
ElasticSearch最佳入門實踐(五十二)定製搜尋結果的排序規則
1、預設排序規則
預設情況下,是按照_score降序排序的
然而,某些情況下,可能沒有有用的_score,比如說filter
GET /_search
{
"query" : {
"bool" : {
"filter" : {
"term" : {
"author_id" : 1
}
}
}
}
}
當然,也可以是constant_score
GET /_search { "query" : { "constant_score" : { "filter" : { "term" : { "author_id" : 1 } } } } }
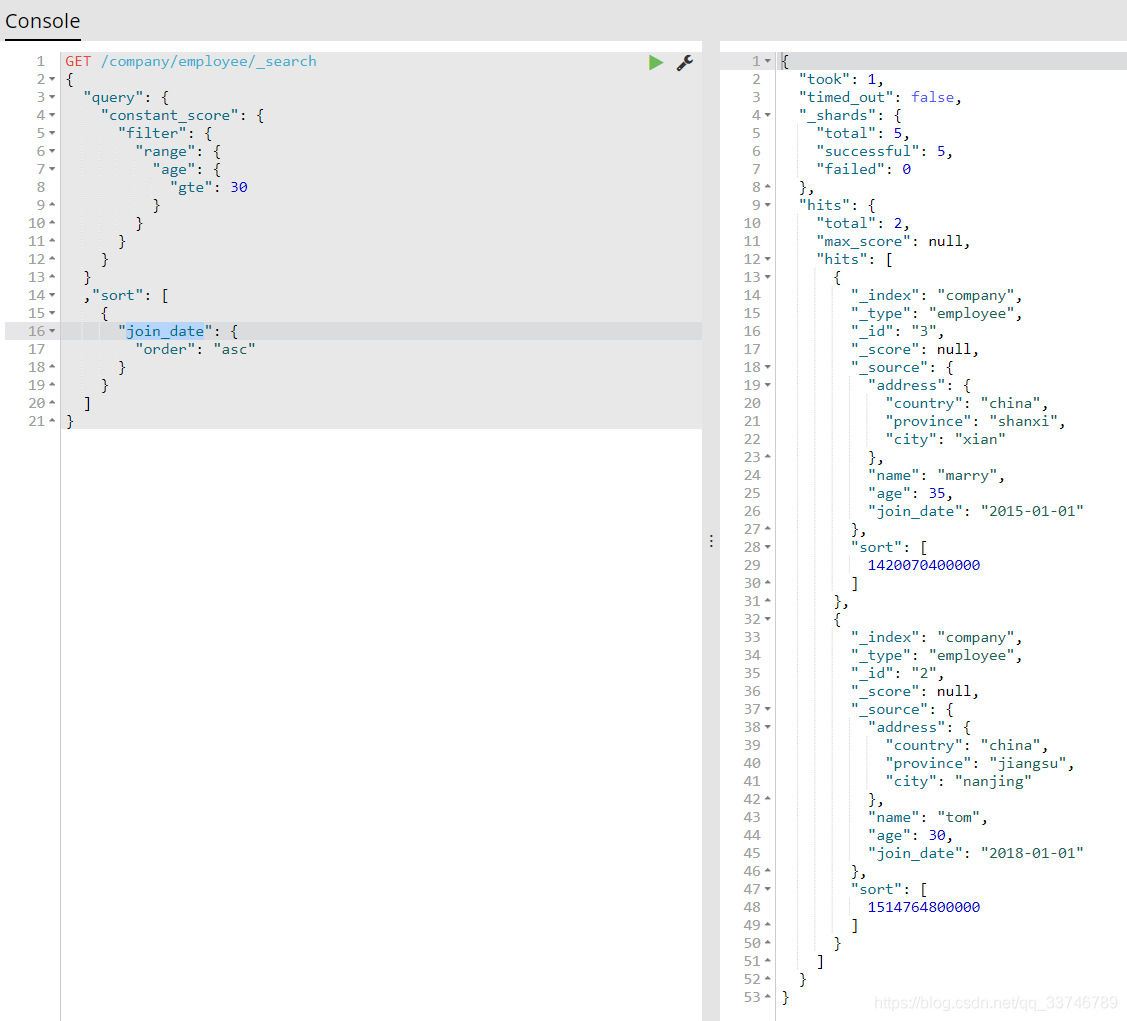
2、定製排序規則
相關推薦
ElasticSearch最佳入門實踐(五十二)定製搜尋結果的排序規則
1、預設排序規則 預設情況下,是按照_score降序排序的 然而,某些情況下,可能沒有有用的_score,比如說filter GET /_search { "query" : { "bool" : { "filter
ElasticSearch最佳入門實踐(四十二)什麼是mapping再次回爐透徹理解
(1)往es裡面直接插入資料,es會自動建立索引,同時建立type以及對應的mapping (2)mapping中就自動定義了每個field的資料型別 (3)不同的資料型別(比如說text和date),可能有的是exact value,有的是full text (4)exac
ElasticSearch最佳入門實踐(三十二)bulk api的奇特json格式與底層效能優化關係揭祕
1、bulk api奇特的json格式 {"action": {"meta"}}\n {"data"}\n {"action": {"meta"}}\n {"data"}\n 2、bulk中的每個操作都可能要轉發到不同的node的shard去執行 3、如果採用比較良好的js
ElasticSearch最佳入門實踐(七十二)Java 實戰 - 對員工資訊進行復雜的搜尋操作
需求: (1)搜尋職位中包含technique的員工 (2)同時要求age在30到40歲之間 (3)分頁查詢,查詢第一頁 1、構建員工資訊 public class EmployeeSearchApp { public static void main
ElasticSearch最佳入門實踐(五十七)分散式搜尋引擎核心解密之fetch phase
1、fetch phbase工作流程 (1)coordinate node構建完priority queue之後,就傳送mget請求去所有shard上獲取對應的document (2)各個shard將document返回給coordinate node
ElasticSearch最佳入門實踐(五十六)分散式搜尋引擎核心解密之query phase
1、query phase (1)搜尋請求傳送到某一個coordinate node,構構建一個priority queue,長度以paging操作from和size為準,預設為10 (2)coordinate node將請求轉發到所有shard,每個sha
ElasticSearch最佳入門實踐(五十四)相關度評分 TF & IDF 演算法解密
1、演算法介紹 relevance score演算法,簡單來說,就是計算出,一個索引中的文字,與搜尋文字,他們之間的關聯匹配程度 Elasticsearch使用的是 term frequency / inverse document frequency演算法
ElasticSearch最佳入門實踐(五十九)基於scoll技術滾動搜尋大量資料
如果一次性要查出來比如10萬條資料,那麼效能會很差,此時一般會採取用scoll滾動查詢,一批一批的查,直到所有資料都查詢完處理完 使用scoll滾動搜尋,可以先搜尋一批資料,然後下次再搜尋一批資料,以此類推,直到搜尋出全部的資料來 scoll搜尋會在第一次搜尋的
ElasticSearch最佳入門實踐(五十八)搜尋相關引數梳理以及bouncing results問題解決方案
1、preference 決定了哪些shard會被用來執行搜尋操作 _primary, _primary_first, _local, _only_node:xyz, _prefer_node:xyz, _shards:2,3 bounci
ElasticSearch最佳入門實踐(六十二)type底層資料結構
type,是一個index中用來區分類似的資料的,類似的資料,但是可能有不同的fields,而且有不同的屬性來控制索引建立、分詞器 field的value,在底層的lucene中建立索引的時候,全部是opaque bytes型別,不區分型別的 lucene是沒有
ElasticSearch最佳入門實踐(七十二)Java 實戰
需求: (1)搜尋職位中包含technique的員工 (2)同時要求age在30到40歲之間 (3)分頁查詢,查詢第一頁 1、構建員工資訊 public class EmployeeSearchApp { public static void ma
ElasticSearch最佳入門實踐(五十)組合查詢
1、例子 GET /website/article/_search { "query": { "bool": { "must": [ { "match": { "title": "elasticsea
ElasticSearch最佳入門實踐(五十五)核心級知識點之 doc value 初步探祕
搜尋的時候,要依靠倒排索引;排序的時候,需要依靠正排索引,看到每個document的每個field,然後進行排序,所謂的正排索引,其實就是doc values 在建立索引的時候,一方面會建立倒排索引,以供搜尋用;一方面會建立正排索引,也就是doc values,
ElasticSearch最佳入門實踐(四十一)query string 的分詞以及 mapping 引入案例遺留問題的大揭祕
1、query string分詞 query string必須以和index建立時相同的analyzer進行分詞 query string對exact value和full text的區別對待 date:exact value _all:full text
ElasticSearch最佳入門實踐(三十九)倒排索引核心原理揭祕
1、例子,兩段文字 doc1:I really liked my small dogs, and I think my mom also liked them doc2:He never liked any dogs, so I hope that my m
ElasticSearch最佳入門實踐(三十八)精確匹配與全文搜尋的對比分析
1、ES中的兩種搜尋模式 1、exact value 2、full text 2、exact value 2017-01-01,exact value,搜尋的時候,必須輸入2017-01-01,才能搜尋出來。如果你輸入一個01,是搜尋不
ElasticSearch最佳入門實踐(三十七)用一個例子告訴你 mapping 到底是什麼
1、插入幾條資料 PUT /website/article/1 { "post_date": "2017-01-01", "title": "my first article", "content": "this is my first article in this w
ElasticSearch最佳入門實踐(三十六)query string search 語法以及 _all metadata 原理揭祕
1、query string基礎語法 GET /test_index/test_type/_search?q=test_field:test GET /test_index/test_type/_search?q=+test_field:test
ElasticSearch最佳入門實踐(三十四)multi-index & multi-type 搜尋模式解析以及搜尋原理解析
1、multi-index 和 multi-type 搜尋模式 告訴你如何一次性搜尋多個 index 和多個 type 下的資料 /_search:所有索引,所有type下的所有資料都搜尋出來 /index1/_search:指定一個ind
ElasticSearch最佳入門實踐(三十一)document查詢內部原理揭祕
1、客戶端傳送請求到任意一個node,成為coordinate node 對於讀請求,不一定所有的請求都發送的primary shard 上去,也可以轉發到replied shard 上去,因為replied shard 也是可以服務所有讀請求的 2、coordin