
Flume架構、Flume工作原理、Flume應用場景
一、Flume概述
Flume是由 Cloudera 提供的一個分散式、高可靠、高可用的服務,用於分散式的海量日誌的高效收集、聚合、移動系統。簡單來說,Flume 就是一個針對日誌資料進行採集和彙總的一個工具(把日誌從A地方移動到B地方)
Flume 官網:http://flume.apache.org/
Flume 官方文件:http://flume.apache.org/FlumeUserGuide.html
Flume 特點:
(1)、可靠性:當節點出現故障時,日誌能夠被傳送到其他節點上而不會丟失。Flume提供了三種級別的可靠性保障,從強到弱依次分別為:
①.end-to-end(收到資料agent首先將event寫到磁碟上,當資料傳送成功後,再刪除;如果資料傳送失敗,可以重新發送);
②.Store on failure(這也是scribe採用的策略,當資料接收方crash時,將資料寫到本地,待恢復後,繼續傳送);
③.Best effort(資料傳送到接收方後,不會進行確認)。
(2)、可擴充套件性:Flume採用了三層架構,分別為agent,collector和storage,每一層均可以水平擴充套件所有agent和collector由master統一管理,這使得系統容易監控和維護,且master允許有多個(使用ZooKeeper進行管理和負載均衡),這就避免了單點故障問題。
(3)、可管理性
①.所有agent和colletor由master統一管理,這使得系統便於維護。
②.多master情況,Flume利用ZooKeeper和gossip,保證動態配置資料的一致性。
③.使用者可以在master上檢視各個資料來源或者資料流執行情況,且可以對各個資料來源配置和動態載入。
④.Flume提供了web 和shell script command兩種形式對資料流進行管理。①
(4)、功能可擴充套件性
①.使用者可以根據需要新增自己的agent,collector或者storage。
②.此外,Flume自帶了很多元件,包括各種agent(file, syslog等),collector和storage(file,HDFS等)。
(5)、文件豐富,社群活躍
Flume 是Apache下的一個頂級專案,已經成為 Hadoop 生態系統的標配,它的文件比較豐富,社群比較活躍,方便我們學習。
主要的核心概念:
Event:flume最基本的資料單元,帶有一個可選的訊息頭(headers)。如果是文字,event通常是一行記錄,event也是事務的基本單位。
Flow:Event從源點到達目的點的遷移的抽象。
Client:操作位於源點處的Event,將其傳送到Flume Agent。
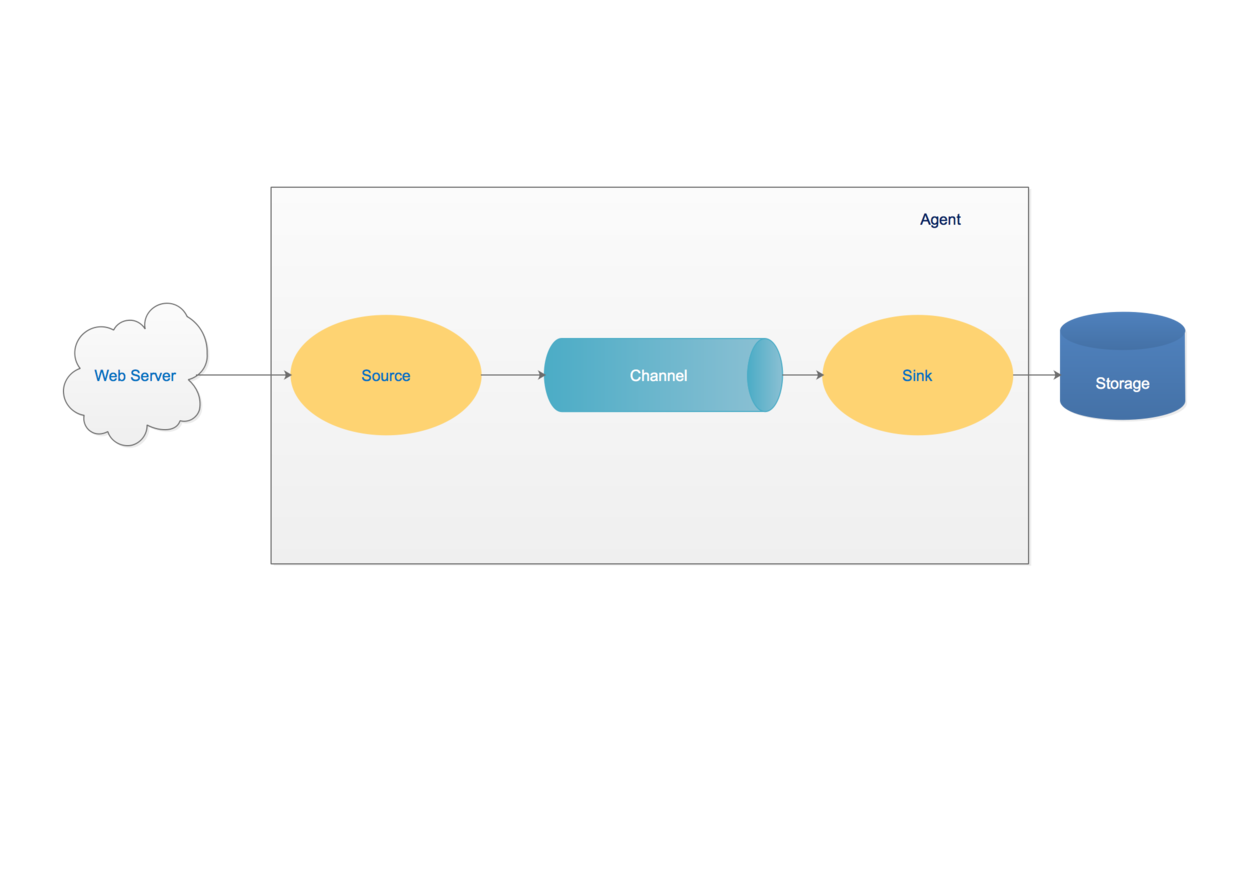
Agent:一個獨立的Flume程序,包含元件Source、Channel、Sink。
Source:用來消費傳遞到該元件的Event,完成對資料的收集,分成transtion和event打入到channel之中。不同的 source,可以接受不同的資料格式。
Channel:主要提供一個佇列的功能,對source提供中的資料進行簡單快取,作用是保證source到sink的資料傳輸過程一定能成功。
Sink:取出Channel中的資料,進行相應的儲存檔案系統、資料庫等。
二、Flume架構
三、Flume工作原理
Flume的核心就是一個agent,這個agent對外有兩個進行互動的地方,一個是接受資料的輸入——source,一個是資料的輸出sink,sink負責將資料傳送到外部指定的目的地。source接收到資料之後,將資料傳送給channel,chanel作為一個數據緩衝區會臨時存放這些資料,隨後sink會將channel中的資料傳送到指定的地方—-例如HDFS等,注意:只有在sink將channel中的資料成功傳送出去之後,channel才會將臨時資料進行刪除,這種機制保證了資料傳輸的可靠性與安全性。
四、Flume應用場景