
ElasticSearch最佳入門實踐(六十九)優化寫入流程實現durability可靠儲存(translog,flush)
阿新 • • 發佈:2018-11-18
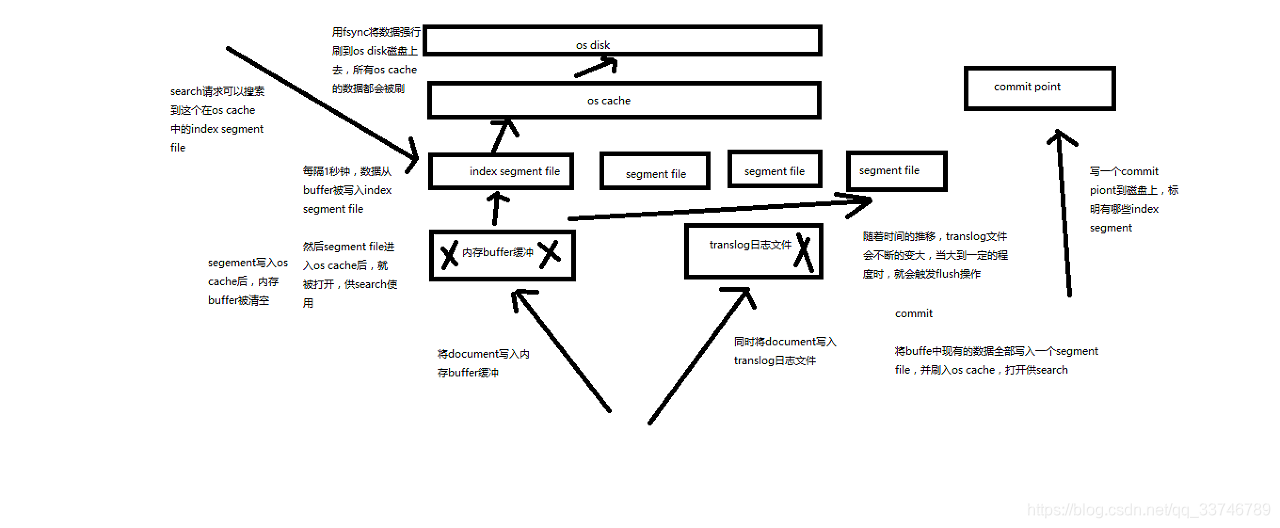
(1)資料寫入buffer緩衝和translog日誌檔案
(2)每隔一秒鐘,buffer中的資料被寫入新的segment file,並進入os cache,此時segment被開啟並供search使用
(3)buffer被清空
(4)重複1~3,新的segment不斷新增,buffer不斷被清空,而translog中的資料不斷累加
(5)當translog長度達到一定程度的時候,commit操作發生
(5-1)buffer中的所有資料寫入一個新的segment,並寫入os cache,開啟供使用
(5-2)buffer被清空
(5-3)一個commit ponit被寫入磁碟,標明瞭所有的index segment
(5-4)filesystem cache中的所有index segment file快取資料,被fsync強行刷到磁碟上
(5-5)現有的translog被清空,建立一個新的translog
基於translog和commit point,如何進行資料恢復

fsync+清空translog,就是flush,預設每隔30分鐘flush一次,或者當translog過大的時候,也會flush
POST /my_index/_flush,一般來說別手動flush,讓它自動執行就可以了
translog,每隔5秒被fsync一次到磁碟上。在一次增刪改操作之後,當fsync在primary shard和replica shard都成功>之後,那次增刪改操作才會成功
但是這種在一次增刪改時強行fsync translog可能會導致部分操作比較耗時,也可以允許部分資料丟失,設定非同步fsync translog
PUT /my_index/_settings
{
"index.translog.durability": "async",
"index.translog.sync_interval": "5s"
}