
【Keras入門日誌(3)】Keras中的序貫(Sequential)模型與函式式(Functional)模型
【時間】2018.10.31
【Keras入門日誌(3)】Keras中的序貫(Sequential)模型與函式式(Functional)模型
概述
本文主要介紹了Keras中的序貫(Sequential)模型與函式式(Functional)模型的基本使用方法,並在各部分的最後提供了一些具體程式碼例子。本文的內容主要來自《Keras中文文件》,在此基礎上進行一些補充,
連結是 https://keras-cn.readthedocs.io/en/latest/getting_started/sequential_model/ 以及
https://keras-cn.readthedocs.io/en/latest/getting_started/functional_API/
一、序貫(Sequential)模型
序貫模型是多個網路層的線性堆疊,也就是“一條路走到黑”。
1.1 構造序貫(Sequential)模型的兩種方法
-
方法一:通過向Sequential模型傳遞一個layer的list來構造該模型:
from keras.models import Sequential from keras.layers import Dense, Activation model = Sequential([Dense(32, units=784), Activation('relu'), Dense(10), Activation('softmax'), ])
-
方法二:通過.add()方法一個個的將layer加入模型中:
model = Sequential()
model.add(Dense(32, input_shape=(784,)))
model.add(Activation('relu'))1.2.指定模型輸入資料的shape
模型需要知道輸入資料的shape,因此,Sequential的第一層需要接受一個關於輸入資料shape的引數,後面的各個層則可以自動的推匯出中間資料的shape,因此不需要為每個層都指定這個引數。有幾種方法來為第一層指定輸入資料的shape
-
傳遞一個input_shape
的關鍵字引數給第一層,input_shape是一個tuple型別的資料,其中也可以填入None,如果填入None則表示此位置可能是任何正整數。資料的batch大小不應包含在其中。 -
有些2D層,如Dense,支援通過指定其輸入維度input_dim來隱含的指定輸入資料shape,是一個Int型別的資料。一些3D的時域層支援通過引數input_dim和input_length來指定輸入shape。
-
如果你需要為輸入指定一個固定大小的batch_size(常用於stateful RNN網路),可以傳遞batch_size引數到一個層中,例如你想指定輸入張量的batch大小是32,資料shape是(6,8),則你需要傳遞batch_size=32和input_shape=(6,8)。
例如:
model = Sequential()
model.add(Dense(32, input_dim=784))
model = Sequential()
model.add(Dense(32, input_shape=(784,)))1.3模型編譯
在訓練模型之前,我們需要通過compile來對學習過程進行配置。compile接收三個引數:
-
優化器optimizer:該引數可指定為已預定義的優化器名,如rmsprop、adagrad,或一個Optimizer類的物件,詳情見optimizers
-
損失函式loss:該引數為模型試圖最小化的目標函式,它可為預定義的損失函式名,如categorical_crossentropy、mse,也可以為一個損失函式。詳情見losses
-
指標列表metrics:對分類問題,我們一般將該列表設定為metrics=['accuracy']。指標可以是一個預定義指標的名字,也可以是一個使用者定製的函式.指標函式應該返回單個張量,或一個完成metric_name - > metric_value對映的字典.請參考效能評估
例如:
# For a multi-class classification problem
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
# For a binary classification problem
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
# For a mean squared error regression problem
model.compile(optimizer='rmsprop',
loss='mse')
# For custom metrics
import keras.backend as K
def mean_pred(y_true, y_pred):
return K.mean(y_pred)
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy', mean_pred])1.4. 模型訓練
Keras以Numpy陣列作為輸入資料和標籤的資料型別。訓練模型一般使用fit函式,該函式的詳情見這裡。下面是一些例子。
# For a single-input model with 2 classes (binary classification):
model = Sequential()
model.add(Dense(32, activation='relu', input_dim=100))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
# Generate dummy dataimport numpy as np
data = np.random.random((1000, 100))
labels = np.random.randint(2, size=(1000, 1)) # 2 means range(0,2)
# Train the model, iterating on the data in batches of 32 samples
model.fit(data, labels, epochs=10, batch_size=32)
# For a single-input model with 10 classes (categorical classification):
model = Sequential()
model.add(Dense(32, activation='relu', input_dim=100)) # 32 means 32 neuron
model.add(Dense(10, activation='softmax'))
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
# Generate dummy dataimport numpy as np
data = np.random.random((1000, 100))
labels = np.random.randint(10, size=(1000, 1))
# Convert labels to categorical one-hot encoding
one_hot_labels = keras.utils.to_categorical(labels, num_classes=10)
# Train the model, iterating on the data in batches of 32 samples
model.fit(data, one_hot_labels, epochs=10, batch_size=32)1.5 具體例子
這裡是一些幫助你開始的例子
在Keras程式碼包的examples資料夾中,你將找到使用真實資料的示例模型:
-
CIFAR10 小圖片分類:使用CNN和實時資料提升
-
IMDB 電影評論觀點分類:使用LSTM處理成序列的詞語
-
Reuters(路透社)新聞主題分類:使用多層感知器(MLP)
-
MNIST手寫數字識別:使用多層感知器和CNN
-
字元級文字生成:使用LSTM ...
1)基於多層感知器的softmax多分類:
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation
from keras.optimizers import SGD
# Generate dummy dataimport numpy as np
x_train = np.random.random((1000, 20))
y_train = keras.utils.to_categorical(np.random.randint(10, size=(1000, 1)), num_classes=10)
x_test = np.random.random((100, 20))
y_test = keras.utils.to_categorical(np.random.randint(10, size=(100, 1)), num_classes=10)
model = Sequential()
# Dense(64) is a fully-connected layer with 64 hidden units.# in the first layer, you must specify the expected input data shape:# here, 20-dimensional vectors.
model.add(Dense(64, activation='relu', input_dim=20))
model.add(Dropout(0.5))
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy',
optimizer=sgd,
metrics=['accuracy'])
model.fit(x_train, y_train,
epochs=20,
batch_size=128)
score = model.evaluate(x_test, y_test, batch_size=128)【補充說明】
1.keras.utils.to_categorical函式
to_categorical(y, num_classes=None, dtype='float32')將整型標籤轉為onehot。y為int陣列,num_classes為標籤類別總數,大於max(y)(標籤從0開始的)。
返回:如果num_classes=None,返回len(y) * [max(y)+1](維度,m*n表示m行n列矩陣,下同),否則為len(y) * num_classes。
2)MLP的二分類:
import numpy as np
from keras.models import Sequential
from keras.layers import Dense, Dropout
# Generate dummy data
x_train = np.random.random((1000, 20))
y_train = np.random.randint(2, size=(1000, 1))
x_test = np.random.random((100, 20))
y_test = np.random.randint(2, size=(100, 1))
model = Sequential()
model.add(Dense(64, input_dim=20, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
model.fit(x_train, y_train,
epochs=20,
batch_size=128)
score = model.evaluate(x_test, y_test, batch_size=128)3)類似VGG的卷積神經網路:
import numpy as np
import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras.optimizers import SGD
# Generate dummy data
x_train = np.random.random((100, 100, 100, 3))
y_train = keras.utils.to_categorical(np.random.randint(10, size=(100, 1)), num_classes=10)
x_test = np.random.random((20, 100, 100, 3))
y_test = keras.utils.to_categorical(np.random.randint(10, size=(20, 1)), num_classes=10)
model = Sequential()
# input: 100x100 images with 3 channels -> (100, 100, 3) tensors.# this applies 32 convolution filters of size 3x3 each.
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(100, 100, 3)))
model.add(Conv2D(32, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy', optimizer=sgd)
model.fit(x_train, y_train, batch_size=32, epochs=10)
score = model.evaluate(x_test, y_test, batch_size=32)4)使用LSTM的序列分類 ( LSTM(Long Short-Term Memory)是長短期記憶網路)
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.layers import Embedding
from keras.layers import LSTM
model = Sequential()
model.add(Embedding(max_features, output_dim=256))
model.add(LSTM(128))
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
model.fit(x_train, y_train, batch_size=16, epochs=10)
score = model.evaluate(x_test, y_test, batch_size=16)
5)使用1D卷積的序列分類
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.layers import Embedding
from keras.layers import Conv1D, GlobalAveragePooling1D, MaxPooling1D
model = Sequential()
model.add(Conv1D(64, 3, activation='relu', input_shape=(seq_length, 100)))
model.add(Conv1D(64, 3, activation='relu'))
model.add(MaxPooling1D(3))
model.add(Conv1D(128, 3, activation='relu'))
model.add(Conv1D(128, 3, activation='relu'))
model.add(GlobalAveragePooling1D())
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
model.fit(x_train, y_train, batch_size=16, epochs=10)
score = model.evaluate(x_test, y_test, batch_size=16)二、函式式(Functional)模型
我們起初將Functional一詞譯作泛型,想要表達該類模型能夠表達任意張量對映的含義,但表達的不是很精確,在Keras 2裡我們將這個詞改譯為“函式式”,對函數語言程式設計有所瞭解的同學應能夠快速get到該類模型想要表達的含義。函式式模型稱作Functional,但它的類名是Model,因此我們有時候也用Model來代表函式式模型。
Keras函式式模型介面是使用者定義多輸出模型、非迴圈有向模型或具有共享層的模型等複雜模型的途徑。一句話,只要你的模型不是類似VGG一樣一條路走到黑的模型,或者你的模型需要多於一個的輸出,那麼你總應該選擇函式式模型。函式式模型是最廣泛的一類模型,序貫模型(Sequential)只是它的一種特殊情況。
這部分的文件假設你已經對Sequential模型已經比較熟悉
讓我們從簡單一點的模型開始
2.1.第一個模型:全連線網路
Sequential當然是實現全連線網路的最好方式,但我們從簡單的全連線網路開始,有助於我們學習這部分的內容。在開始前,有幾個概念需要澄清:
-
層物件接受張量為引數,返回一個張量。
-
輸入是張量,輸出也是張量的一個框架就是一個模型,通過Model定義。
-
這樣的模型可以被像Keras的Sequential一樣被訓練
from keras.layers import Input, Dense
from keras.models import Model
# This returns a tensor
inputs = Input(shape=(784,))
# a layer instance is callable on a tensor, and returns a tensor
x = Dense(64, activation='relu')(inputs)
x = Dense(64, activation='relu')(x)
predictions = Dense(10, activation='softmax')(x)
# This creates a model that includes# the Input layer and three Dense layers
model = Model(inputs=inputs, outputs=predictions)
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit(data, labels) # starts training2.2.所有的模型都是可呼叫的,就像層一樣
利用函式式模型的介面,我們可以很容易的重用已經訓練好的模型:你可以把模型當作一個層一樣,通過提供一個tensor來呼叫它。注意當你呼叫一個模型時,你不僅僅重用了它的結構,也重用了它的權重。
x = Input(shape=(784,))
# This works, and returns the 10-way softmax we defined above.
y = model(x)這種方式可以允許你快速的建立能處理序列訊號的模型,你可以很快將一個影象分類的模型變為一個對視訊分類的模型,只需要一行程式碼:
from keras.layers import TimeDistributed
# Input tensor for sequences of 20 timesteps,# each containing a 784-dimensional vector
input_sequences = Input(shape=(20, 784))
# This applies our previous model to every timestep in the input sequences.# the output of the previous model was a 10-way softmax,# so the output of the layer below will be a sequence of 20 vectors of size 10.
processed_sequences = TimeDistributed(model)(input_sequences)【補充說明】
1、TimeDistributed層
TimeDistributed這個層還是比較難理解的。事實上通過這個層我們可以實現從二維像三維的過渡。 考慮一批32個樣本,其中每個樣本是一個由16個維度組成的10個向量的序列。該層的批輸入形狀然後(32, 10, 16)。
TimeDistributed層的作用就是把Dense層應用到這10個具體的向量上,對每一個向量進行了一個Dense操作,假設是下面這段程式碼:
model = Sequential()model.add(TimeDistributed(Dense(8), input_shape=(10, 16)))輸出還是10個向量,但是輸出的維度由16變成了8,也就是(32,10,8)。
事實上,TimeDistributed層給予了模型一種一對多,多對多的能力,增加了模型的維度。

2.3.多輸入和多輸出模型
使用函式式模型的一個典型場景是搭建多輸入、多輸出的模型。
考慮這樣一個模型。我們希望預測Twitter上一條新聞會被轉發和點贊多少次。模型的主要輸入是新聞本身,也就是一個詞語的序列。但我們還可以擁有額外的輸入,如新聞釋出的日期等。這個模型的損失函式將由兩部分組成,輔助的損失函式評估僅僅基於新聞本身做出預測的情況,主損失函式評估基於新聞和額外資訊的預測的情況,即使來自主損失函式的梯度發生彌散,來自輔助損失函式的資訊也能夠訓練Embeddding和LSTM層。在模型中早點使用主要的損失函式是對於深度網路的一個良好的正則方法。總而言之,該模型框圖如下:
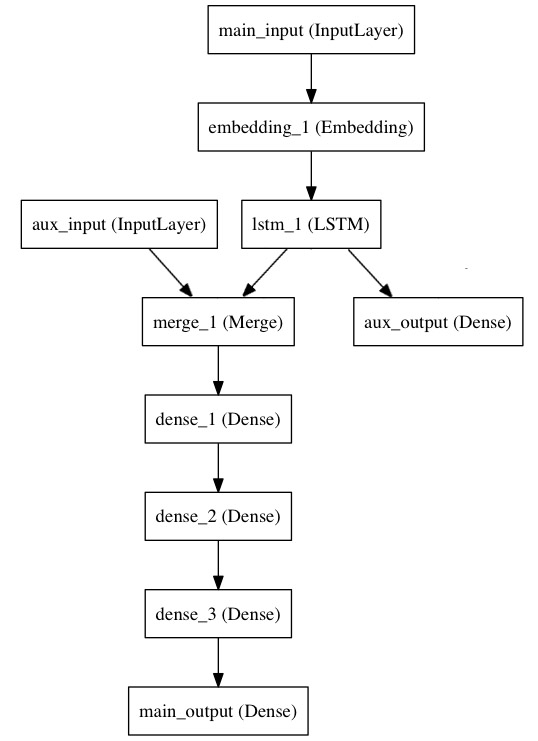
讓我們用函式式模型來實現這個框圖
主要的輸入接收新聞本身,即一個整數的序列(每個整數編碼了一個詞)。這些整數位於1到10000之間(即我們的字典有10000個詞)。這個序列有100個單詞。
from keras.layers import Input, Embedding, LSTM, Dense
from keras.models import Model
# Headline input: meant to receive sequences of 100 integers, between 1 and 10000.# Note that we can name any layer by passing it a "name" argument.
main_input = Input(shape=(100,), dtype='int32', name='main_input')
# This embedding layer will encode the input sequence# into a sequence of dense 512-dimensional vectors.
x = Embedding(output_dim=512, input_dim=10000, input_length=100)(main_input)
# A LSTM will transform the vector sequence into a single vector,# containing information about the entire sequence
lstm_out = LSTM(32)(x)
然後,我們插入一個額外的損失,使得即使在主損失很高的情況下,LSTM和Embedding層也可以平滑的訓練。
auxiliary_output = Dense(1, activation='sigmoid', name='aux_output')(lstm_out)
再然後,我們將LSTM與額外的輸入資料串聯起來組成輸入,送入模型中:
auxiliary_input = Input(shape=(5,), name='aux_input')
x = keras.layers.concatenate([lstm_out, auxiliary_input])
# We stack a deep densely-connected network on top
x = Dense(64, activation='relu')(x)
x = Dense(64, activation='relu')(x)
x = Dense(64, activation='relu')(x)
# And finally we add the main logistic regression layer
main_output = Dense(1, activation='sigmoid', name='main_output')(x)最後,我們定義整個2輸入,2輸出的模型:
model = Model(inputs=[main_input, auxiliary_input], outputs=[main_output, auxiliary_output])模型定義完畢,下一步編譯模型。我們給額外的損失賦0.2的權重。我們可以通過關鍵字引數loss_weights或loss來為不同的輸出設定不同的損失函式或權值。這兩個引數均可為Python的列表或字典。這裡我們給loss傳遞單個損失函式,這個損失函式會被應用於所有輸出上。
model.compile(optimizer='rmsprop', loss='binary_crossentropy',
loss_weights=[1., 0.2])
編譯完成後,我們通過傳遞訓練資料和目標值訓練該模型:
model.fit([headline_data, additional_data], [labels, labels],
epochs=50, batch_size=32)
因為我們輸入和輸出是被命名過的(在定義時傳遞了“name”引數),我們也可以用下面的方式編譯和訓練模型:
model.compile(optimizer='rmsprop',
loss={'main_output': 'binary_crossentropy', 'aux_output': 'binary_crossentropy'},
loss_weights={'main_output': 1., 'aux_output': 0.2})
# And trained it via:
model.fit({'main_input': headline_data, 'aux_input': additional_data},
{'main_output': labels, 'aux_output': labels},
epochs=50, batch_size=32)2.4 共享層
另一個使用函式式模型的場合是使用共享層的時候。
考慮微博資料,我們希望建立模型來判別兩條微博是否是來自同一個使用者,這個需求同樣可以用來判斷一個使用者的兩條微博的相似性。
一種實現方式是,我們建立一個模型,它分別將兩條微博的資料對映到兩個特徵向量上,然後將特徵向量串聯並加一個logistic迴歸層,輸出它們來自同一個使用者的概率。這種模型的訓練資料是一對對的微博。
因為這個問題是對稱的,所以處理第一條微博的模型當然也能重用於處理第二條微博。所以這裡我們使用一個共享的LSTM層來進行對映。
首先,我們將微博的資料轉為(140,256)的矩陣,即每條微博有140個字元,每個單詞的特徵由一個256維的詞向量表示,向量的每個元素為1表示某個字元出現,為0表示不出現,這是一個one-hot編碼。
之所以是(140,256)是因為一條微博最多有140個字元,而擴充套件的ASCII碼錶編碼了常見的256個字元。原文中此處為Tweet,所以對外國人而言這是合理的。如果考慮中文字元,那一個單詞的詞向量就不止256了。
import keras
from keras.layers import Input, LSTM, Dense
from keras.models import Model
tweet_a = Input(shape=(140, 256))
tweet_b = Input(shape=(140, 256))
若要對不同的輸入共享同一層,就初始化該層一次,然後多次呼叫它
# This layer can take as input a matrix# and will return a vector of size 64
shared_lstm = LSTM(64)
# When we reuse the same layer instance# multiple times, the weights of the layer# are also being reused# (it is effectively *the same* layer)
encoded_a = shared_lstm(tweet_a)
encoded_b = shared_lstm(tweet_b)
# We can then concatenate the two vectors:
merged_vector = keras.layers.concatenate([encoded_a, encoded_b], axis=-1)
# And add a logistic regression on top
predictions = Dense(1, activation='sigmoid')(merged_vector)
# We define a trainable model linking the# tweet inputs to the predictions
model = Model(inputs=[tweet_a, tweet_b], outputs=predictions)
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
model.fit([data_a, data_b], labels, epochs=10)
2.5 層“節點”的概念
無論何時,當你在某個輸入上呼叫層時,你就建立了一個新的張量(即該層的輸出),同時你也在為這個層增加一個“(計算)節點”。這個節點將輸入張量對映為輸出張量。當你多次呼叫該層時,這個層就有了多個節點,其下標分別為0,1,2...
在上一版本的Keras中,你可以通過layer.get_output()方法來獲得層的輸出張量,或者通過layer.output_shape獲得其輸出張量的shape。這個版本的Keras你仍然可以這麼做(除了layer.get_output()被output替換)。但如果一個層與多個輸入相連,會出現什麼情況呢?
如果層只與一個輸入相連,那沒有任何困惑的地方。.output將會返回該層唯一的輸出
a = Input(shape=(140, 256))
lstm = LSTM(32)
encoded_a = lstm(a)
assert lstm.output == encoded_a但當層與多個輸入相連時,會出現問題
a = Input(shape=(140, 256))
b = Input(shape=(140, 256))
lstm = LSTM(32)
encoded_a = lstm(a)
encoded_b = lstm(b)
lstm.output上面這段程式碼會報錯
>> AssertionError: Layer lstm_1 has multiple inbound nodes,
hence the notion of "layer output" is ill-defined.
Use `get_output_at(node_index)` instead.
通過下面這種呼叫方式即可解決
assert lstm.get_output_at(0) == encoded_a
assert lstm.get_output_at(1) == encoded_b對於input_shape和output_shape也是一樣,如果一個層只有一個節點,或所有的節點都有相同的輸入或輸出shape,那麼input_shape和output_shape都是沒有歧義的,並也只返回一個值。但是,例如你把一個相同的Conv2D應用於一個大小為(32,32,3)的資料,然後又將其應用於一個(64,64,3)的資料,那麼此時該層就具有了多個輸入和輸出的shape,你就需要顯式的指定節點的下標,來表明你想取的是哪個了
a = Input(shape=(32, 32, 3))
b = Input(shape=(64, 64, 3))
conv = Conv2D(16, (3, 3), padding='same')
conved_a = conv(a)
# Only one input so far, the following will work:assert conv.input_shape == (None, 32, 32, 3)
conved_b = conv(b)
# now the `.input_shape` property wouldn't work, but this does:assert conv.get_input_shape_at(0) == (None, 32, 32, 3)
assert conv.get_input_shape_at(1) == (None, 64, 64, 3)2.6 更多的例子
程式碼示例依然是學習的最佳方式,這裡是更多的例子
inception模型
1)inception的詳細結構參見Google的這篇論文:Going Deeper with Convolutions
中英對照翻譯連結:https://blog.csdn.net/c_chuxin/article/details/82856502
from keras.layers import Conv2D, MaxPooling2D, Input
input_img = Input(shape=(256, 256, 3))
tower_1 = Conv2D(64, (1, 1), padding='same', activation='relu')(input_img)
tower_1 = Conv2D(64, (3, 3), padding='same', activation='relu')(tower_1)
tower_2 = Conv2D(64, (1, 1), padding='same', activation='relu')(input_img)
tower_2 = Conv2D(64, (5, 5), padding='same', activation='relu')(tower_2)
tower_3 = MaxPooling2D((3, 3), strides=(1, 1), padding='same')(input_img)
tower_3 = Conv2D(64, (1, 1), padding='same', activation='relu')(tower_3)
output = keras.layers.concatenate([tower_1, tower_2, tower_3], axis=1)2)卷積層的殘差連線
殘差網路(Residual Network)的詳細資訊請參考這篇文章:Deep Residual Learning for Image Recognition
中英對照翻譯連結:https://blog.csdn.net/c_chuxin/article/details/82948733
rom keras.layers import Conv2D, Input
# input tensor for a 3-channel 256x256 image
x = Input(shape=(256, 256, 3))
# 3x3 conv with 3 output channels (same as input channels)
y = Conv2D(3, (3, 3), padding='same')(x)
# this returns x + y.
z = keras.layers.add([x, y])3)共享視覺模型
該模型在兩個輸入上重用了影象處理的模型,用來判別兩個MNIST數字是否是相同的數字
from keras.layers import Conv2D, MaxPooling2D, Input, Dense, Flatten
from keras.models import Model
# First, define the vision modules
digit_input = Input(shape=(27, 27, 1))
x = Conv2D(64, (3, 3))(digit_input)
x = Conv2D(64, (3, 3))(x)
x = MaxPooling2D((2, 2))(x)
out = Flatten()(x)
vision_model = Model(digit_input, out)
# Then define the tell-digits-apart model
digit_a = Input(shape=(27, 27, 1))
digit_b = Input(shape=(27, 27, 1))
# The vision model will be shared, weights and all
out_a = vision_model(digit_a)
out_b = vision_model(digit_b)
concatenated = keras.layers.concatenate([out_a, out_b])
out = Dense(1, activation='sigmoid')(concatenated)
classification_model = Model([digit_a, digit_b], out)4)視覺問答模型
在針對一幅圖片使用自然語言進行提問時,該模型能夠提供關於該圖片的一個單詞的答案
這個模型將自然語言的問題和圖片分別對映為特徵向量,將二者合併後訓練一個logistic迴歸層,從一系列可能的回答中挑選一個。
from keras.layers import Conv2D, MaxPooling2D, Flatten
from keras.layers import Input, LSTM, Embedding, Dense
from keras.models import Model, Sequential
# First, let's define a vision model using a Sequential model.# This model will encode an image into a vector.
vision_model = Sequential()
vision_model.add(Conv2D(64, (3, 3), activation='relu', padding='same', input_shape=(224, 224, 3)))
vision_model.add(Conv2D(64, (3, 3), activation='relu'))
vision_model.add(MaxPooling2D((2, 2)))
vision_model.add(Conv2D(128, (3, 3), activation='relu', padding='same'))
vision_model.add(Conv2D(128, (3, 3), activation='relu'))
vision_model.add(MaxPooling2D((2, 2)))
vision_model.add(Conv2D(256, (3, 3), activation='relu', padding='same'))
vision_model.add(Conv2D(256, (3, 3), activation='relu'))
vision_model.add(Conv2D(256, (3, 3), activation='relu'))
vision_model.add(MaxPooling2D((2, 2)))
vision_model.add(Flatten())
# Now let's get a tensor with the output of our vision model:
image_input = Input(shape=(224, 224, 3))
encoded_image = vision_model(image_input)
# Next, let's define a language model to encode the question into a vector.# Each question will be at most 100 word long,# and we will index words as integers from 1 to 9999.
question_input = Input(shape=(100,), dtype='int32')
embedded_question = Embedding(input_dim=10000, output_dim=256, input_length=100)(question_input)
encoded_question = LSTM(256)(embedded_question)
# Let's concatenate the question vector and the image vector:
merged = keras.layers.concatenate([encoded_question, encoded_image])
# And let's train a logistic regression over 1000 words on top:
output = Dense(1000, activation='softmax')(merged)
# This is our final model:
vqa_model = Model(inputs=[image_input, question_input], outputs=output)
# The next stage would be training this model on actual data.
5)視訊問答模型
在做完圖片問答模型後,我們可以快速將其轉為視訊問答的模型。在適當的訓練下,你可以為模型提供一個短視訊(如100幀)然後向模型提問一個關於該視訊的問題,如“what sport is the boy playing?”->“football”
from keras.layers import TimeDistributed
video_input = Input(shape=(100, 224, 224, 3))
# This is our video encoded via the previously trained vision_model (weights are reused)
encoded_frame_sequence = TimeDistributed(vision_model)(video_input) # the output will be a sequence of vectors
encoded_video = LSTM(256)(encoded_frame_sequence) # the output will be a vector
# This is a model-level representation of the question encoder, reusing the same weights as before:
question_encoder = Model(inputs=question_input, outputs=encoded_question)
# Let's use it to encode the question:
video_question_input = Input(shape=(100,), dtype='int32')
encoded_video_question = question_encoder(video_question_input)
# And this is our video question answering model:
merged = keras.layers.concatenate([encoded_video, encoded_video_question])
output = Dense(1000, activation='softmax')(merged)
video_qa_model = Model(inputs=[video_input, video_question_input], outputs=output)