
python day23簡易爬蟲
阿新 • • 發佈:2018-11-19
簡易爬蟲
爬出該網頁的 2018新片精品的"電影名稱""和"下載連結"
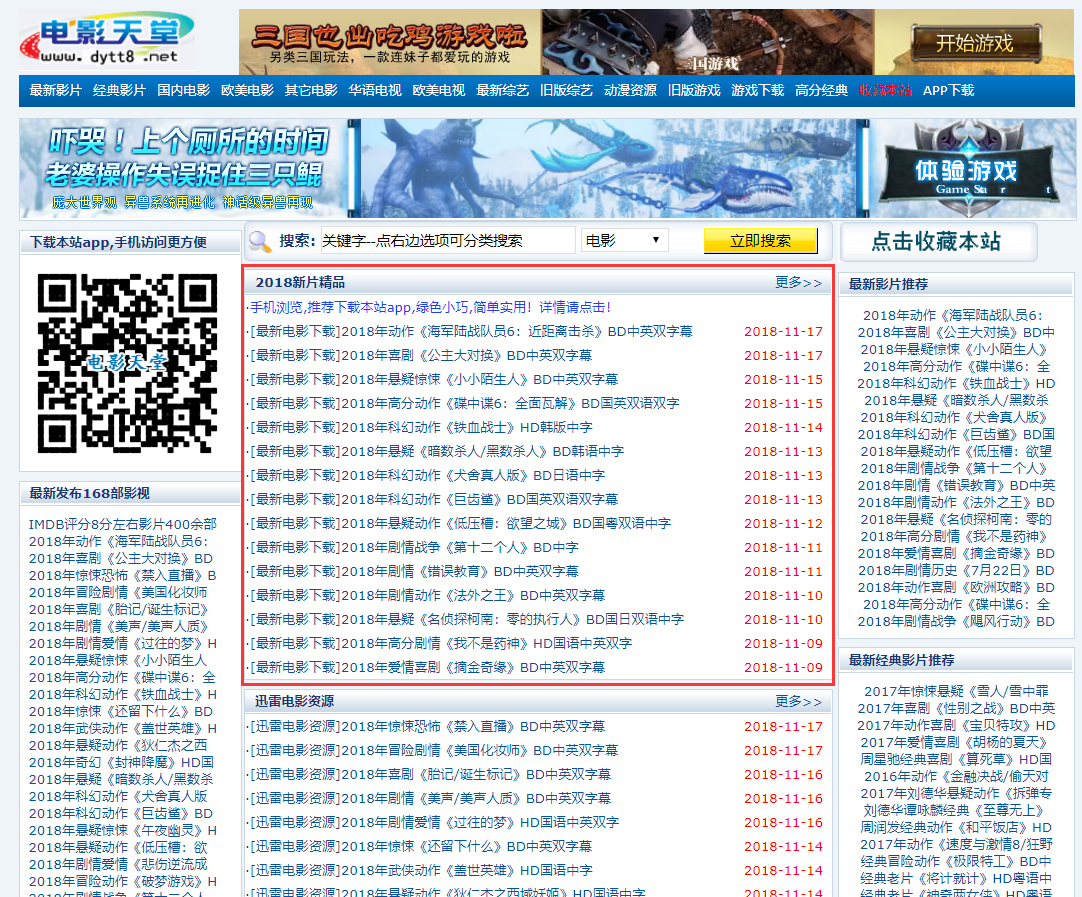
如下:
import re
import ssl
import json
from urllib.request import urlopen
ssl._create_default_https_context = ssl._create_unverified_context #幹掉數字簽名證書
# 獲取首頁的新片精品電影的url
url = "https://www.dytt8.net/" #電影天堂首頁url
content = urlopen(url).read().decode("
最後效果圖:
