
SQUEEZENET:AlexNet-level Accuracy with 50X fewer parameters and 0.5MB model size
阿新 • • 發佈:2018-11-17
這是由UC Berkerley和Stanford研究人員一起完成的Squeezenet網路結構和設計思想。SqueezeNet設計目標是在保持精度(Alexnet)的情況下簡化網路的複雜度。
1、設計原則:
- 儘量選擇1*1卷積核來代替3*3卷積核,因為1*1的卷積核比3*3的卷積核引數少了9倍。
- 減少3*3卷積核的輸入通道(input channels),因為卷積核引數為:(number of input channels)*(number of filters)*3*3
- 延遲下采樣(downsample),前面的layers可以有更大的特徵圖,有利於提升模型的準確度。目前下采樣一般採用strides>1的卷積或者pool layer。【下采樣即縮小影象,目的是使影象符合現實區域的大小,生成對應影象的縮圖。】在AlexNet中,第一層的卷積是stride=4,直接下采樣了4倍。在一般的CNN中,一般卷積層、池化層都會有下采樣(stride>1),甚至在前面基層網路的下采樣比例會比較大,這樣會導致最後幾層的神經元的啟用對映區域減少。為了提高精度設計下采樣延遲慢一點
【前兩個策略是為了減少引數,而第三個策略是為了最大化精度】
2、SqueezeNet的網路結構
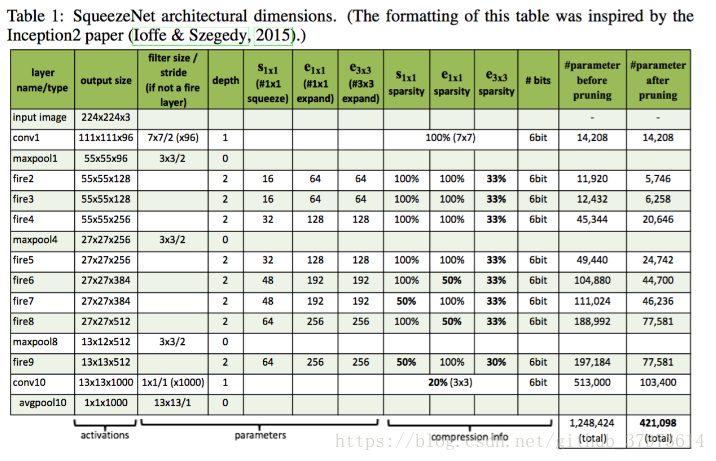
SqueezeNet網路基本但願是採用了模組化的卷積,其稱為Fire module。Fire模組主要包含兩層卷積操作:一是採用了1x1卷積核的squeeze層;二是混合使用1x1和3x3卷積核的expand層。Fire模組的基本結構如下圖。在squeeze層卷數記為,在expand層卷積數記為
和
,分別代表了1x1和3x3卷積核的數量。為了儘量減少3x3的輸入通道,這裡讓
。

整個SqueezeNet網路就是由File module堆積起來的,SqueezeNet的整體結構如下圖,左邊是標準的SqueezeNet,其最開始是一個卷積層,後面是Fire module的堆積,值得注意的是其中穿插了stride=2的maxpool層,其主要作用的是下采樣(downsample),並採用延遲的策略,儘量使前面層擁有較大的feature map。中間和右邊的圖分別是引入了不同“短路”機制的SqueezeNet,借鑑了resNet的結構:

3、具體的實現細節
- 在Fire模組中,expand層採用了混合卷積核1x1和3x3,stride=1,對於1x1,其輸出的feature map與原始一樣大, 3x3則padding=1,也會得到和原始一樣大小的圖。
- Fire模組中所有卷積層的啟用函式採用ReLU
- Fire9層厚採用了dropout=0.5
- SqueezeNet沒有全連線層,而是採用了全域性的avgpool(global average pool),即pool size和輸入的feature map大小一致。
- 訓練採用線性遞減的學習速率,初始學習速率為0.04
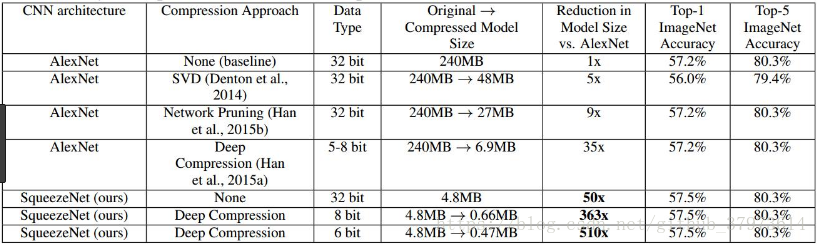
結果的對比:
除了上面的工作,作者還探索了網路的設計空間,包括微觀結構和巨集觀結構,微觀結構包括各個卷積層的維度等設定,巨集觀結構比如引入ResNet的短路連線機制。
參考:https://zhuanlan.zhihu.com/p/31558773