python高階(1)—— 基礎回顧
Python基礎回顧
認識變數
在學習了之前的Python零基礎入門系列【洗禮靈魂,修煉Python】(說明一下,這個系列現在回過來再來看這個名字確實好土啊,然後有些知識點感覺還不太精準,後期看如果有時間再調整下,名字的話就這樣了,不想改了,要改的話起碼得改大半天),相信你已經對Python有了一個大概的瞭解了。本系列是Python高階,所以先簡單回顧一下
變數及變數的作用
變數,顧名思義,變數,那當然是會變的量了。當然這麼說感覺有點枯燥,好,先看個例子:
計算某人每天的總支出,已知,早餐6塊,中餐15塊,晚餐15塊,交通費6塊,如果天氣炎熱,飲料費6塊
好的以上的價格按照生活常識的話都是不固定的,所以我們只是算個大概,開啟Python自帶的IDLE互動式工具(當然你也可以開啟pycharm之類的編輯器):

這樣,就計算出了結果了。
那麼問題來了,一個正常的人,每天遇到的情況也肯定有很多種,比如今天早上這人起得晚,沒吃早飯(早餐則成了0),然後因為趕時間去公司打了個車(交通費變得更多了),那麼這每天的支出就又要重新算一下了,又要重複上面的操作一次,這樣算多了則會帶來一系列的問題,比如中間有個式子算錯了,那麼全盤皆錯,而且還不方便後期進行修改和刪除一些資料,那這個問題有沒有個好點方法來節省下我們的運算量呢?
答案當然是有的,想一下,我們在學生時代,學解方程的時候是怎麼做的?設未知數為X對吧?然後根據條件寫出一個式子,然後就可以計算這個未知數真實的值了對吧?而在程式語言裡,也是有這個設未知數概念的,不過稍微有些不同,我們不會永遠都只用X,會用到很多,而這個設定的未知數則叫變數。
在上面這個晚起的情景裡,我們先設定breakfast = 0(即晚起沒吃到早餐),打車費為trans = 20,然後依次操作依次設定變數,最後我們再加起來:

結果計算出來了對吧?相信有朋友看到這裡還感覺不到變數的強大,那麼假如這個人沒有晚起,然後一切正常的,我們再用變數計算一次:

有朋友會覺得有點奇怪對吧?怎麼沒有把午餐,晚餐,飲料之類再加上呢?而且還算出來了,結果還是對的?
這就是變數的作用了,它可以臨時儲存值,並且這裡按照正常情況,我只需要改下breakfast 和trans 值,其他都不變就行了。所以到現在發現變數的作用了吧?如果你還不太懂,不急,後面開始通篇都會大量的使用變數,到時候自然會意會的。
上面的這種 breakfast(中文意思即為早餐)= 6 (這裡的符號“=”是賦值符號,不等同於數學裡的等於符號)到底是什麼意思呢,就是指把6這個值賦值給breakfast這個變數上,圖解:

我們可以直接呼叫變數訪問它的值,也可以用print列印它的值:

當然你也可以用del語句來刪除你定義的變數:

當用del語句刪除之後,再次呼叫這個變數時就會報錯提示該變數名未定義
那麼在所有的程式語言裡,把這個breakfast =6這個操作都稱為把6賦值給breakfast,這個操作其實在所有的程式語言裡都是兩個步驟:
-
宣告變數
-
定義變數
不過在Python中,您可能要注意兩點:
-
Python定義變數的同時則會把宣告變數和定義變數兩個步驟同時進行
-
Python的定義變數時,並不是簡單意義上的賦值,而是引用變數
什麼是變數引用
先看個例子:

這幾行的意思是,a=4,那麼此時a的值即為4,接下來我又讓a=6,此時a的值即為6,但b還是4,並沒有跟著a一起改變值,b重新等於8,a也不會跟著b改變,圖解:

注:當Python的某個物件的引用計數降為0時,說明沒有任何引用指向該物件,這個物件不久會被回收,回收這個物件的機制就是記憶體管理機制
這就是變數引用的特性,那麼通過以上,相信您應該理解什麼是變量了,變數的作用自然就是臨時儲存資料了
然而這變數定義是否是隨便我們定義的呢?好像看起來很隨意對吧?其實還是有個規範的,沒有規矩不成方圓
變數定義的規範
-
變數名可以是字母,數字,下劃線,但變數不能以數字開頭
-
嚴格區分大小寫
-
變數的名字儘量取專業的名字,做到顧名思義
其實定義變數還有個不成文的規定,不能使用中文和拼音命名,雖然也可以用中文或者拼音來命名,但是請您千萬不要這麼做,這是很low的表現:

上面的變數規範如果您不相信,那麼你可以試試:

這個紅色不是我把它標紅的,它自己紅的,出現這個相信您已經知道這是報錯的意思,那麼定義變數時真的不可以這麼操作的,你就記住定義變數只能是字母數字下劃線,而且字母不能作為開頭就行了:

數字和運算
前面我們用breakfast = 6定義變數並賦值,那麼你有沒有想,這裡的6有沒有什麼特殊的含義呢?當然是有的
數字/常量
前面的變數定義breakfast = 6,這個6就是數字,它還有另一個名字——常量
那麼這個常量有什麼可說的呢?首先大家都知道這個6是整數對吧,那麼肯定還有帶小數的或者分數,負數,複數之類的。而在Python中,這些數都有什麼名字呢?
資料型別:
-
整形數(int): 即整數,如1,2,-1,-2
-
浮點型(float): 即帶小數的數,如1.2,3.1415,-1.2,-3.1415
-
布林型(bool): 即1(True)和0(False)。(這個在流程控制會詳細講到,這裡暫且不提)
- 複數型:即帶“j”的數字就是複數型(其實複數用得不多,作為了解即可)

其實資料型別還有長整型(long)和定點型(double),長整型是Python2裡特有的概念,實質上它還是整數,因為Python2當時可表示的數值位數有限,所以有長整型的概念,而現在Python3裡都通稱為整型了。
定點型其實也是帶小數的數,實質上和浮點型沒多大區別,並且幾乎用不到的。
那麼,我們知道這些資料型別之後,怎麼檢視一個數或者一個變數的資料型別呢?
Python給我們分配了兩元大將——type函式和instance函式
type函式:

所以我們可以得出結論:type函式會返回變數的資料型別
instance函式:

報錯提示,指這個isinstance需要傳入兩個引數,而我們只傳入了一個引數,所以報錯,那麼我們這裡只有一個引數啊,為了檢視變數型別的,查閱幫助文件得:

那麼根據這個幫助文件,isinstance後面傳入的引數是資料型別(int,float等)
好我們再試試看:

那麼這裡我們又可以得出結論:isinstance它會返回一個bool型別,如果是對的,那麼就是true,否則就是false。
簡單運算(運算操作符)
1).算術操作符:
有了以上的知識,相信各位已經摩拳擦掌準備體驗一下了,好的,我們隨便測試幾個看看:

以上這些就是簡答的加(+)減(-)乘(*)除(/)了
2).比較操作符 (> 大於,>= 大於等於,< 小於,<= 小於等於,== 等於,!= 不等於)
3).邏輯操作符 (in 屬於,or 或,and 且,not in 不屬於,is 等同於)
4).冪運算/開根運算 (**,sqrt)

上面這個就是冪運算了。那麼開根運算是什麼呢?
這裡就需要匯入一個math模組裡的sqrt函式,這個sqrt函式就是開根的作用,它是Python自帶的模組,我們只需要import匯入就行了,好的我們開始用這個模組來開根:


5).按位運算
按位運算,那麼什麼是位呢?
這裡的位指的是二進位制位,按位運算就按位是指將一個數字轉換為標準的8位二進位制,然後這些二進位制按位操作運算。
&:按位與運算:按位相同則取1,不同取0
例: a=7&18
7 二進位制為111 轉為標準8位二進位制 00000111
18 二進位制為10010 轉為標準8位二進位制 00010010
兩個作與運算得: 00000010
最終結果為2
|:按為或運算:按位其中一位位1則取1,都不為1則取0
例: a=7|18
7 二進位制為111 轉為標準8位二進位制 00000111
18二進位制為10010 轉為標準8位二進位制 00010010
兩個作與運算得: 00010111
最終結果為23
^:按位異或運算:按位不同則取1,相同取0
例: a=7^18
7 二進位制為111 轉為標準8位二進位制 00000111
18二進位制為10010 轉為標準8位二進位制 00010010
兩個作與運算得: 00010101
最終結果為21
~:按位翻轉,即~x=-(x+1)
例: a=~18 ~18=-(18+1)
結果為-19
<<:按位左移,比如18即為00010010,左移一個單位00100100
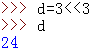
>>:按位左移,比如18即為00010010,左移一個單位00001001
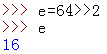
其他操作符:就是小括號和正負號(+,-,注意這裡不等同於加減號),但是他們的優先順序很高
好的,以上就是各種運算了,那麼相信聰明的你一定想到一個問題,現在這麼多種不同的操作符,如果都放在一起計算,怎麼知道先算誰後算誰呢?這個確實是個問題,所以這就有了運算優先順序了
運算優先順序
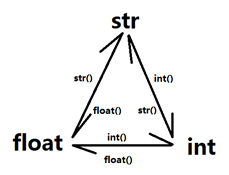
這裡直接用一個圖來解釋,三角形由上到下,依次優先順序由高到底
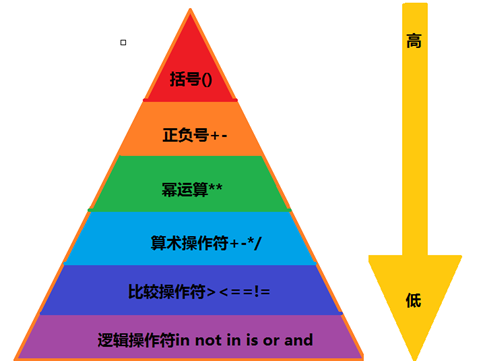
這裡用一個例子說一下為什麼正負號在冪運算優先順序之上:

字串和輸入輸出
什麼是字串
凡是用‘’(引號)引起來的都叫字串,比如:

這個引號可以是單引號(’’),也可以是雙引號(“”),也可以是三引號(’’’’’’)
注意:三種形式的引號必須成對出現,不然報錯:

報錯提示就是說你的符號沒有一個合理的結尾,換句話就是你的符號沒有成對出現。
並且字串也是資料型別的一種,所以資料型別到現在我們學的資料型別有:int,str,float
那麼這裡就有個很重要的知識點
資料型別轉換:
1).整形轉字串:用str函式轉換

2).整形轉浮點型:用float函式

3).字串轉整形:用int函式
注意:字串轉整形有個前提,字串裡本身是個數字,不然報錯

三種不同資料型別之間的轉換圖解:
建立字串的方法:
1).直接使用引號:
這個上面已經說了 例:’python’
2).用函式str()

利用str函式來建立函式,括號內可以是數字,也可以是字串,但不能是未定義的變數:

字串操作
字串是什麼前面大家都瞭解了吧,字串在Python中是個很重要的概念,它是一個數據型別(前面的int,float,str),又是一個數組型別(即一個容器,可以存放多個數據的型別),還是一個物件,既然是一個物件,則會有很多方法、屬性操作
以下是Python3下字串的所有方法

注:由於字串的方法太多,下面就簡單講解幾個非常常用的方法就行,望各位看官耐心看下去
captalize:把整個字串的第一個單詞的首字母大寫並返回

注意:
1).這裡使用了字串的方法後,其實並不會修改test自身,只是返回了一個結果,如果需要修改test,則將修改後的結果重新賦值:

2).使用字串的方法是最後要加“()”,沒有什麼特別的意思,這就是Python規定的
casefold:把整個字串的所有字元改為小寫,python3裡特有的

center(width):把字串居中,並使用空格填充至長度 width 的新字串

count(sub[, start[, end]]):返回 sub 在字串裡邊出現的次數,start 和 end 引數表示索引範圍
索引即下標,從0開始。

上面這個test,其值對應索引就是下面的數字
比如這裡test = "abcdfjack":通過索引就可以單獨取出資料


這裡count方法裡的1,4就是索引為止,由於索引1到4並沒有‘a’,所以返回0
decode(decode='strict'):把已知的編碼方式解碼為Unicode
encode(encoding='utf-8', errors='strict'):以 encoding 指定的編碼格式對字串進行編碼
endswith(sub[, start[, end]]):檢查字串是否以 sub 子字串結束,如果是返回 True,否則返回 False。start 和 end 引數表示範圍

startswith(prefix[, start[, end]]):檢查字串是否以 prefix 開頭,是則返回 True,否則返回 False。start 和 end 引數可以指定範圍檢查

expandtabs([tabsize=8]):把字串中的製表符(即一個tab鍵位置,相信前面第一章裡Python的語法規則你已經學過了),\t轉換為空格,如不指定引數,預設的空格數是 tabsize=8

這裡由於都是空白的看不出效果,它確實是已經把\t轉為空格了
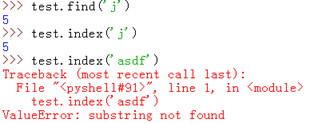
find(sub[, start[, end]]):檢測 sub 是否包含在字串中,如果有則返回索引值,否則返回 -1

rfind(sub[, start[, end]]):原理同 find() 方法,不過是從右邊開始查詢
foramt:格式化字串

index(sub[, start[, end]]):跟 find 方法一樣,不過如果 sub 不在 string 中會產生一個異常
rindex(sub[, start[, end]]):同理index() 方法,不過是從右邊開始
isalnum():如果字串至少有一個字元並且所有字元都是字母或數字則返回 True,否則返回 False

isalpha():如果字串至少有一個字元並且所有字元都是字母則返回 True,否則返回 False

isdecimal():如果字串只包含十進位制數字則返回 True,否則返回 False,這是python3特有

isdigit():如果字串只包含數字則返回 True,否則返回 False

isnumeric():如果字串中只包含數字字元,則返回 True,否則返回 False,同理isdigit方法相同
islower():如果字串中至少包含一個區分大小寫的字元,並且這些字元都是小寫,則返回 True,否則返回 False

isspace():如果字串中只包含空格,則返回 True,否則返回 False

istitle():如果字串是標題化(所有的單詞都是以大寫開始,其餘字母均小寫),則返回 True,否則返回 False

isupper():如果字串中至少包含一個區分大小寫的字元,並且這些字元都是大寫,則返回 True,否則返回 False

join(sub):以字串作為分隔符,插入到 sub 中所有的字元之間

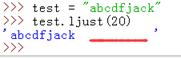
ljust(width):返回一個左對齊的字串,並使用空格填充至長度為 width 的新字串
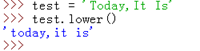
lower():轉換字串中所有大寫字元為小寫。
partition(sub):找到子字串 sub,把字串分成一個 3 元組 (pre_sub, sub, fol_sub),如果字串中不包含 sub 則返回 ('原字串', '', '')

rpartition(sub):同理partition() 方法,不過是從右邊開始查詢
replace(old, new[, count]):把字串中的 old 子字串替換成 new 子字串,如果 count 指定,則替換不超過 count 次

rjust(width):返回一個右對齊的字串,並使用空格填充至長度為 width 的新字串,同理ljust
split(sep=None, maxsplit=-1):不帶引數預設是以空格為分隔符切片字串,如果 maxsplit 引數有設定,則僅分隔 maxsplit 個子字串,返回切片後的子字串拼接的列表

splitlines(([keepends])):按照 '\n' 分隔,返回一個包含各行作為元素的列表,如果 keepends 引數指定,則返回前 keepends 行

strip([chars]):刪除字串前邊和後邊所有的空格,chars 引數可以定製刪除的字元,可選

lstrip():去掉字串左邊的所有空格
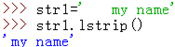
rstrip():去掉末尾(右邊)的空格,同理lstrip(),strip()
swapcase():翻轉字串中的大小寫

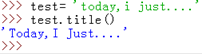
title():返回標題化(所有的單詞都是以大寫開始,其餘字母均小寫)的字串
translate(table):根據 table 的規則(可以由 str.maketrans('a', 'b') 定製,maketrans方法是python特有,用的較少)轉換字串中的字元

這個方法和replace方法很類似,個人建議直接使用replace,這個translate步驟太多了。
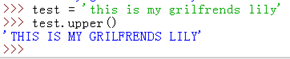
upper():轉換字串中的所有小寫字元為大寫
zfill(width):返回長度為 width 的字串,原字串右對齊,前邊用 0 填充

以上就是常用的字串方法了,當然還有很多字串方法,感興趣可以自己去研究了,掌握了上面的方法都夠你處理日常任務了
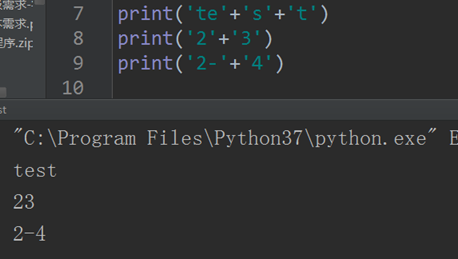
字串拼接:+
字串也可以拼接起來:
除了用“+”還可以用‘,’號,但並不是真正意義的拼接,且中間會有一個空格

但記住一定不是加起來,而且不同型別的是不能拼接的,會報錯:

簡單輸入輸出
1).print輸出
當然就是前面你已經用到的print了。在Python2裡,print是一個語句。在Python3裡,print是一個函數了,既然是函式,自然就還有其他功能了。先看文件:

Sep引數很少用,你可以忽略不計,end引數倒是經常用。
不管在Python2還是3裡面,都是作列印而已,但是在列印的同時,print會自動加一個換行符(\n)換行
請看,我這什麼都沒列印,還是換了一行。(我用的是Python3)

好的,此時我用end引數就可以修改預設的換行符:
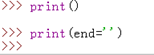
我把end引數等於一個空字串後,print不再自動換行了,後期你可能還會遇到換成其他字元的,比如換成一個分隔符,佔位符等等的。
說到,那不得不提一個知識——轉義符“\”
這個轉義符有什麼用呢?它有兩個作用:
-
邏輯斷行
-
轉義特殊字元
邏輯斷行:
先看例子:

由於因為內容太多,一行放不完,這時我們就可以用\在結尾作邏輯斷行:

但是對於Python而言,它發現你用了‘\’作邏輯斷行它就知道這上下其實是一行。
轉義特殊字元
我們先看個例子,列印一個檔案路徑:

乍一看好像沒什麼問題對吧?是的,這個它確實沒問題,嘻嘻。
那麼再看下這個路徑呢:
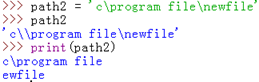
發現換行了對吧,因為什麼呢?因為它把”file\newfile”裡的”\n”當成一個換行符並轉義成換行符了,所以會換行。
那麼我們不想讓它這樣呢?辦法是有的,換行符關鍵的就是這個反斜槓(\)嘛,它自身是一個換行符,那我讓轉義自己呢:

可行,問題已解決。
那麼假如說我這個檔案路徑很長呢:path3 = 'c\now\now\now\new\new\now\new....'
這裡你就可以使用原始字串——‘r’了:

好的,這個問題解決了
那麼如果這個字串結尾處剛好是一個轉義符又怎麼樣呢:

用原始字串的方法不行,怎麼辦呢?除了結尾處,前面的我們都用原始字串解決了對吧?那麼把這結尾單獨轉義一下唄:

其他的轉義符:(暫且不用記,用到的時候再回過來看,用多了就記住了)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
input輸入
學完前面的知識,相信你已經越來越覺得上面那些功能不夠你用了,總是很死板的設定一個變數值,然後做個運算或者轉換處理然後輸出,你可能漸漸覺得這樣有點low了對吧,你想用更高階點的語法,因為你發現市面上很多軟體或者網站都有讓使用者自己輸入的選項,使用者輸入什麼,這個資料它就永遠是什麼。那麼Python裡有沒有這個功能呢?那當然是有的,這個功能就是Input函式的功能
當我們敲下input()時回車:
空白處就是需要使用者自己輸入,輸入什麼它就會返回什麼:

那麼這個值我們自然也可以用變數臨時儲存起來:

注意:在Python3中input函式會把你輸入的任何資料自動轉為字串:

那麼有朋友想到個問題,既然input會自動轉為字串,那麼我就是要整形怎麼辦呢?簡單,型別轉換啊:

在Python2中,input輸入什麼這個值就是什麼型別,也就是說你要提前設定資料型別:

為什麼報錯呢,是因為input它不識別你這“asdf”,發現“asdf”是未定義的值
所以要加引號才行:

所以如果你使用的時Python2的話怎麼辦?Python2裡有個raw_input函式:

換句話說,Python2中的raw_input等同於Python3裡的input
其實input函式還可以作提示的:
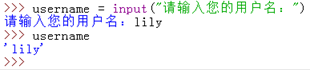
有提示也有輸入,這才是真正的與使用者達到互動式了。那麼我們可以得出結論,input函式即有輸入也有輸出的功能
字符集編碼
學完上面的字元資料操作,相信聰明的你想過這些字元資料是怎麼存放在磁盤裡的對吧?從第一章的計算機常識裡你已經得知計算機只認二進位制了,那麼存放字元資料自然也是二進位制,接著又帶來一個新的問題,現在全國各地的程式設計師,由於語言的不同,存都是二進位制,然而要用的時候,一定有一個大家默許的規則,不然會造成不堪的後果。這個規則就是編碼了。
字符集編碼介紹
什麼是編碼
編碼是國際定義的標準,簡單的理解就是計算機中儲存資料的格式,在計算機中資料都是以二進位制的0和1來進行儲存,所以為了把二進位制轉換為人類可以理解的內容就需要編碼來進行轉換。而人類寫的字元要讓計算機識別,也需要轉換編碼。
並且高階開發語言,都需要直譯器解釋為機器可以認識的字元。
編碼的起源歷史
最早出現編碼是美國的ASCII,但是ASCII只有26個英文字母以及一些標點符號,歐洲國家為了更方便的使用,也設計了一套EASCII,包含了拉丁字元,慢慢的中國計算機行業發展起來後也設計了一套編碼GB2312,收錄了大部分常用簡體字,並且包括日韓文裡使用的漢字,臺灣同胞因為使用繁體字,也設計了一套編碼big5。後面國人希望統一一下,在BG2312之上做了個升級版GBK,收錄更多的簡體字,包括了繁體字以及少數名族的使用的文字;日本和韓國也都各自設計了自己的一套編碼。然後很多國家都有了自己的一套的編碼。
所以市面上就有了一大批的編碼,國與國之間交流也困難,那麼既然我們人與人之間交流需要一個通用的語言,計算機界也有了這麼一套通用語言,最後國際協會決定統一下編碼,推出一套萬國碼——Unicode,整合了全球所有的編碼,可以直接支援全球所有的語言,就像英語是全球通用的語言一樣了,並且Unicode直接解決了字元與二進位制之間的對映關係,不用再考慮不同語言的存取問題了。
不過Unicode還有一個問題,由於Unicode字符集是一個字元佔2-4位元組的,由於最開始使用ASCII時一個字母是隻佔一個位元組的,這樣就很浪費空間了(比如‘age’這個單詞使用Unicode需要佔6個位元組,但使用ASCII碼只佔3個位元組)。所以國際協會又想了一招,做了個優化,出現了一個新的編碼——UTF-8,UTF-8預設使用1個字元,不夠則增加,最多4個位元組。英文佔1個位元組、歐洲語系佔2個、東亞佔3個,其它及特殊字元佔4個。
注意:
-
UTF-8還是屬於Unicode,只是Unicode其中一個優化版本,其實還有其他UTF-16,Utf-32之類的。
-
UTF-8編碼英文只佔1一個位元組,中文佔三個位元組
-
GBK、GB2312編碼下中文僅佔兩個位元組,所以國內很多公司或者網站還是使用的GBK或BG2312
python2和python3的編碼
瞭解完字符集編碼,是不是覺得很簡單,先別這麼認定,因為它可是最容易出問題的,並且在Python中這個編碼問題一直是老生常談的問題,很多程式設計師在工作之後好幾年都沒有真正理解字元編碼,還有一部分程式設計師自認為自己理解了,當在開發中才發現其實並沒有真正理解。
在Python3裡是Unicode編碼,Python2裡是ASCII編碼(當時Python2出現時還沒有Unicode編碼)
現在我們看下Python2和Python3下不同的編碼,開啟作業系統的終端進入python:
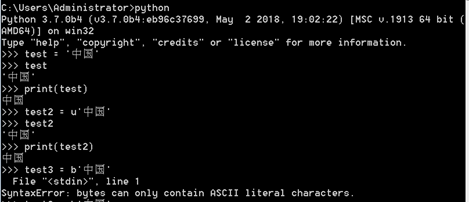

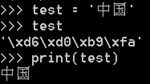
在宣告字串時在前面加u表示以Unicode形式,加b表示以bytes形式。Python3裡用b轉位元組報錯其實是對的,這裡下面會解釋
看到上面的簡單例子,確實發現Python兩個版本的編碼不同了吧。'\xd6\xd0\xb9\xfa'這個是16進位制的位元組,這裡要說一下,我們知道二進位制由於太長比如00101110011之類,要表示一個數據的位元組太長了不方便,所以儲存是的的確確以二進位制儲存的,只是用十六進位制來表示。那麼這裡有個問題,就算Python3預設是unicode但是不管怎麼列印還是一樣的,那麼就可以肯定,Python3一定自動幫我們做了編碼解碼操作。而Python2裡沒有自動幫助我們,在Python兩個版本里都有一個解碼(decode)和編碼(encode)方法,也就是前面字串操作裡的這兩個方法,在這裡就要派上用場了,我們就可以用這兩個方法手動編碼解碼:
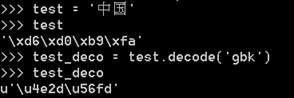
decode方法需要給一個引數,這個引數必須字元之前的字元編碼匹配,所有的位元組解碼都會解碼成Unicode
比如這裡的‘中國’,我們用gbk就正確解碼了。但是有朋友要問了,我們這裡沒有給字符集編碼它怎麼自己就儲存成gbk編碼了,因為我這裡使用的是windows的cmd終端,這個終端預設是使用gbk的,所以給存成gbk了。使用chcp命令可以檢視得知:936即代表gbk編碼了

不信的話可以用encode方法驗證:

這裡編碼成gbk之後確實和最初的test一樣的。
encode方法需要給一個引數,這個引數可以是任意字符集編碼
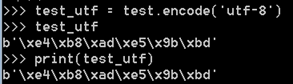
既然可以編碼成任意字符集編碼,編譯成utf-8和之前的對比:

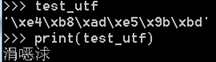
這個“涓x浗”是啥啊?這個其實就是亂碼了,為什麼呢?因為Python2裡的print語句會帶有一點讀取的意思,所以讀取的時候由於“中國”本來就是gbK的(windows的cmd終端自動設定了),這裡解碼成unicode之後編碼成utf-8肯定不識別啊,因為沒有對應的編碼集可以正確解碼,只是剛好在編碼集裡有這些字符集被錯誤解釋出來了,但是是毫無意義的字元。有朋友想到了,前面不是說已經支援中文了嗎?確實支援了,但是支援的是Unicode啊,utf-8並不是支援,雖然utf-8也是unicode裡的一個分支。而上面的test_deco就是unicode啊,print的時候是正常的。
那麼Python2為什麼會造成這種不可思議的問題呢?先看下型別看看呢:

這什麼情況?test是gbk的位元組,test_utf是utf-8的位元組,怎麼會顯示的型別是字串呢?答案是Python2裡bytes = str,是的在Python2里居然把位元組和字元等同了(前面我們說了位元組和字元完全是不同的),這就是最根本的問題所在,而且還有一種新的字元型別unicode。這樣也側面說明了Python2裡字元型別只有str和unicode
而Python3裡:

由於Python3裡字串方法裡已經不存在decode方法(因為已經預設是unicode編碼了)
編碼為utf-8之後看下型別:
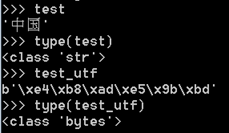
Python3裡是一切正常的,因為編碼本來就會變成位元組,然後交給計算機處理,我們要檢視和使用時再解碼的,這裡沒有Python2那麼特殊。
所以可以得出結論:Python3裡的字元型別是str和bytes,python3裡btyes就是bytes,並不像Python2裡bytes等同於str,且python2裡的Unicode等同於Python3裡的str
總結
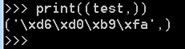
在python2裡,本來儲存的是位元組,print時會成為str
但轉為元祖型別就顯原型,在日後的操作時如果遇到這樣的情況,使用for迴圈或者利用陣列型別取資料的方法取出來就行:
如果在後期遇到編碼問題時你仍是無法理解,不知道怎麼解決,你可以使用Python3操作,問題立馬解決。
使用編輯器操作時,通常會在檔案開頭加一行此程式碼:# coding:utf-8定義一個統一編碼,表示此檔案裡通用該編碼:以防出現不可避免的問題