
YOLOv3深度理解
YOLO系列演算法,是目前目標檢測演算法中速度最快的一種方法。儘管在目標檢測的準確率上不是最為準確的檢測演算法,但是考慮到工業上的實時目標檢測應用,YOLO目前仍具有不可替代的優勢。換句話說,YOLO將其犧牲的一點準確度極大的彌補在實時性上,在工業目標檢測領域,可以完成專案實際的商業落地。
YOLO系列演算法的論文:
這裡僅深度理解yolov3,對於之前的系列不做過多的分析。
YOLO v3: Better, not Faster, Stronger
YOLO v2紙的官方標題似乎是YOLO是一種基於牛奶的兒童健康飲料,而不是物體檢測演算法。 它被命名為“YOLO9000:更好,更快,更強”。
因為時間YOLO 9000是最快的,也是最準確的演算法之一。 然而,幾年之後,它已不再是像RetinaNet這樣的演算法最準確的,而且SSD在準確性方面表現優於它。 然而,它仍然是最快的之一。
但是,為了提高YOLO v3的準確性,這種速度已被取消。 雖然早期版本在Titan X上以45 FPS執行,但當前版本的時鐘約為30 FPS。 這與稱為Darknet的底層架構的複雜性增加有關。
Darknet-53
YOLO v2採用了自定義深度架構darknet-19,最初是19層網路,另外還有11層用於物件檢測。 YOLO v2採用30層架構,經常遇到小物件檢測。這歸因於細粒度特徵的丟失,因為層對輸入進行了下采樣。為了解決這個問題,YOLO v2使用了身份對映,連線了前一層的特徵對映以捕獲低階特徵。
然而,YOLO v2的架構仍然缺少一些最重要的元素,這些元素現在是大多數最先進演算法的主要元素。沒有剩餘塊,沒有跳過連線,也沒有上取樣。 YOLO v3包含所有這些。
首先,YOLO v3使用Darknet的變體,最初在Imagenet上訓練了53層網路。對於檢測任務,在其上堆疊了53層,為YOLO v3提供了106層完全卷積的底層架構。這就是YOLO v3與YOLO v2相比速度緩慢的原因。以下是YOLO的架構現在的樣子。
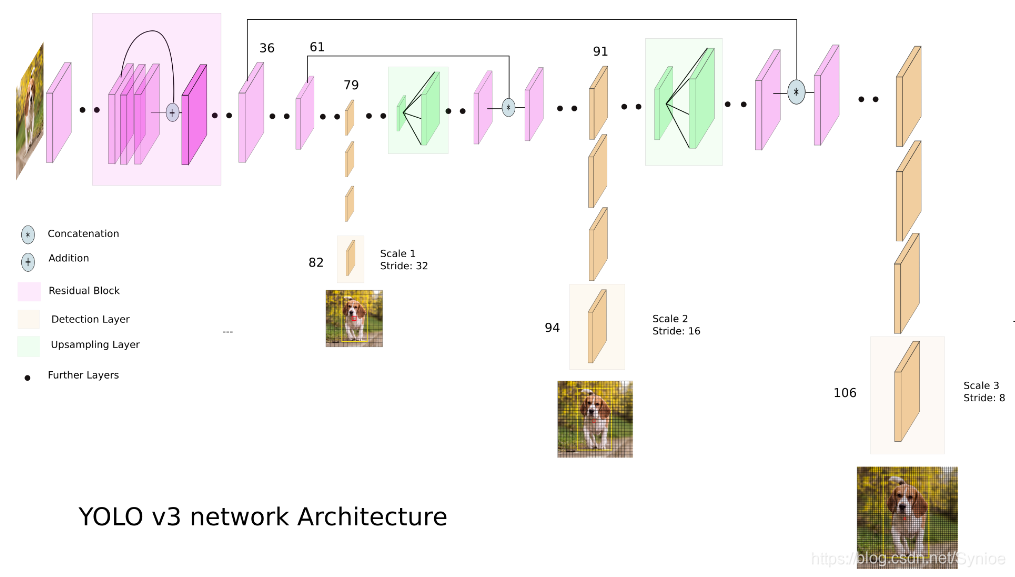
多尺度檢測
較新的架構擁有剩餘跳過連線和上取樣。 v3最突出的特點是它可以在三種不同的尺度上進行檢測。 YOLO是一個完全卷積網路,它的最終輸出是通過在特徵對映上應用1 x 1核心生成的。 在YOLO v3中,通過在網路中的三個不同位置處在三種不同大小的特徵對映上應用1×1檢測核心來完成檢測。
檢測核心的形狀是1×1×(B×(5 + C))。 這裡B是特徵對映上的單元可以預測的邊界框的數量,“5”表示4個邊界框屬性和1個物件置信度,C是類的數量。 在使用COCO訓練的YOLO v3中,B = 3且C = 80,因此核心大小為1 x 1 x 255.此核心生成的特徵對映具有與前一個特徵對映相同的高度和寬度,並具有沿著該特徵對映的檢測屬性。 如上所述的深度。

在我們進一步討論之前,我想指出網路的步幅,或者一個層被定義為它對輸入進行下采樣的比率。在以下示例中,我假設我們有一個大小為416 x 416的輸入影象。
YOLO v3在三個等級上進行預測,這通過分別將輸入影象的尺寸下采樣32,16和8來精確地給出。
第一次檢測由第82層進行。對於前81層,影象由網路下采樣,使得第81層具有32的步幅。如果我們具有416×416的影象,則得到的特徵圖將具有13×13的大小。這裡使用1 x 1檢測核心,為我們提供13 x 13 x 255的檢測特徵圖。
然後,來自層79的特徵對映經歷幾個卷積層,然後被2x上升到26×26的維度。然後,該特徵對映與來自層61的特徵對映深度連線。然後,組合的特徵對映再次經受幾個1×1卷積層以融合來自較早層(61)的特徵。然後,通過第94層進行第二次檢測,產生26×26×255的檢測特徵圖。
再次遵循類似的過程,其中來自層91的特徵圖在與來自層36的特徵圖深度連線之前經歷少量卷積層。像之前一樣,接下來幾個1×1卷積層來融合來自先前的資訊。層(36)。我們在第106層製作3的最後一個,產生尺寸為52 x 52 x 255的特徵圖。
小目標檢測
不同層次的檢測有助於解決檢測小物體的問題,這是YOLO v2的常見問題。 與先前圖層連線的上取樣圖層有助於保留細粒度特徵,這有助於檢測小物件。
13 x 13層負責檢測大型物體,而52 x 52層檢測較小的物體,26 x 26層檢測中等物體。 以下是不同層在同一物件中拾取的不同物件的對比分析。
anchor boxes的選擇
YOLO v3,總共使用了9個anchor box。 每個規模三個。 如果在自己的資料集上訓練YOLO,則應該使用K-Means聚類來生成9個錨點。
然後,按照尺寸的降序排列anchor box。 為第一個scale分配三個最大的anchor,為第二個scale分配三個anchor,為第三個scale分配最後三個anchor。
為每張圖片給更多的bounding box
對於相同大小的輸入影象,YOLO v3比YOLO v2預測更多的邊界框。 例如,在其原始解析度為416 x 416時,YOLO v2預測為13 x 13 x 5 = 845個box。 在每個網格單元,使用5個anchor檢測到5個box。
另一方面,YOLO v3預測3種不同尺度的box。 對於416 x 416的相同影象,預測框的數量是10,647。 這意味著YOLO v3預測YOLO v2預測的box數量的10倍。 您可以很容易地想象為什麼它比YOLO v2慢。 在每個尺度上,每個網格可以使用3個anchor來預測3個框。 由於有三個scale,所以總共使用的anchor box數量為9個,每個scale3個。
損失函式的變化
yolov2 :
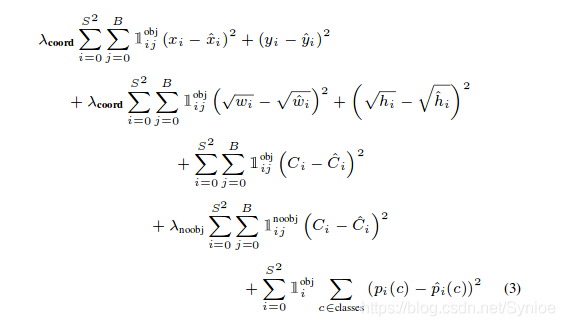
yolov2損失函式的後三項是懲罰項,分別對於預測目標的bounding box響應的預測得分懲罰、非目標的預測得分懲罰、目標bounding box的預測分類懲罰。
yolov3主要在這三項上的區別,原先採用的是方差損失,現在改用交叉熵損失。v3的目標置信度和類別預測採用的是LR迴歸。當我們訓練檢測器時,對於每一個ground truth box, 分配一個bounding box, 使其anchor和ground truth box有最大的重疊。
不再用softmax分類
YOLO v3現在對影象中檢測到的物件執行多標記分類。
在早期的YOLO中,作者習慣於將類得分最大化,並將具有最高得分的類作為包含在邊界框中的物件的類。 這已在YOLO v3中進行了修改。
Softmaxing類依賴於類是互斥的假設,或者簡單地說,如果一個物件屬於一個類,那麼它就不屬於另一個類。 這在COCO資料集中工作正常。
但是,當我們在資料集中有Person和Women等類時,上述假設就失敗了。 這就是為什麼YOLO的作者沒有采用softmaxing類的原因。 相反,使用邏輯迴歸預測每個類別分數,並且使用閾值來預測物件的多個標籤。 分數高於此閾值的類將分配給該框。
Benchmarking
YOLO v3與其他先進的探測器(如RetinaNet)相當,同時在COCO mAP 50基準測試中速度更快。 它也比SSD和它的變體更好。 以下是對論文表現的比較。
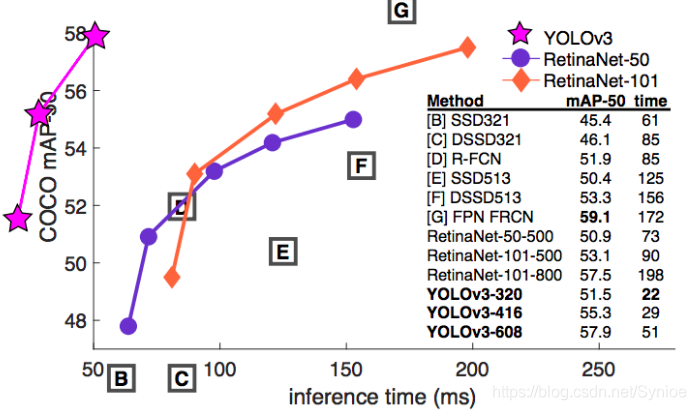
但是,但是,但是,YOLO在COCO基準測試中失去了較高的IoU值,用於拒絕檢測。 我不打算解釋COCO基準如何工作,因為它超出了工作範圍,但COCO 50基準測試中的50是衡量預測的邊界框與物體的地面實體框的對齊程度。 這裡50對應於0.5 IoU。 如果預測和地面實況框之間的IoU小於0.5,則預測被分類為誤定位並標記為假陽性。
在基準測試中,此數字較高(例如,COCO 75),框需要更完美地對齊,以免被評估指標拒絕。 這裡是YOLO被RetinaNet超越的地方,因為它的邊框不像RetinaNet那樣對齊。 這是一個詳細的表格,可用於更廣泛的基準測試。
實驗
在這裡給出的github倉庫中,可以進行圖片或者視訊的檢測,使用的環境:PyTorch 0.3+, OpenCV 3 and Python 3.5
python detect.py --scales 1 --images imgs/img3.jpg一些情況下,較大的輸入解析度沒有多大幫助,但它們可能有助於檢測小物體的影象。 另一方面,較大的輸入解析度會增加推理時間。 這是一個超級引數,需要根據應用進行調整。
可以試驗其他指標,例如批量大小,物件置信度和NMS閾值。 ReadMe檔案中提到了所有內容。
從頭開始訓練yolov3