
一些kaldi常用的術語和命令(一)
/egs裡一般存放執行的指令碼,.sh檔案,講了每一步要執行什麼操作,而真正的演算法程式部分,在/src裡的.cc、.h檔案裡。-
archive(.ark)、script(.scp) :是表格(table)一個‘表’就是一組有序的事物,前面是識別字符串(如句子的id),一個‘表’不是一個c++的物件,因為對應不同的需求(寫入、迭代、隨機讀入)我們分別有c++物件來讀入資料。Table有兩種形式:“archive”和“script”檔案。它們之間的差別在於:archive 包含實際的資料,而 script 檔案則指出資料的具體位置。
.scp格式是text-only的格式,每行是個key(一般是句子的識別符號(id))後接空格,接這個句子特徵資料的路徑
。.ark格式可以是text或binary格式,(你可以寫為text格式,命令列要加‘t’,binary是預設的格式)檔案裡面資料的格式是:key(如句子的id)空格後接資料。
-
.ark 和.scp 是 kaldi 中兩種記錄數 據的格式, .ark 是資料(二進位制檔案),scp 是記錄對應 ark 的路徑。 .ark 檔案一般都是很大的(因為他們裡面是真正的資料)
-
開頭的ark:或scp:是要說明的格式,同名的 archive(.ark) 和 script(.scp) 檔案代表的同一部分資料,注意,這 些命令列都有字首”scp:” 或 “ark:”,kaldi 不會自己判斷這到底是個 script 還是 archive 形式,這需要我們加字首告訴 kaldi 這是什麼格式的檔案。對於 code 而言, 這兩種格式對它來說都是一樣的。
這兩種格式都是‘表(table)’的概念。一個‘表’就是一組有序的事物,前面是 識別字符串(如句子的 id),一個‘表’不是一個 c++的物件,因為對應不同的需 求(寫入、迭代、隨機讀入)我們分別有 c++物件來讀入資料。
.scp 格式是 text-only 的格式,每行是個 key(一般是句子的識別符號(id))後 接空格,接這個句子特徵資料的路徑 。
.ark 格式可以是 text 或 binary 格式,(你可以寫為 text 格式,命令列要加‘t’, binary 是預設的格式)檔案裡面資料的格式是:key(如句子的 id)空格後接資料。
比如 raw_mfcc_dev.1.scp裡的FNLP0_si1308 /Users/yelong/kaldi/egs/timit/s5/mfcc/raw_mfcc_test.3.ark:13意思是,開啟存檔(archive)檔案,fseek()定位 到 13(位元組),然後開始讀資料。
-
rspecifier、wspecifiers用法 (P129)
常用的“o”(once)、“p”(permissive)、“s”(sorted)、“cs”(called-sorted)。
舉例:"ark:o,s,cs:-"
"scp,p:data/my.scp"
1
2
從 Tabla 中讀資料的程式需要一個“rspecifier”輸入,該字串指明瞭如何讀 取索引資料;而寫資料到 Table 中的程式需要一個“wspecifier”輸入,該字串 指示如何寫資料。這兩個字串指出是否需要 scritpt 或 archive 檔案,檔案位置, 以及不同的選項。常用的“rspecifiers”有“ark:-”,表示從標準的輸入中讀取 archive 資料;而“scp:foo.scp”表示 script檔案“foo.scp”會告訴我們從哪裡去讀取資料(因為scp檔案只存了路徑,)。 下面幾點需要牢記:
- 冒號後面的部分被解釋為“wxfilename”或“rxfilename”(與 Non-table I/O 中一樣),這意味著管道和標準的輸入/輸出均可支援。
- 一個 Table 通常只包含一種型別的物件(例如浮點型矩陣)
- 你可以檢視“rspecifiers”和“wspecifiers”中的選項,主要有:
- 在“rspecifiers”中,“ark,s,cs:-”表示當我們讀資料時,我們希望keys是有序的(s),以及我們會按順序訪問資料(cs),若這些條件不滿足時,程式會崩潰。這些保證了Kaldi中高效的的隨機訪問,而不佔用大量的記憶體。
- 對於規模較少並且不太方便進行排序列的資料(例如:說話人自適應 應變換矩陣),若省略掉 s, cs 引數,幾乎沒有損害。
- 當Kaldi程式有多個“rspecifiers”輸入時,程式會輪流訪問相應的物件;其中第一個使用順序訪問,而後面的採用隨機訪問,因此,第一個“rspecifier”不需要“s, cs”選項。
- 在訪問script檔案時,例如“p:foo.scp”,其中“p”意味著當我們 需要的檔案不存在時,程式不會崩潰(對於 archive,當期望的文 件被破壞或被截斷時,“p”也地阻止程式崩潰)。
- 寫資料時,選項“t”表示文字模式,例如:“ark,t:-”。“-binary” 命令列選項對 archives 無效。
- Script 檔案每一行的格式為:“
-
L.fst 檔案是編譯後的 FST 格式的詞典(lexicon)
訓練好的模型,一般是.mdl字尾,裡面用命令開啟,是很詳細的過程,第一部分是做什麼的,然後一堆引數,第二部分是做什麼的,一堆引數。模型都是一堆引數。輸入特徵,輸出聲學模型、語言模型。
在shell裡gcc,kaldi裡的/src檔案裡的很多沒有後綴的可執行檔案,都是可以直接執行編譯的,只要把path加進去,然後變數名新增一下,幾乎不用改動很多,就能執行。重點就是要理解c++的演算法,經常需要單步除錯。shell裡也是可以單步除錯的。
monophone 單音素訓練, tri1 三因素訓練, trib2 進行 lda_mllt 特徵變換,trib3 進行 sat 自然語言適應
tri1 下,final.mdl,這個就是有用的東西,學出來的模型。
graph_word 下,找到 words.txt,和 HCLG.fst,一個是字典,一個是有限狀態機
HCLG.fst:解碼圖(有限狀態機),利用先前建立的語言模型和上步訓練的聲學模型構建HCLG解碼圖。
步驟是固定的:mono,tri1,tri2,tri3.不能因為tri1訓練解碼效果不好,就跳過它,因為後面都是基於前面
-
mono:train_mono.sh 用來訓練單音子隱馬爾科夫模型,一共進行40次迭代,每兩次迭代進行一次對齊操作
tri1:三音素。train_deltas.sh 用來訓練與上下文相關的三音子模型
tri2:tri1上加上lda + mllt。用來進行線性判別分析和最大似然線性轉換
tri3:再加上說話人自適應Speaker Adapted Training (SAT),。用來訓練發音人自適應,基於特徵空間最大似然線性迴歸
quick:用來在現有特徵上訓練模型。
對於當前模型中在樹構建之後的每個狀態,它基於樹統計中的計數的重疊判斷的相似性來選擇舊模型中最接近的狀態。然後評價模型的效果,需要識別出一批資料,然後計算word error rate (wer)詞錯誤率,kaldi裡面有個 local/score.sh
./run.sh 之前,要先. ./path.sh一下
egs/sre08、sre10、sre16、lre、aishell/v1:說話人識別
-
tri*_ali:align對齊
*.txt:是OpenFst格式裡的符號表symbol tables,比如words.txt。
map:對映的意思。Use Vector Quantization (VQ) to map each speech feature to one symbol (out of typically around 256).
使用代理關鍵詞以處理表外詞(OOV)
steps/make_mfcc.sh 特徵提取
steps/compute_cmvn_stats.sh 計算每條wav檔案的均值方差
utils/mkgraph.sh (HCLG)(建立完全的識別網路,輸出是一個有限狀態轉換器。每次訓練出一種新的種類模型後都需要執行該指令碼生成識別網路。)
steps/align_si.sh 執行指定模型對指定資料進行對齊,一般在新的模型開始訓練前呼叫,上一個版本訓練的模型作為輸入
steps/train_deltas.sh triphon 訓練三因素繫結
steps/decode.sh 解碼資料,使用命令gmm-latgen-faster, gmm-decode-faster, compute-wer
.si字尾:speaker independent ,比如decode_test_phone.si
decode_test_phone_it3:_it迭代
-
LSTM + CTC
該演算法也是開源的,在
eesen(基於Kaldi的LSTM語音識別工具)裡。kaldi裡面的演算法都是:
DNN +HMM hybrid 模型 -
fst:加權有限狀態
kaldi解碼過程
kaldi識別解碼一段語音的過程是:首先提取特徵,然後過聲學模型AM,然後過解碼網路HCLG.fst,最後輸出識別結果。
HCLG是解碼時的重要組成部分。HCLG.fst是由4個fst經過一系列演算法(組合、確定化和最小化等)組合而成的。
4個fst分別是H.fst、C.fst、L.fst和G.fst,分別是HMM模型、上下文環境、詞典和語言模型對應的fst。fst視覺化的兩個基本命令
stprint和fstdraw是視覺化用到的兩個基本命令
fstprint用於列印fst,可以將二進位制的fst以檔案形式打印出來。Fstprint的基本用法如下
fstprint [–isymbols=xxxx –osymbols=xxxx ] FST
引數—isymbols和—osymbols分別表示輸入符號表和輸出符號表,這兩個引數可以省略。
fstdraw用於畫fst圖,其使用方式跟fstprint類似。Fstdraw得到的結果是dot檔案,通過dot命令轉為ps格式,然後可以由ps2pdf命令轉為pdf文件。stdraw使用示例
fstdraw [--isymbols=phones.txt --osymbols=words.txt] L.fst | dot –Tps | ps2pdf – L.pdf
1
.mdl 檔案 (P117)
copy-tree --binary=false exp/mono/tree - | less
1
轉移狀態 (P119)
訓練前的初始狀態show-transitions data/lang/phones.txt exp/mono/0.mdl
1
為了增加可讀性,輸入:show-alignments data/lang/phones.txt exp/mono/40.mdl exp/mono/40.occs | less
1
(.occs 檔案是指 occupation counts)檔案名錶示
檔名可以被“-”替代(“-”表示標準輸入輸出); 也可以被字串(如“|gzip -c >foo.gz” or “gunzip -c foo.gz|”)來替代(rspecifier、wspecifiers)。命令用法
1.
timit=/Users/yelong/kaldi/egs/timit/data
local/timit_data_prep.sh $timit || exit 1這裡.sh後面怎麼接了一個路徑呢,原來這個路徑引數是作為傳進.sh的引數傳進去(就是.sh裡的$1)。
2.
一般執行了exit 1說明有問題,前面語句有問題才會執行這句;而exit 0說明沒問題,類似return 0。 -
spk2gender 包含說話人的性別資訊
- spk2utt 包含說話人編號和說話人的語音編號的資訊
- text 包含語音和語音編號之間的關係
- utt2spk 語音編號和說話人編號之間的關係
- wav.scp 包含了原始語音的路徑資訊等 -
train_mono.sh 用來訓練單音子隱馬爾科夫模型,一共進行40次迭代,每兩次迭代進行一次對齊操作
train_deltas.sh 用來訓練與上下文相關的三音子模型
train_lda_mllt.sh 用來進行線性判別分析和最大似然線性轉換
train_sat.sh 用來訓練發音人自適應,基於特徵空間最大似然線性迴歸
nnet3/run_dnn.sh 用nnet3來訓練DNN,包括xent和MPE
用chain訓練DNN -
teps/make_mfcc.sh 特徵提取
steps/compute_cmvn_stats.sh 計算每條wav檔案的均值方差
steps/train_mono.sh monophon訓練
utils/mkgraph.sh (HCLG)(建立完全的識別網路,輸出是一個有限狀態轉換器。每次訓練出一種新的種類模型後都需要執行該指令碼生成識別網路。)
steps/align_si.sh 執行指定模型對指定資料進行對齊,一般在新的模型開始訓練前呼叫,上一個版本訓練的模型作為輸入
steps/train_deltas.sh triphon 訓練三因素繫結
steps/decode.sh 解碼資料,使用命令gmm-latgen-faster, gmm-decode-faster, compute-wer
-
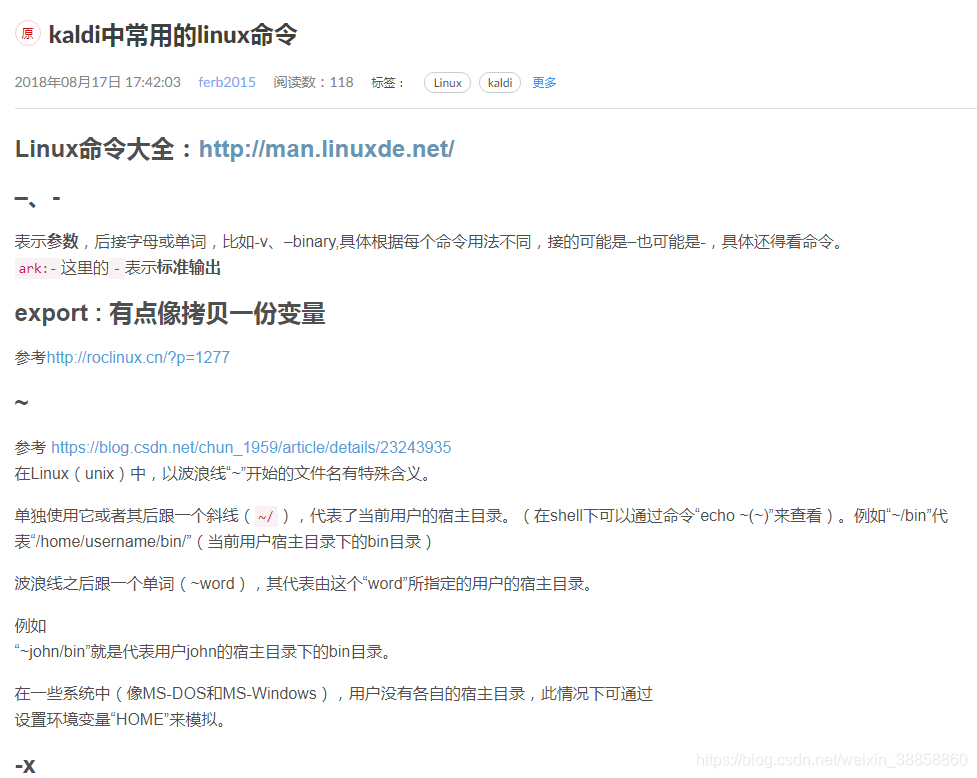
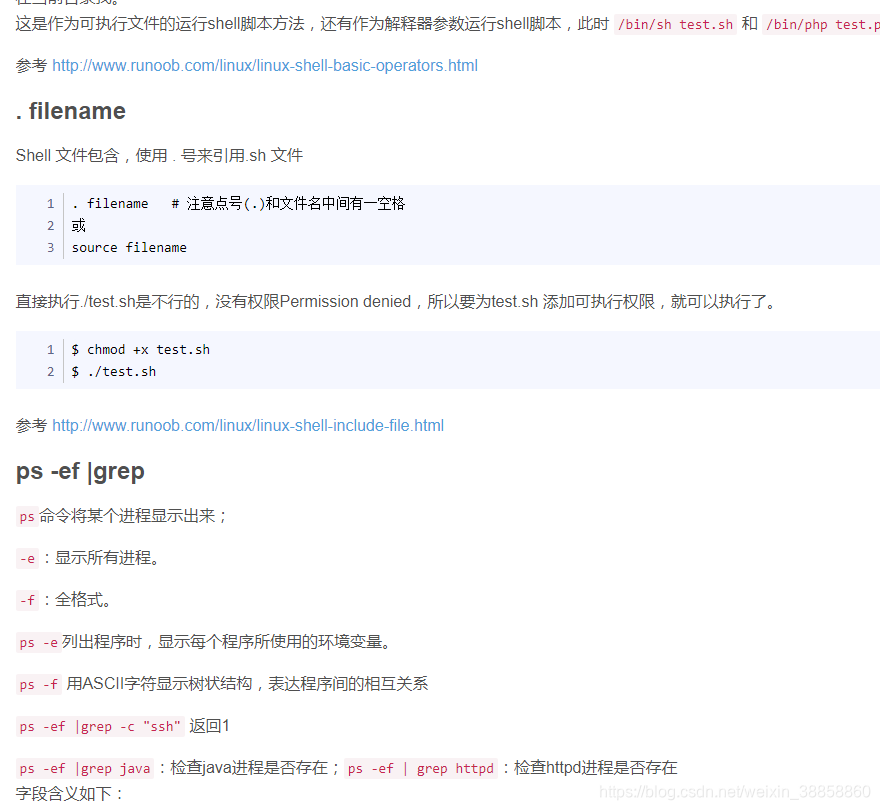
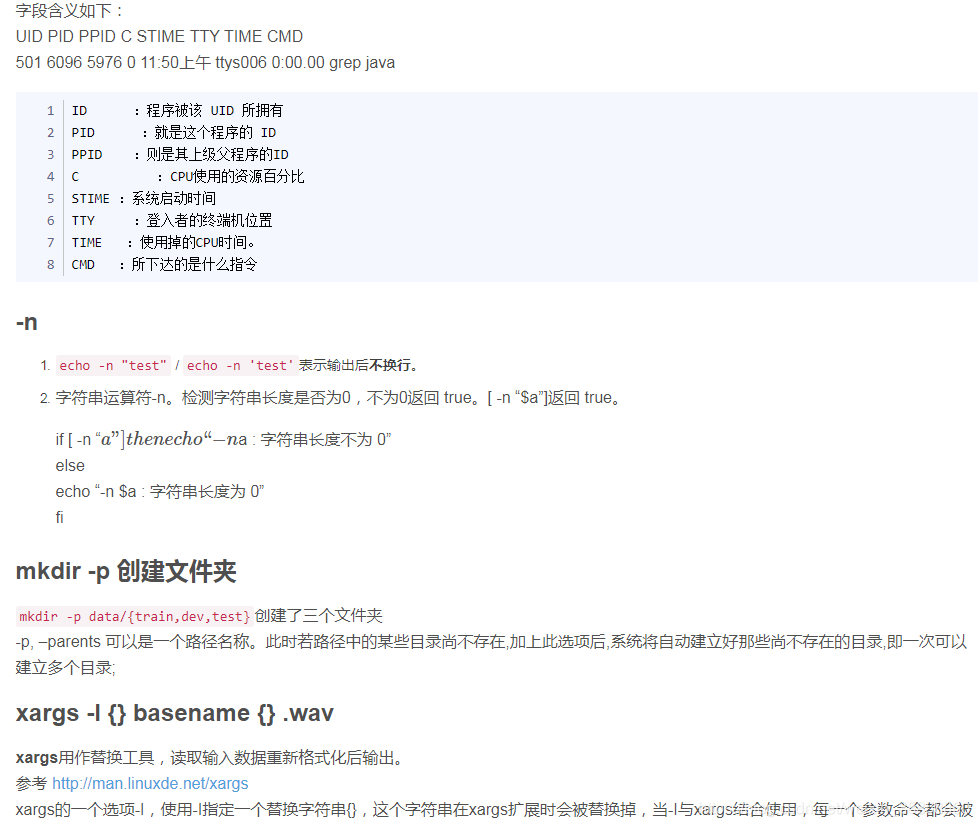
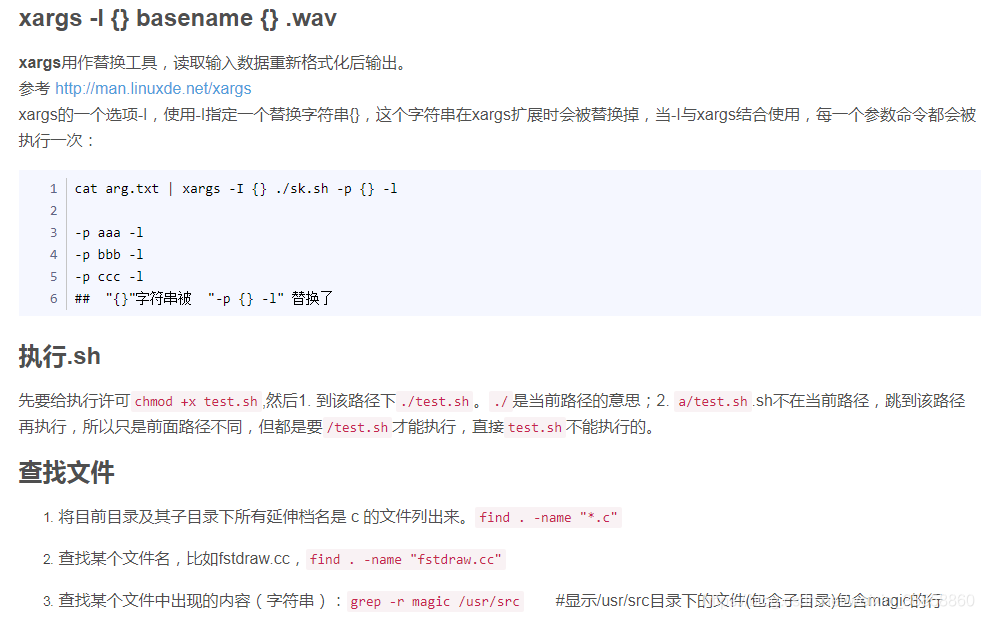
kaldi中常用的linux命令:https://blog.csdn.net/eqiang8848/article/details/81781230
-

-

-
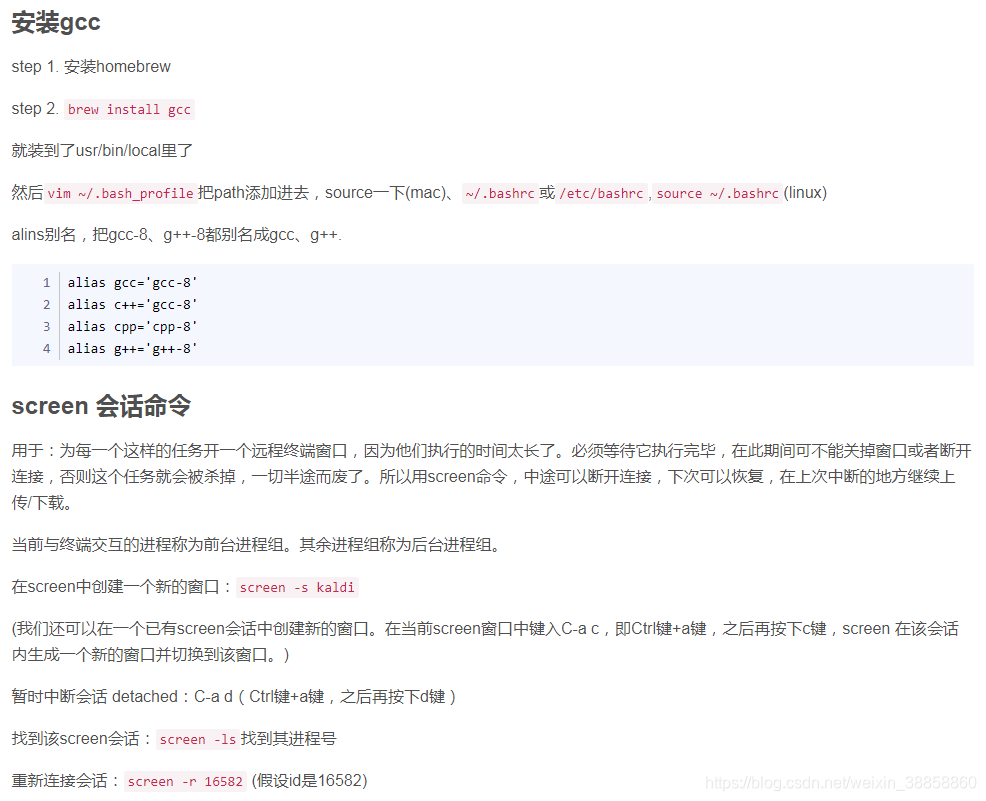
-

-

-
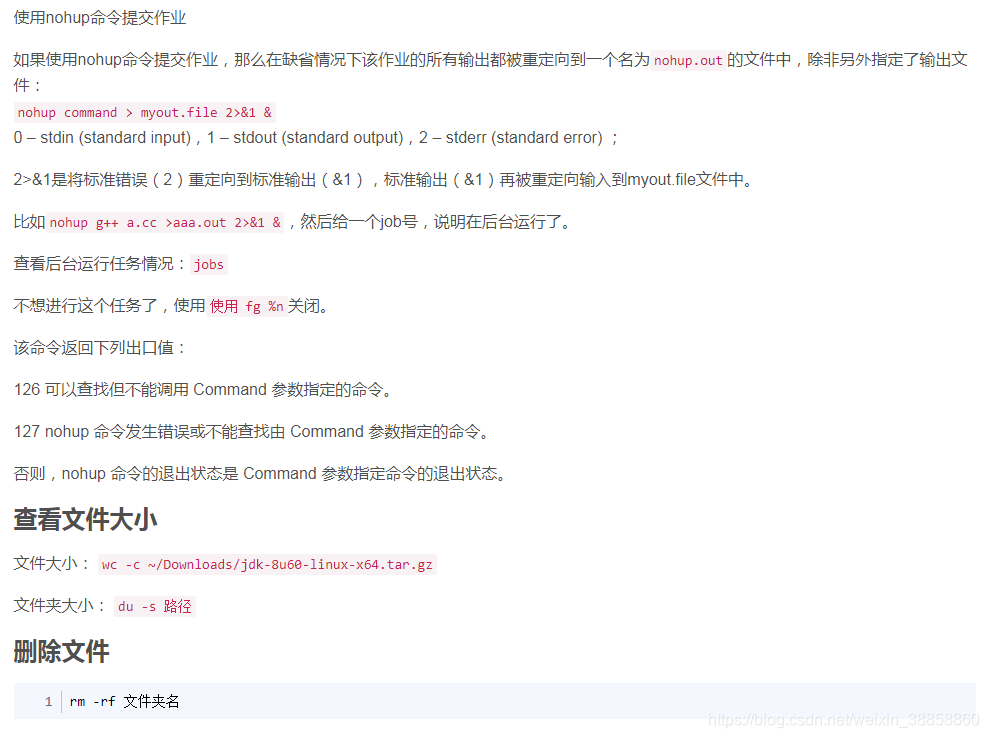
-

-

-

-
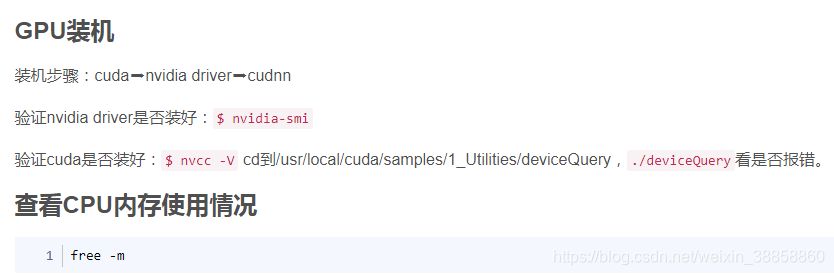
若path.sh是常規檔案就執行之:-f 判斷path.sh是否常規檔案,另,常見檔案判斷命令如下:
-e filename 如果 filename存在,則為真
-d filename 如果 filename為目錄,則為真
-f filename 如果 filename為常規檔案,則為真
-L filename 如果 filename為符號連結,則為真
-r filename 如果 filename可讀,則為真
-w filename 如果 filename可寫,則為真
-x filename 如果 filename可執行,則為真
-s filename 如果檔案長度不為0,則為真
-h filename 如果檔案是軟連結,則為真
filename1 -nt filename2 如果 filename1比 filename2新,則為真。
filename1 -ot filename2 如果 filename1比 filename2舊,則為真。
-eq 等於
-ne 不等於
-gt 大於
-ge 大於等於
-lt 小於
-le 小於等於
!非 -
compute_cmvn_stats.sh 是為了計算提取特徵的CMVN,即為倒譜方差均值歸一化!
-
參考:
1.https://blog.csdn.net/eqiang8848/article/details/81781370
2.https://blog.csdn.net/eqiang8848/article/details/81543599
3.https://blog.csdn.net/rooki_men/article/details/52163996