
Day8--模組與包
模組的概念
在計算機程式的開發過程中,隨著程式程式碼越寫越多,在一個檔案裡程式碼就會越來越長,越來越不容易維護。
為了編寫可維護的程式碼,我們把很多函式分組,分別放到不同的檔案裡,這樣,每個檔案包含的程式碼就相對較少,很多程式語言都採用這種組織程式碼的方式。在Python中,一個.py檔案就稱之為一個模組(Module)。
使用模組有什麼好處?
最大的好處是大大提高了程式碼的可維護性。
其次,編寫程式碼不必從零開始。當一個模組編寫完畢,就可以被其他地方引用。我們在編寫程式的時候,也經常引用其他模組,包括Python內建的模組和來自第三方的模組。
所以,模組一共三種:
- python標準庫
- 第三方模組
- 應用程式自定義模組
另外,使用模組還可以避免函式名和變數名衝突。相同名字的函式和變數完全可以分別存在不同的模組中,因此,我們自己在編寫模組時,不必考慮名字會與其他模組衝突。但是也要注意,儘量不要與內建函式名字衝突。
模組匯入方法
1 import 語句
#calculate中的程式碼:
print('ok') x = 3 def add(x,y): return x+y def sub(x,y): return x-y
import calculate#python直譯器通過搜尋路徑找到calculate.py後,將calculate=calculate.py all codeprint(calculate.add(1,2))#3
當我們使用import語句的時候,Python直譯器是怎樣找到對應的檔案的呢?答案就是直譯器有自己的搜尋路徑,存在sys.path裡。
import sys print(sys.path) #['C:\\Users\\Administrator\\PycharmProjects\\untitled\\week2', 'C:\\Users\\Administrator\\PycharmProjects\\untitled', 'C:\\Users\\Administrator\\PycharmProjects\\untitled\\venv\\Scripts\\python37.zip', 'C:\\Program Files\\Python37\\DLLs', 'C:\\Program Files\\Python37\\lib', 'C:\\Program Files\\Python37', 'C:\\Users\\Administrator\\PycharmProjects\\untitled\\venv', 'C:\\Users\\Administrator\\PycharmProjects\\untitled\\venv\\lib\\site-packages', 'C:\\Users\\Administrator\\PycharmProjects\\untitled\\venv\\lib\\site-packages\\setuptools-39.1.0-py3.7.egg', 'C:\\Users\\Administrator\\PycharmProjects\\untitled\\venv\\lib\\site-packages\\pip-10.0.1-py3.7.egg']
因此若像我一樣在當前目錄下存在與要引入模組同名的檔案,就會把要引入的模組遮蔽掉。
def add(x,y): return x+t+2 print(add(1,2)) #如果calculate呼叫在前,則列印當前結果(也就是5),反之列印3
呼叫其他模組中的方法時,一定要通過模組呼叫方法,不能直接呼叫。
import calculate print(x)#name 'x' is not defined print(calculate.x)#3
2 from…import 語句
那麼,如何直接使用方法呢?
from calculate import add,sub #從模組呼叫方法 print(add(1,4))#5 print(sub(4,1))#3
這個宣告不會把整個calculate模組匯入到當前的名稱空間中,只會將它裡面的add或sub單個引入到執行這個宣告的模組的全域性符號表。
補充:
import calculate,time #同時呼叫這兩個模組
3 From…import* 語句
from calculate import * #直接呼叫calculate下的所有方法
這提供了一個簡單的方法來匯入一個模組中的所有專案。然而這種宣告不該被過多地使用。大多數情況, Python程式設計師不使用這種方法,因為引入的其它來源的命名,很可能覆蓋了已有的定義。
因此,可以考慮給這些方法重新命名
from calculate import add as plus #重新命名後使用原有的名字會報錯 print(plus(1,2))
4 執行本質
#1 import test #2 from test import add
無論1還是2,首先通過sys.path找到test.py,然後執行test指令碼(全部執行),區別是1會將test這個變數名載入到名字空間,而2只會將add這個變數名載入進來。
包(package)
如果不同的人編寫的模組名相同怎麼辦?為了避免模組名衝突,Python又引入了按目錄來組織模組的方法,稱為包(Package)。
舉個例子,一個abc.py的檔案就是一個名字叫abc的模組,一個xyz.py的檔案就是一個名字叫xyz的模組。
現在,假設我們的abc和xyz這兩個模組名字與其他模組衝突了,於是我們可以通過包來組織模組,避免衝突。方法是選擇一個頂層包名:
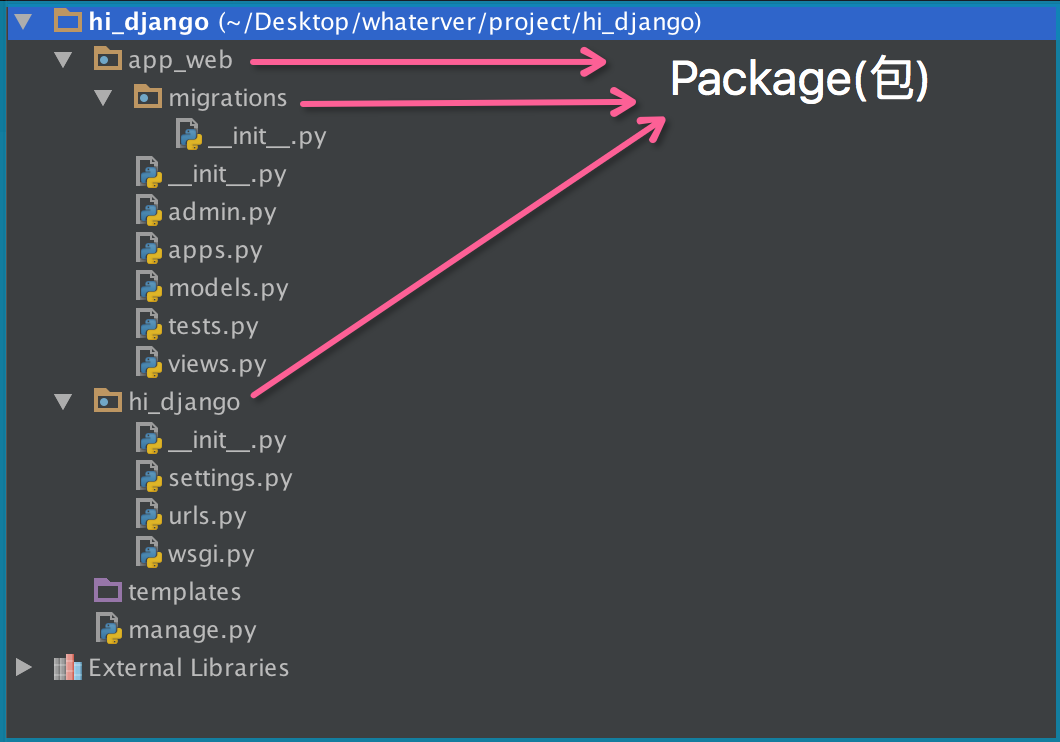
引入了包以後,只要頂層的包名不與別人衝突,那所有模組都不會與別人衝突。現在,view.py模組的名字就變成了hello_django.app01.views,類似的,manage.py的模組名則是hello_django.manage。
請注意,每一個包目錄下面都會有一個__init__.py的檔案,這個檔案是必須存在的,否則,Python就把這個目錄當成普通目錄(資料夾),而不是一個包。__init__.py可以是空檔案,也可以有Python程式碼,因為__init__.py本身就是一個模組,而它的模組名就是對應包的名字。
呼叫包就是執行包下的__init__.py檔案
注意點(important)
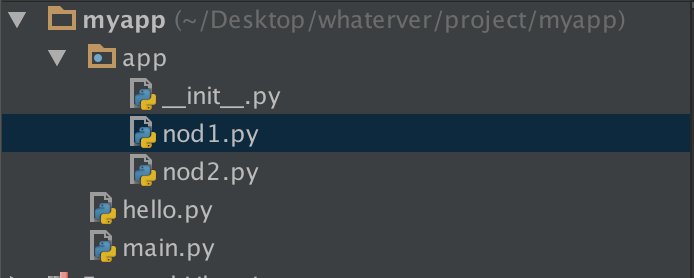
1--------------
在nod1裡import hello是找不到的,有同學說可以找到呀,那是因為你的pycharm為你把myapp這一層路徑加入到了sys.path裡面,所以可以找到,然而程式一旦在命令列執行,則報錯。有同學問那怎麼辦?簡單啊,自己把這個路徑加進去不就OK啦:
import sys,os BASE_DIR=os.path.dirname(os.path.dirname(os.path.abspath(__file__))) sys.path.append(BASE_DIR) import hello hello.hello1()
2 --------------
if __name__=='__main__': print('ok')
“Make a .py both importable and executable”
如果我們是直接執行某個.py檔案的時候,該檔案中那麼”__name__ == '__main__'“是True,但是我們如果從另外一個.py檔案通過import匯入該檔案的時候,這時__name__的值就是我們這個py檔案的名字而不是__main__。
這個功能還有一個用處:除錯程式碼的時候,在”if __name__ == '__main__'“中加入一些我們的除錯程式碼,我們可以讓外部模組呼叫的時候不執行我們的除錯程式碼,但是如果我們想排查問題的時候,直接執行該模組檔案,除錯程式碼能夠正常執行!s
關於包的補充:
如果只有一層包:
from web import logger #web是包名,logger是.py檔名(也就是模組名)
logger.logger()#logging
如果有兩層包呢?
from web.web2 import logger
直接呼叫方法呢?
from web.web2.logger import logger logger()#logging
總結:import後必須跟模組
import web #執行了_init_檔案
軟體目錄結構規範
為什麼要設計好目錄結構?
"設計專案目錄結構",就和"程式碼編碼風格"一樣,屬於個人風格問題。對於這種風格上的規範,一直都存在兩種態度:
- 一類同學認為,這種個人風格問題"無關緊要"。理由是能讓程式work就好,風格問題根本不是問題。
- 另一類同學認為,規範化能更好的控制程式結構,讓程式具有更高的可讀性。
我是比較偏向於後者的,因為我是前一類同學思想行為下的直接受害者。我曾經維護過一個非常不好讀的專案,其實現的邏輯並不複雜,但是卻耗費了我非常長的時間去理解它想表達的意思。從此我個人對於提高專案可讀性、可維護性的要求就很高了。"專案目錄結構"其實也是屬於"可讀性和可維護性"的範疇,我們設計一個層次清晰的目錄結構,就是為了達到以下兩點:
- 可讀性高: 不熟悉這個專案的程式碼的人,一眼就能看懂目錄結構,知道程式啟動指令碼是哪個,測試目錄在哪兒,配置檔案在哪兒等等。從而非常快速的瞭解這個專案。
- 可維護性高: 定義好組織規則後,維護者就能很明確地知道,新增的哪個檔案和程式碼應該放在什麼目錄之下。這個好處是,隨著時間的推移,程式碼/配置的規模增加,專案結構不會混亂,仍然能夠組織良好。
所以,我認為,保持一個層次清晰的目錄結構是有必要的。更何況組織一個良好的工程目錄,其實是一件很簡單的事兒。
目錄組織方式
關於如何組織一個較好的Python工程目錄結構,已經有一些得到了共識的目錄結構。在Stackoverflow的這個問題上,能看到大家對Python目錄結構的討論。
這裡面說的已經很好了,我也不打算重新造輪子列舉各種不同的方式,這裡面我說一下我的理解和體會。
假設你的專案名為foo, 我比較建議的最方便快捷目錄結構這樣就足夠了:
Foo/
|-- bin/
| |-- foo
|
|-- foo/
| |-- tests/
| | |-- __init__.py
| | |-- test_main.py
| |
| |-- __init__.py
| |-- main.py
|
|-- docs/
| |-- conf.py
| |-- abc.rst
|
|-- setup.py
|-- requirements.txt
|-- README
簡要解釋一下:
bin/: 存放專案的一些可執行檔案,當然你可以起名script/之類的也行。foo/: 存放專案的所有原始碼。(1) 原始碼中的所有模組、包都應該放在此目錄。不要置於頂層目錄。(2) 其子目錄tests/存放單元測試程式碼; (3) 程式的入口最好命名為main.py。docs/: 存放一些文件。setup.py: 安裝、部署、打包的指令碼。requirements.txt: 存放軟體依賴的外部Python包列表。README: 專案說明檔案。
除此之外,有一些方案給出了更加多的內容。比如LICENSE.txt,ChangeLog.txt檔案等,我沒有列在這裡,因為這些東西主要是專案開源的時候需要用到。如果你想寫一個開源軟體,目錄該如何組織,可以參考這篇文章。
下面,再簡單講一下我對這些目錄的理解和個人要求吧。
關於README的內容
這個我覺得是每個專案都應該有的一個檔案,目的是能簡要描述該專案的資訊,讓讀者快速瞭解這個專案。
它需要說明以下幾個事項:
- 軟體定位,軟體的基本功能。
- 執行程式碼的方法: 安裝環境、啟動命令等。
- 簡要的使用說明。
- 程式碼目錄結構說明,更詳細點可以說明軟體的基本原理。
- 常見問題說明。
我覺得有以上幾點是比較好的一個README。在軟體開發初期,由於開發過程中以上內容可能不明確或者發生變化,並不是一定要在一開始就將所有資訊都補全。但是在專案完結的時候,是需要撰寫這樣的一個文件的。
可以參考Redis原始碼中Readme的寫法,這裡面簡潔但是清晰的描述了Redis功能和原始碼結構。
關於requirements.txt和setup.py
setup.py
一般來說,用setup.py來管理程式碼的打包、安裝、部署問題。業界標準的寫法是用Python流行的打包工具setuptools來管理這些事情。這種方式普遍應用於開源專案中。不過這裡的核心思想不是用標準化的工具來解決這些問題,而是說,一個專案一定要有一個安裝部署工具,能快速便捷的在一臺新機器上將環境裝好、程式碼部署好和將程式執行起來。
這個我是踩過坑的。
我剛開始接觸Python寫專案的時候,安裝環境、部署程式碼、執行程式這個過程全是手動完成,遇到過以下問題:
- 安裝環境時經常忘了最近又添加了一個新的Python包,結果一到線上執行,程式就出錯了。
- Python包的版本依賴問題,有時候我們程式中使用的是一個版本的Python包,但是官方的已經是最新的包了,通過手動安裝就可能裝錯了。
- 如果依賴的包很多的話,一個一個安裝這些依賴是很費時的事情。
- 新同學開始寫專案的時候,將程式跑起來非常麻煩,因為可能經常忘了要怎麼安裝各種依賴。
setup.py可以將這些事情自動化起來,提高效率、減少出錯的概率。"複雜的東西自動化,能自動化的東西一定要自動化。"是一個非常好的習慣。
setuptools的文件比較龐大,剛接觸的話,可能不太好找到切入點。學習技術的方式就是看他人是怎麼用的,可以參考一下Python的一個Web框架,flask是如何寫的: setup.py
當然,簡單點自己寫個安裝指令碼(deploy.sh)替代setup.py也未嘗不可。
requirements.txt
這個檔案存在的目的是:
- 方便開發者維護軟體的包依賴。將開發過程中新增的包新增進這個列表中,避免在
setup.py安裝依賴時漏掉軟體包。 - 方便讀者明確專案使用了哪些Python包。
這個檔案的格式是每一行包含一個包依賴的說明,通常是flask>=0.10這種格式,要求是這個格式能被pip識別,這樣就可以簡單的通過 pip install -r requirements.txt來把所有Python包依賴都裝好了。具體格式說明: 點這裡。
關於配置檔案的使用方法
注意,在上面的目錄結構中,沒有將conf.py放在原始碼目錄下,而是放在docs/目錄下。
很多專案對配置檔案的使用做法是:
- 配置檔案寫在一個或多個python檔案中,比如此處的conf.py。
- 專案中哪個模組用到這個配置檔案就直接通過
import conf這種形式來在程式碼中使用配置。
這種做法我不太贊同:
- 這讓單元測試變得困難(因為模組內部依賴了外部配置)
- 另一方面配置檔案作為使用者控制程式的介面,應當可以由使用者自由指定該檔案的路徑。
- 程式元件可複用性太差,因為這種貫穿所有模組的程式碼硬編碼方式,使得大部分模組都依賴
conf.py這個檔案。
所以,我認為配置的使用,更好的方式是,
- 模組的配置都是可以靈活配置的,不受外部配置檔案的影響。
- 程式的配置也是可以靈活控制的。
能夠佐證這個思想的是,用過nginx和mysql的同學都知道,nginx、mysql這些程式都可以自由的指定使用者配置。
所以,不應當在程式碼中直接import conf來使用配置檔案。上面目錄結構中的conf.py,是給出的一個配置樣例,不是在寫死在程式中直接引用的配置檔案。可以通過給main.py啟動引數指定配置路徑的方式來讓程式讀取配置內容。當然,這裡的conf.py你可以換個類似的名字,比如settings.py。或者你也可以使用其他格式的內容來編寫配置檔案,比如settings.yaml之類的。
本節作業
作業需求:
模擬實現一個ATM + 購物商城程式
- 額度 15000或自定義
- 實現購物商城,買東西加入 購物車,呼叫信用卡介面結賬
- 可以提現,手續費5%
- 每月22號出賬單,每月10號為還款日,過期未還,按欠款總額 萬分之5 每日計息
- 支援多賬戶登入
- 支援賬戶間轉賬
- 記錄每月日常消費流水
- 提供還款介面
- ATM記錄操作日誌
- 提供管理介面,包括新增賬戶、使用者額度,凍結賬戶等。。。
- 使用者認證用裝飾器
示例程式碼 https://github.com/triaquae/py3_training/tree/master/atm
簡易流程圖:https://www.processon.com/view/link/589eb841e4b0999184934329