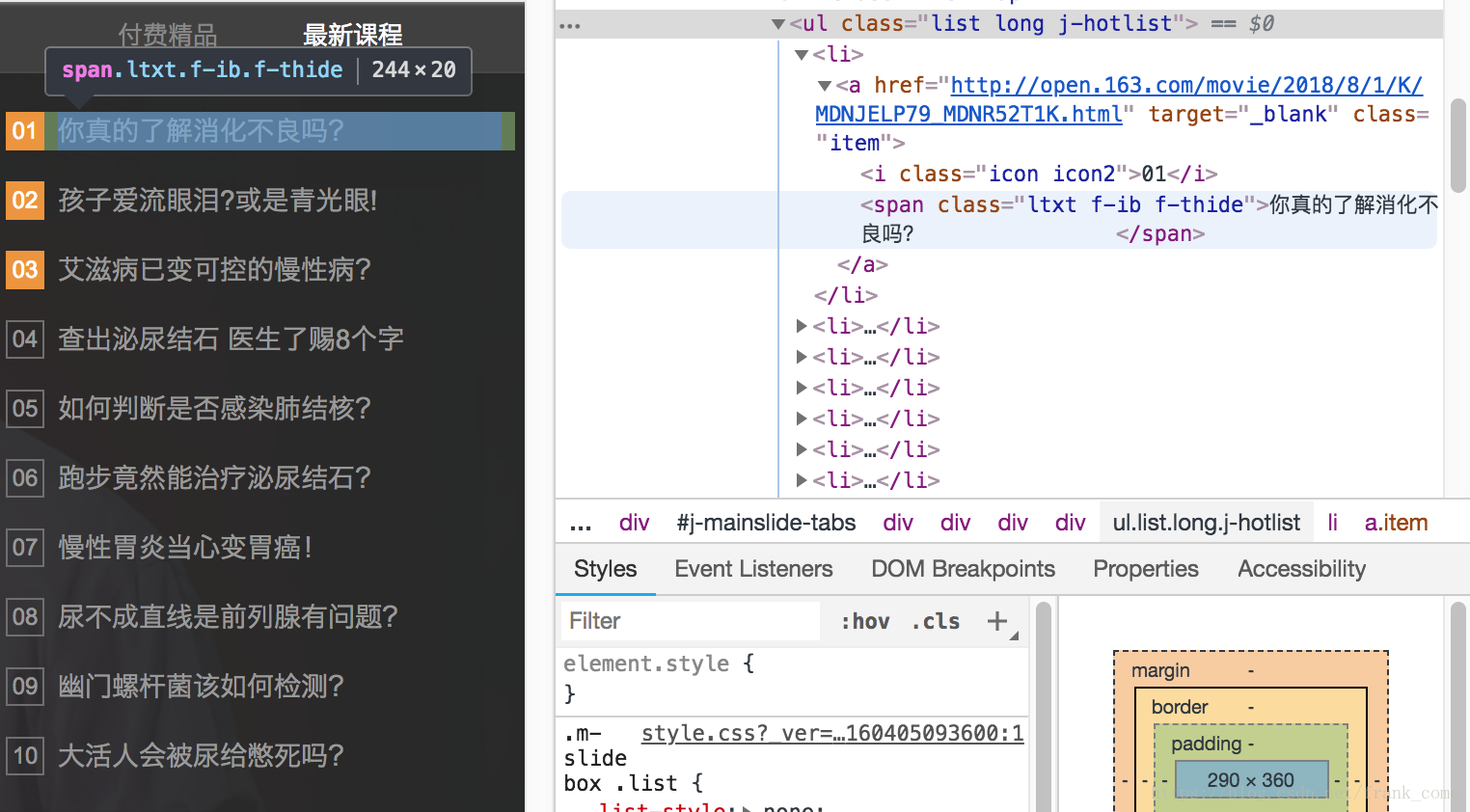
我們可以清晰地看到想要的資料是在<div>.j-hotlist裡的<a>標籤.item裡的<i>和<span>
我們來看一下程式碼
在開啟網頁後,我們用puppeteer內建的evaluate方法進入瀏覽器環境,然後獲得到對應的HTMLElement節點
這是我們拿到的資料。
[ { num: '01', text: '你真的瞭解消化不良嗎?\t\t\t\t' },
{ num: '02', text: '孩子愛流眼淚?或是青光眼!\t\t\t\t' },
{ num: '03', text: '艾滋病已變可控的慢性病?\t\t\t\t' },
{ num: '04', text: '查出泌尿結石 醫生了賜8個字' },
{ num: '05', text: '如何判斷是否感染肺結核?\t\t\t\t' },
{ num: '06', text: '跑步竟然能治療泌尿結石?' },
{ num: '07', text: '慢性胃炎當心變胃癌!\t\t\t\t' },
{ num: '08', text: '尿不成直線是前列腺有問題?' },
{ num: '09', text: '幽門螺桿菌該如何檢測?\t\t\t\t' },
{ num: '10', text: '大活人會被尿給憋死嗎?' } ]接下來就是對資料庫的操作了
我們呼叫Services層
// 拿到資料以後插入資料庫
await courses.map(async item => {
const cV = JSON.stringify(item)
// 調
const courses = await page.evaluate(() => {
// evaluate方法是在瀏覽器環境下執行的一個匿名函式
// 可以獲取瀏覽器環境下等價的Bom操作
// Document、 Window etc.
// 注意的是,內部是一個隔離的環境,可以通過第二個引數把引數傳過來evaluate(func, params)
// 分析對應的資料結構
const coursesList = Array.from(
document.querySelectorAll('.j-hotlist .item')
)
// 獲取相應元素內部子元素的innerText
const getText = (e, selector) => {
return e.querySelector(selector) && e.querySelector(selector).innerText
}
// 組合資料
const data = coursesList.map(e => {
const obj = {
num: getText(e, '.icon'),
text: getText(e, 'span'),
}
return obj
})
// 返回
return data
})用service的新增
const res = await ReptileService.add({
url,
contentValue: cV,
type: 1000, // 代表是內容
}, true)
if (res) {
console.log(`呼叫ReptileService新增物件成功,物件值為:${cV}`)
} else {
console.log(`呼叫ReptileService新增物件失敗,原因為:${res}`)
}
})其中url代表來源,contentValue代表我們扒取到的內容,type代表是文字還是圖片,
當然這個設計很簡單,也只是為了讓爬蟲的功能和資料庫貫穿起來,我們就不糾結這個資料庫的設計了
接下來我們來看一下services層的內容
const controller = require('../controller/reptile')
const pojo = require('../helper/pojo')
const model = require('./model')
const { success, failed, filterUnderLine } = pojo
const m = model([
'list',
], 'reptile')
/**
* @description 重寫add,為了給爬蟲新添一些邏輯
* @param {*} ctx 如果是node環境呼叫就是params
* @param {*} isNode 如果是node環境呼叫(非api)
*/
const add = async (ctx, isNode = false) => {
let res;
try {
let val;
if (isNode) {
val = ctx
} else {
val = ctx.request.body
}
// 呼叫controller的add方法
await controller.add(val).then(result => {
if (isNode) {
// node調取返回影響的行數
res = result.affectedRows
return
}
if(result.length === 0 || result === null || result === undefined)
res = failed('操作失敗')
else
res = success(filterUnderLine(result[0]))
})
} catch(err) {
res = failed(err)
}
if (isNode) {
// node調取返回bool
return res >= 1
} else {
ctx.body = res
}
}
module.exports = {
...m,
add,
}
其中add方法分為兩種環境呼叫,node呼叫和正常api呼叫
接下來是controller
// 在lib下封裝好的mysql資料庫連線池
const pool = require('../lib/mysql')
// STATUS是定義的列舉物件
const { STATUS } = require('../enum')
// 封裝好的資料庫連線池物件
const { query } = pool
// 新添管理員
const add = (val) => {
const { url, contentValue, type } = val
const values = Object.values(val)
const _sql = 'insert into reptile(url,content_value,type,create_time,status) values(?,?,?,now(),?);'
return query( _sql, [ url, contentValue, type, STATUS.NORMAL])
}
const list = () => {
const _sql = 'select * from reptile where status =? ;'
return query( _sql, [STATUS.NORMAL])
}
module.exports = {
add,
list,
}
list為正常的api,
到這裡,我們就完成了對資料庫的操作了
yarn run craw在進行爬蟲的同時打開了koa的資料服務