
Python data science one
阿新 • • 發佈:2018-11-17
在常見的資料探勘中,dirty data的內容:
缺失值,異常值,不一致的值,重複的資料以及含有特殊符號(如#,*,等)
異常值往往十分的具有價值,重視異常值的出現,分析其產生的原因,常常成為發現問題而進而改進決策的契機
異常值分析:1st進行簡單的統計量分析,最常用的是最大值,最小值,用來判斷這個變數的取值是否超出了合理的選擇
2sed:正態分佈假設的3seigema???之外的小概率事件.3thd,識別異常值的一個標準,
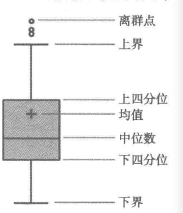 這個在R資料分析中用的異常的多.....Python....下面來研究研究
這個在R資料分析中用的異常的多.....Python....下面來研究研究
資料特徵分析:
分佈分析:對於定量的資料,瞭解其分佈形式是對稱的還是非對稱的,發現某些特大或特小的可疑值,可通過回執頻率分佈圖,繪製頻率分佈直方圖,繪製莖葉圖進行直觀的分析,對於定性的分類資料,可用餅圖和條形圖直觀的顯示資料
ps:其實也就是根據經驗,靠著某種直覺來嘗試的意思
so,拿到一個案例的時候要考慮將什麼作為引數,反應什麼問題,做啥子分析..
常用的庫與函式:
matplotlib
import matplotlib.pyplot as plt
plt.plot([1,2,3,4])
plt.ylabel('some numbers')
plt.show()也可以將plt.plot()函式傳遞多個序列,每兩個序列是一個x,y向量對,在圖中構成一條曲線
import matplotlib.pyplot as plt plt.plot([1,2,3,4],[1,4,9,16],'ro') plt.axis([0,6,0,20])
想用紅點表示這條曲線
'-' solid line style '--' dashed line style '-.' dash-dot line style ':' dotted line style '.' point marker ',' pixel marker 'o' circle marker 'v' triangle_down marker '^' triangle_up marker '<' triangle_left marker '>' triangle_right marker '1' tri_down marker '2' tri_up marker '3' tri_left marker '4' tri_right marker 's' square marker 'p' pentagon marker '*' star marker 'h' hexagon1 marker 'H' hexagon2 marker '+' plus marker 'x' x marker 'D' diamond marker 'd' thin_diamond marker '|' vline marker '_' hline marker The following color abbreviations are supported: character color ‘b’ blue ‘g’ green ‘r’ red ‘c’ cyan ‘m’ magenta ‘y’ yellow ‘k’ black ‘w’ white
#設定軸座標,[xmin, xmax, ymin, ymax]
plt.axis([1,8,1,32])
控制線的屬性
線有許多屬性可以設定:線寬、線的形狀,平滑等等。這裡有一些設定線屬性的方法:
使用關鍵字引數
plt.plot(x,y,linewidth=2.0)
對線物件(Line2D)使用set_方法,plot()會返回一個線物件的列表,比如line1, line2 = plot(x1, y1, x2, y2)。下面的程式碼我們將假設我們只有一條線,即返回的線物件列表的長度為1。
line, = plt.plot(x, y, '-')
line.set_antialiased(False) # 關閉平滑
使用setp()命令。 下面的例子使用的是MATLAB風格的命令去設定一個線的列表的多個屬性。setp()可以作用於一個列表物件或者是一個單一的物件。你可以使用python風格的關鍵字引數或者是MATLAB風格的string/value對為引數:
lines = plt.plot(x1, y1, x2, y2)
# 使用關鍵字
plt.setp(lines, color='r', linewidth=2.0)
# 或者是MATLAB風格的string/value對
plt.setp(lines, 'color', 'r', 'linewidth', 2.0)處理文字
text()命令可以用來在任意位置上新增文字,xlabel(),ylabel(),title()可以用來在X軸,Y軸,標題處新增文字。
plt.xlabel('Smarts')#xlabel設定橫軸的名稱
plt.ylabel('Probability')#設定縱軸的名稱
plt.title('Histogram of IQ')#設定題目
plt.text(60, .025, r'$\mu=100,\ \sigma=15$')#設定在什麼位置上還寫啥
plt.axis([40, 160, 0, 0.03])
plt.grid(True)
plt.show()
圖:
mu, sigma = 100, 15
x = mu + sigma * np.random.randn(10000)
# 直方圖
n, bins, patches = plt.hist(x, 50, normed=1, facecolor='g', alpha=0.75)
#註釋
plt.annotate('local max', xy=(2, 1), xytext=(3, 1.5),
arrowprops=dict(facecolor='black', shrink=0.05),
#縱座標
import numpy as np
import matplotlib.pyplot as plt
# 在區間[0,1]製造一些資料
# np.random.normal為高斯分佈
y = np.random.normal(loc=0.5, scale=0.4, size=1000)
y = y[(y > 0) & (y < 1)]
y.sort()
x = np.arange(len(y))
# 建立一個視窗
plt.figure(1)
# 線性
plt.subplot(221)
plt.plot(x, y)
plt.yscale('linear')
plt.title('linear')
plt.grid(True)
# 對數
plt.subplot(222)
plt.plot(x, y)
plt.yscale('log')
plt.title('log')
plt.grid(True)
# symmetric log
plt.subplot(223)
plt.plot(x, y - y.mean())
plt.yscale('symlog', linthreshy=0.05)
plt.title('symlog')
plt.grid(True)
# logit
plt.subplot(224)
plt.plot(x, y)
plt.yscale('logit')
plt.title('logit')
plt.grid(True)
plt.show()
繪製:
import matplotlib.pyplot as plt
import numpy as np
import matplotlib
# 設定matplotlib正常顯示中文和負號
matplotlib.rcParams['font.sans-serif']=['SimHei'] # 用黑體顯示中文
matplotlib.rcParams['axes.unicode_minus']=False # 正常顯示負號
# 隨機生成(10000,)服從正態分佈的資料
data = np.random.randn(10000)
"""
繪製直方圖
data:必選引數,繪圖資料
bins:直方圖的長條形數目,可選項,預設為10
normed:是否將得到的直方圖向量歸一化,可選項,預設為0,代表不歸一化,顯示頻數。normed=1,表示歸一化,顯示頻率。
facecolor:長條形的顏色
edgecolor:長條形邊框的顏色
alpha:透明度
"""
plt.hist(data, bins=40, normed=0, facecolor="blue", edgecolor="black", alpha=0.7)
# 顯示橫軸標籤
plt.xlabel("區間")
# 顯示縱軸標籤
plt.ylabel("頻數/頻率")
# 顯示圖示題
plt.title("頻數/頻率分佈直方圖")
plt.show() 頻率頻數直方圖是連續的,條形圖是不連續的,只能表示分類的效果,在哪個明確的範圍內
頻率頻數直方圖是連續的,條形圖是不連續的,只能表示分類的效果,在哪個明確的範圍內
import matplotlib.pyplot as plt
import matplotlib
# 設定中文字型和負號正常顯示
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
matplotlib.rcParams['axes.unicode_minus'] = False
label_list = ['2014', '2015', '2016', '2017'] # 橫座標刻度顯示值
num_list1 = [20, 30, 15, 35] # 縱座標值1
num_list2 = [15, 30, 40, 20] # 縱座標值2
x = range(len(num_list1))
"""
繪製條形圖
left:長條形中點橫座標
height:長條形高度
width:長條形寬度,預設值0.8
label:為後面設定legend準備
"""
rects1 = plt.bar(left=x, height=num_list1, width=0.4, alpha=0.8, color='red', label="一部門")
rects2 = plt.bar(left=[i + 0.4 for i in x], height=num_list2, width=0.4, color='green', label="二部門")
plt.ylim(0, 50) # y軸取值範圍
plt.ylabel("數量")
"""
設定x軸刻度顯示值
引數一:中點座標
引數二:顯示值
"""
plt.xticks([index + 0.2 for index in x], label_list)
plt.xlabel("年份")
plt.title("某某公司")
plt.legend() # 設定題注
# 編輯文字
for rect in rects1:
height = rect.get_height()
plt.text(rect.get_x() + rect.get_width() / 2, height+1, str(height), ha="center", va="bottom")
for rect in rects2:
height = rect.get_height()
plt.text(rect.get_x() + rect.get_width() / 2, height+1, str(height), ha="center", va="bottom")
plt.show()
#plt.axes().get_xaxis().set_visible(False)隱藏座標軸
#設定視窗的尺寸
plt.figure(figsize=(10,6))
plt.figure(dpi=128,figsize(10,6))dpi向figure傳遞解析度....