
機器學習筆記(九):Tensorflow 實戰一 (Tensorflow入門)
1 - TsensorFlow計算模型 ——計算圖
1.1- 計算圖的概念
計算圖是TensorFlow中最基本的一個概念,TensorFlow中的所有計算都會被轉化為計算圖上的節點。
在TensorFlow中,張量可以簡單地理解為多為陣列。如果說TensorFlow的第一個詞Tensor表明了它的資料結構。那麼Flow則體現了它的計算模型,Flow翻譯成中文就是“流”,它直觀地表達了張量之間通過計算相互轉化的過程。
TensorFlow是一個通過計算圖形式來表示計算的程式設計系統。TensorFlow中的每一個計算都是計算圖上的一個節點,而節點之間的邊描述了計算之間的依賴關係
1.2 - 計算圖的使用
TensorFlow程式一般可以分為兩個階段
- 第一個階段需要定義計算圖中所有的計算。
- 第二個階段為執行計算
import tensorflow as tf a = tf.constant([1.0,2.0],name="a") b = tf.constant([2.0,3.0],name="b") result = a+b #通過a.graph可以檢視張量所屬的計算圖,因為沒有特意指定,這個計算圖應該等於當前預設的計算圖 #所以下面這個操作輸出值為True. print(a.graph is tf.get_default_graph())
True
2 - TensorFlow資料模型——張量
2.1 - 張量的概念
從TensorFlow的名字可以看出張量(tensor)是一個重要的概念。在TensorFlow程式中,所有的資料都通過張量的形式來表示。從功能的角度上按,張量可以被簡單的理解為多為陣列。
但是張量中並沒有真正儲存數字,它儲存的是如何得到這些數字的計算過程。
以向量加法為例:
import tensorflow as tf #tf.constant是一個計算,這個計算的結果為一個張量,儲存在變數a中。 a = tf.constant([1.0,2.0],name="a") b = tf.constant([2.0,3.0],name="b") result = tf.add(a,b,name="add") print(result)
Tensor(“add:0”, shape=(2,), dtype=float32)
-
張量的第一個屬性不僅是一個張量的唯一識別符號,它同樣也給出了這個張量是如何計算出來的。
-
張量的第二個屬性是張量的維度(shape),shape(2,)說明了張量result是一個一維陣列,一個數組的長度為2
-
張量的第三個屬性是型別(type),每一個張量會有一個唯一的型別。TensorFlow會對參與運算的所有張量進行型別的檢查。
2.2 - 張量的使用
張量使用主要可以總結為兩大類
**第一類:**對中間計算結果的引用,可以提高程式碼的可讀性。
**第二類:**當計算圖構造完成之後,張量可以用來獲得計算結果,也就是得到真實的數字。雖然張量本身沒有儲存具體的數字,但是可以通過會畫(session),就可以得到這些具體的數字。比如在上述程式碼中,可以使用tf.Session().run(result)語句來得到計算結果
3 - TensorFlow執行模型——會話
前面兩節介紹了TensorFlow是如何組織資料和運算的。本節將介紹如何使用TensorFlow中的會話(session)來執行定義好的運算。會話擁有並管理TensorFlow程式執行時的所有資源。
TensorFlow中使用會話的模式一般有兩種
**第一種:**需要明確呼叫會話生成函式和關閉會話函式,這種模式的程式碼流程如下。
#建立一個會話
sess = tf.Session()
#使用這個建立好的會話來得到關心運算的結果。比如可以呼叫sess.run(result)
##來的得到result 的取值
#關閉會話使得本次執行中使用的資源可以被釋放
sess.close()
但是使用這種模式時,因為是在最後呼叫Session.close函式來關閉會話並關閉資源。然而當程式因為異常而退出時,關閉會話的函式可能就不會被執行從而導致資源洩露。為解決異常退出時資源釋放的問題,TensorFlow可以通過Python上下文管理器來使用會話。
**第二組:**通過資源管理器來使用會話。
#建立一個會話,並通過Python中的上下文管理器來管理這個會話。
with tf.Session() as sess:
#使用者建立好的會話來計算關心的結果。
sess.run(...)
#不需要呼叫“Session.close()”函式來關閉會話
#當上下文退出時會話關閉和資源釋放也自動完成了。
通過Python上下文管理器的機制,只要將所有的計算放在“with”的內部就可以。當上下文管理器退出的時候會自動釋放所有資源。這樣既解決了因為異常退出時資源釋放的問題。同時也解決了忘記呼叫Session.close函式而產生的資源洩露。
4 - TensorFlow實現神經網路
上面3節從不同角度介紹了TensorFlow的基本概念。在這一節中,將結合神經網路的功能進一步介紹如何通過TensorFlow來實現神經網路。
4.1 - TensorFlow遊樂場及神經網路簡介
TensorFlow遊樂場http://playground.tensorflow.org
是一個通過網頁瀏覽器就可以訓練的簡單神經網路並實現了視覺化訓練過程的工具。預設截圖如下:
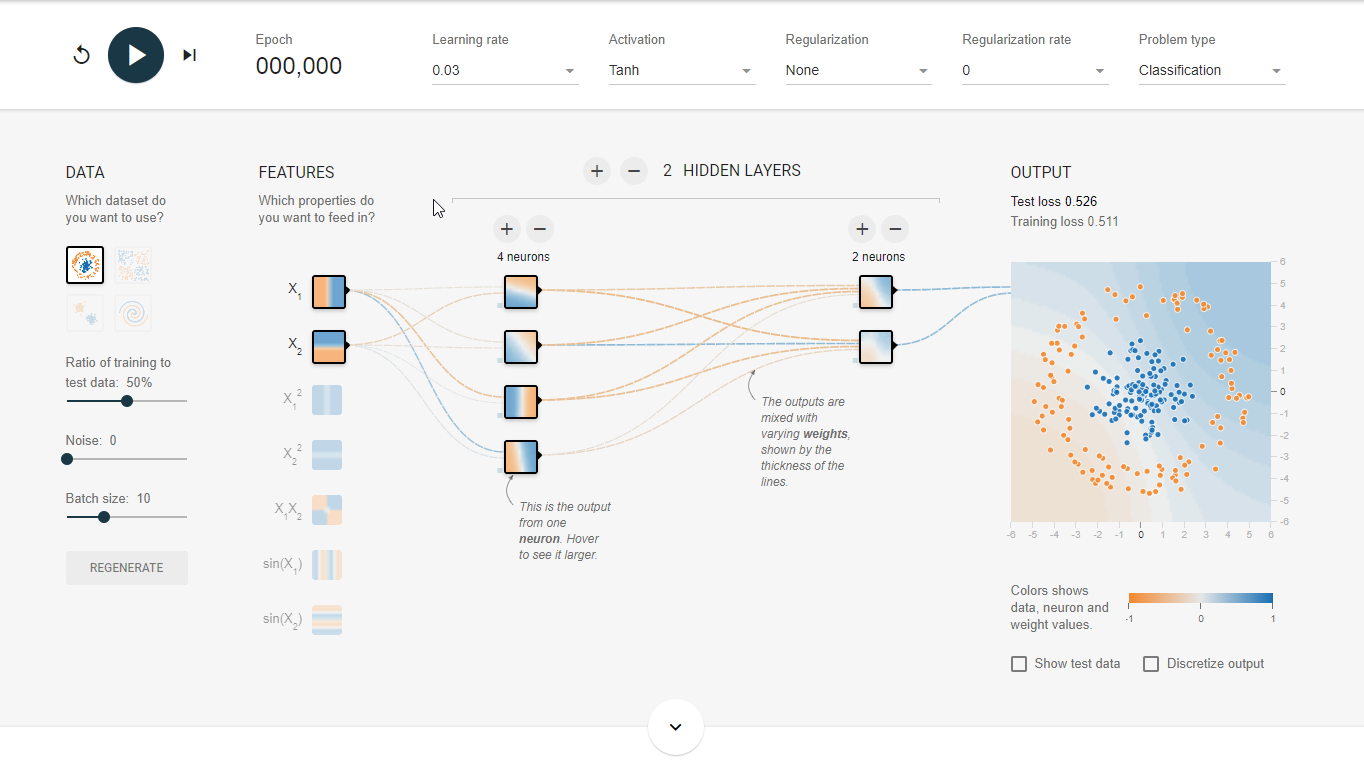
使用神經網路解決分類問題主要可以分為以下4個步驟:
1. 提取問題中實體的特徵向量作為神經網路的輸入。不同的實體可以提取不同的特徵向量。
2. 定義神經網路結構,並且定義如何從神經網路的輸入得到輸出。這個過程就是神經網路的前向傳播演算法
3. 通過訓練資料來調整神經網路中引數的取值,這就是訓練神經網路的過程
**4. 使用訓練好的神經網路來預測位置的資料 **
輸入資料placeholder機制
TensorFlow提供了placeholder機制用於提供輸入資料。
placeholder相當於定義了一個位置,這個位置中的資料在程式執行時再指定,
通過placeholder實現前向傳播演算法
import tensorflow as tf
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
w1 = tf.Variable(tf.random_normal([2,3],stddev=1))
w2 = tf.Variable(tf.random_normal([3,1],stddev=1))
#定義placeholder作為存放輸入資料的地方,這裡維度也不一定要定義。
#但如果維度是確定的,那麼給出維度可以降低出錯的概率
x = tf.placeholder(tf.float32,shape=(1,2),name="input")
a = tf.matmul(x,w1)
y = tf.matmul(a,w2)
sess = tf.Session()
init_op = tf.global_variables_initializer()
sess.run(init_op)
print(sess.run(y,feed_dict={x:[[0.7,0.9]]}))
[[0.07005829]]
在新的程式中計算前向傳播結束時,需要提供一個feed_dict來指定x的取值,feed_dict是一個字典(map),在字典中需要給出每個用到的placeholder的取值
在得到前向傳播結果之後,需要定義一個損失函式來刻畫當前的預測值和真實答案之間的差距。然後通過反向傳播演算法來調整神經網路引數的取值使得差距可以被縮小。損失函式和反向傳播演算法將在後面更加詳細地介紹。先定義了一個簡單的損失函式,並通過TensorFlow定義了反向傳播的演算法。
#定義損失函式來刻畫預測值與真實值得差距
cross_entropy = -tf.reduce_mean(y_*tf.log(tf.clip_by_value(y,1e-10,1.0)))
#定義學習速率
learning_rate=0.001
#定義反向傳播演算法來優化神經網路的引數
train_step=\tf.train_AdamOptimizer(learning_rate).minimize(cross_entropy)
在上面的程式碼中,cross_entropy定義了真實值和預測值之間的交叉熵(cross entropy)
第二上train_strep定義了反向傳播演算法的優化方法。目前TensorFlow支援7種不同的優化器,讀者可以根據具體的應用選擇不同的優化演算法。比較常用的優化方法有三種:tf.train.GradientDescentOptimizer、ft.train.AdamOptimizer和tf.train.MomentumOptimizer。在定義了方向傳播演算法之後,通過執行see.run(train_step)就可以對所有在GraohKeys.TRAINABLE_VARIABLES集合中的變數進行優化,使得當前下損失函式更小。
4.2 - 完整神經網路樣例程式
下面給出一個完整的程式來訓練神經網路解決二分類問題
import tensorflow as tf
from numpy.random import RandomState
#定義訓練資料batch的大小
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
batch_size=8
#定義神經網路的引數,這裡還是沿用之前所給的神經網路結構
w1 = tf.Variable(tf.random_normal([2,3],stddev=1,seed=1))
w2 = tf.Variable(tf.random_normal([3,1],stddev=1,seed=1))
#在shape的一個維度上使用None可以方便使用不大的batch大小。在訓練時需要把資料分成
#比較小的batch,當資料集比較小時一次性使用全部的資料方便測試
# 但是資料集比較大時,將大量資料放入一個batch可能會導致記憶體溢位
x = tf.placeholder(tf.float32,shape=(None,2),name='x-input')
y_=tf.placeholder(tf.float32,shape=(None,1),name='y-input')
#定義神經網路前向傳播的過程
a = tf.matmul(x,w1)
y = tf.matmul(a,w2)
#定義損失函式和反向傳播的演算法
cross_entropy = -tf.reduce_mean(y_*tf.log(tf.clip_by_value(y,1e-10,1.0)))
train_step = tf.train.AdamOptimizer(0.001).minimize(cross_entropy)
#通過隨機數生成一個模擬資料集
rdm = RandomState(1)
dataset_size = 128
X = rdm.rand(dataset_size,2)
#定義規則來給出樣本的標籤。這裡所有x1+x2<1的樣例都被認為是正樣本(比如零件合格)
#而其他為負樣本(比如零件不合格)。和TensorFlow遊樂場中的表示法不大一樣的地方是,
#這裡使用0來表示負樣本,1來表示正樣本。大部分解決分類問題的神經網路都會採用
#0和1的表示方法
Y = [[int(x1+x2<1)]for(x1,x2)in X]
#建立一個會話來執行TensorFlow程式
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
#初始化變數
sess.run(init_op)
print(sess.run(w1))
print(sess.run(w2))
#設定訓練輪數
STEPS = 5000
for i in range(STEPS):
#每次選取batch_size個樣本進行訓練
start = (i*batch_size)%dataset_size
end = (i*batch_size) % dataset_size + batch_size
#通過選取的樣本訓練神經網路並更新引數
sess.run(train_step,feed_dict={x:X[start:end],y_:Y[start:end]})
if i%1000 == 0:
total_cross_entropy = sess.run(cross_entropy,feed_dict={x:X,y_:Y})
print("After %d training step(s), w1 is: " % (i))
print(sess.run(w1), "\n")
print("total_cross_entropy is :",total_cross_entropy)
print("Final w1 is: \n", sess.run(w1))
[[-0.8113182 1.4845988 0.06532937]
[-2.4427042 0.0992484 0.5912243 ]]
[[-0.8113182 ]
[ 1.4845988 ]
[ 0.06532937]]
After 0 training step(s), w1 is:
[[-0.8123182 1.4855988 0.06632921]
[-2.4437041 0.1002484 0.59222424]]
total_cross_entropy is : 0.067492485
After 1000 training step(s), w1 is:
[[-1.2754936 1.9323932 0.7181832]
[-2.827644 0.4706616 1.1418985]]
total_cross_entropy is : 0.016338505
After 2000 training step(s), w1 is:
[[-1.5139761 2.1591146 1.0742906]
[-3.0170891 0.6484542 1.46365 ]]
total_cross_entropy is : 0.009075474
After 3000 training step(s), w1 is:
[[-1.6539441 2.292184 1.2743924]
[-3.1415606 0.7646775 1.6682037]]
total_cross_entropy is : 0.007144361
After 4000 training step(s), w1 is:
[[-1.7914352 2.4218476 1.4638877 ]
[-3.2893898 0.90241855 1.8852748 ]]
total_cross_entropy is : 0.005784708
Final w1 is:
[[-1.9618274 2.582354 1.6820377]
[-3.4681718 1.0698233 2.11789 ]]
可以看到隨著訓練的進行,交叉熵是逐漸變小的,交叉熵越小說明預測的結果和真實的結果差距越小。
上面的程式實現了訓練神經網路的全部過程。從這段程式可以總結出訓練神經網路的過程可以分成以下3個步驟
1. 定義神經網路的結果和前向傳播的輸出結果。
** 2. 定義損失函式以及選擇反向傳播優化的演算法**
** 3. 生成會話(tf.Session)並且在訓練資料上反覆執行反向傳播優化演算法。**
無論神經網路的結果如何變化,這3個步驟是不變的