
redis基礎學習總結
一、redis是什麼?
1.redis是一個記憶體快取記憶體資料庫。它不是一個關係型資料庫,redis是一個key-value儲存系統,Redis是單執行緒的,基於事件驅動的;
二、redis有什麼特點?
1.redis 以記憶體作為資料儲存的截止,讀寫的效率很高
2.儲存在redis中的資料是持久化的,斷電之後,資料不會丟失。redis的儲存分為記憶體儲存,磁碟儲存和log檔案,重啟後,redis可以從磁碟重新將資料載入到記憶體中,這個可以通過配置檔案進行配置,來實現redis的持久化。
3.redis支援主從模式,配置redis叢集,便於支撐更大型的專案。
4.它具有豐富的資料型別,string,list,set,zset(sorted set),hash。
5.redis的所有操作都是原子性的,要麼成功執行,要麼失敗完全不執行。單個操作是原子性的。多個操作也支援事物。
6.redis有著更為複雜的資料結構,並且提供對他們的原子性操作,不同於其他資料庫,redis的資料型別基於基本資料結構的同時對程式設計師透明,無需進行額外的抽象。
7.redis執行在記憶體中,但是可以持久化到磁碟,所以在對不同資料進行高速讀寫的時候需要權衡記憶體,資料量不能大於硬體記憶體。在記憶體中的一個優點是,相比在磁碟上覆雜的資料結構,記憶體中操作起來就比較簡單。
三、redis的應用場景
眾多語言都支援redis,因為redis交換資料比較快,所以在服務其中常用來儲存一些需要頻繁調取的書記,這樣可以大大節省系統直接讀取磁碟來獲得資料的i/o開銷,可以極大提升速度。
拿大型網站來舉個例子,比如某網站首頁一天有100萬人訪問,其中有一個板塊為推薦新聞。要是直接從資料庫查詢,那麼一天就要多消耗100萬次資料庫請求。上面已經說過,Redis支援豐富的資料型別,所以這完全可以用Redis來完成,將這種熱點資料存到Redis(記憶體)中,要用的時候,直接從記憶體取,極大的提高了速度和節約了伺服器的開銷
四、redis的資料型別
1.string 是 redis 最基本的型別,而且 string 型別是二進位制安全的。意思是 redis 的 string 可以包含任何資料。比如 jpg 圖片或者序列化的物件。從內部實現來看其實 string 可以看作 byte 陣列,最大上限是 1G 位元組。下面是 string 型別的定義。
set key value 設定 key 對應的值為 string 型別的 value,返回 1 表示成功,0 失敗 setnx key value 同上,如果 key 已經存在,返回 0 。nx 是 not exist 的意思 get key 獲取 key 對應的 string 值,如果 key 不存在返回 nil getset key value 原子的設定 key 的值,並返回 key 的舊值。如果 key 不存在返回 nil mget key1 key2 ... keyN 一次獲取多個 key 的值,如果對應 key 不存在,則對應返回 nil。
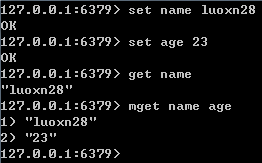
2.list 型別實質是一個每個元素都是string型別的雙向連結串列,所以push和pop命令的演算法時間複雜度都是O(1),另外list還會記錄連結串列的長度,所以llen操作也是O(1)。連結串列的最大長度是(2的32次方-1)。我們可以通過push,pop操作從連結串列的頭部或者尾部新增刪除元素。這使得list既可以用作棧,也可以用作佇列。有意思的是list的 pop 操作還有阻塞版本的。當我們[lr]pop一個list物件是,如果list是空,或者不存在,會立即返回nil。但是阻塞版本的b[lr]pop 可以則可以阻塞,當然可以加超時時間,超時後也會返回nil。
lpush key string 在 key 對應 list 的頭部新增字串元素,返回 1 表示成功,0 表示 key 存在且不是 list型別 rpush key string 同上,在尾部新增 lpop key 從 list 的頭部刪除元素,並返回刪除元素。如果 key 對應 list 不存在或者是空返回 nil,如果 key 對應值不是 list 返回錯誤 rpop key 同上,但是從尾部刪除 llen key 返回 key 對應 list 的長度,key 不存在返回 0,如果 key 對應型別不是 list 返回錯誤 lrange key start end 返回指定區間內的元素,下標從 0 開始,負值表示從後面計算,-1 表示倒數第一個元素 ,key 不存在返回空列表 ltrim key start end 擷取 list,保留指定區間內元素,成功返回 1,key 不存在返回錯誤

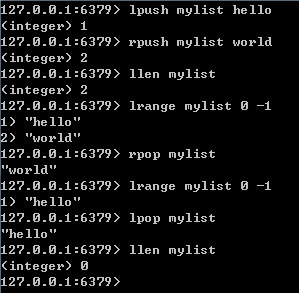
3.redis 的 set 是 string 型別的無序集合。 set 元素最大可以包含(2 的 32 次方-1)個元素。 set 的是通 過 hash table 實現的,所以新增,刪除,查詢的複雜度都是 O(1)。 hash table 會隨著新增或者刪除自 動的調整大小。需要注意的是調整 hash table 大小時候需要同步(獲取寫鎖)會阻塞其他讀寫操作。
sadd key value 新增一個 string 元素到,key 對應的 set 集合中,成功返回 1,如果元素已經在集合中返回 0,key 對應的 set 不存在返回錯誤 srem key value 從 key 對應 set 中移除給定元素,成功返回 1,如果 value 在集合中不存在或者key 不存在返回 0,如果 key 對應的不是 set 型別的值返回錯誤 spop key 刪除並返回 key 對應 set 中隨機的一個元素,如果 set 是空或者 key 不存在返回 nil srandmember key 同 spop,隨機取 set 中的一個元素,但是不刪除元素 smove srckey dstkey value 從 srckey 對應 set 中移除 value 並新增到 dstkey 對應 set 中,整個操作是原子的。成功返回 1,如果 value 在 srckey 中不存在返回 0,如果 key 不是 set 型別返回錯誤 scard key 返回 set 的元素個數,如果 set 是空或者 key 不存在返回 0 sismember key value 判斷 value 是否在 set 中,存在返回 1, 0 表示不存在或者 key 不存在
smembers key 返回 key 對應 set 的所有元素,結果是無序的

4.zset 和 set 一樣, sorted set 也是 string 型別元素的集合,不同的是每個元素都會關聯一個 double 型別 的 score ,元素順序有score決定。 sorted set 的實現是 skip list 和 hash table 的混合體。 當元素被新增到集合中時,一個元素到 score 的對映被新增到 hash table 中,所以給定一個元素獲取 score 的開銷是 O(1),另一個 score 到元素 的對映被新增到 skip list 並按照 score 排序,所以就可以有序的獲取集合中的元素。
zadd key score member 新增元素到集合,元素在集合中存在則更新對應 score,當該member已存在時,返回0,並更新該member的score值 zrem key member 刪除指定元素, 1 表示成功,如果元素不存在返回 0 zincrby key n member 增加對應 member 的 score 值,然後移動元素並保持 skip list 保持有序。返回更新後的 score 值 zrank key member 返回指定元素在集合中的排名(下標) ,集合中元素是按 score 從小到大排序的 zrevrank key member 同上,但是集合中元素是按 score 從大到小排序 zrange key start end 類似 lrange 操作從集合中去指定區間的元素。返回的是有序結果 zrevrange key start end 同上,返回結果是按 score 逆序的 zrangebyscore key min max 返回集合中 score 在給定區間的元素 zcount key min max 返回集合中 score 在給定區間的數量 zcard key 返回集合中元素個數 zscore key element 返回給定元素對應的 score zremrangebyrank key min max 刪除集合中排名在給定區間的元素 zremrangebyscore key min max 刪除集合中 score 在給定區間的元素

5.redis hash 是一個 string 型別的 field 和 value 的對映表。它的新增,刪除操作都是 O(1) (平均).hash特別適合用於儲存物件。相較於將物件的每個欄位存成單個 string 型別。將一個物件儲存在 hash 型別中會佔用更少的記憶體,並且可以更方便的存取整個物件。省記憶體的原因是新建一個 hash 物件時開始是用 zipmap(又稱為 small hash)來儲存的。這個 zipmap 其實並不是 hash table,但是 zipmap 相比正常的 hash 實現可以節省不少 hash 本身需要的一些元資料儲存開銷。儘管 zipmap 的新增,刪除,查詢都是 O(n),但是由於一般物件的 field 數量都不太多。所以使用 zipmap 也是很快的,也就是說新增刪除平均還是 O(1)。如果 field 或者 value 的大小超出一定限制後, redis 會在內部自動將 zipmap替換成正常的 hash 實現. 這個限制可以在配置檔案中指定。
hset key field value 設定 hash field 為指定值,如果 key 不存在,則先建立 hget key field 獲取指定的 hash field hmget key filed1....fieldN 獲取全部指定的 hash filed hmset key filed1 value1 ... filedN valueN 同時設定 hash 的多個 field hincrby key field integer 將指定的 hash filed 加上給定值 hexists key field 測試指定 field 是否存在 hdel key field 刪除指定的 hash field hlen key 返回指定 hash 的 field 數量 hkeys key 返回 hash 的所有 field hvals key 返回 hash 的所有 value hgetall key 返回 hash 的所有 filed 和 value

五、什麼是Redis快取穿透,快取雪崩?
快取穿透就是查詢一個一定不存在的資料時,由於快取中不存在,每次請求總是穿過快取,從資料庫中查詢,造成快取穿透。
快取雪崩是指在我們設定快取時採用了相同的過期時間,導致快取在某一時刻同時失效,請求全部轉發到DB,DB瞬時壓力過重雪崩。
六、redis主從複製?
主從複製
Redis主從複製配合和使用比較簡單,通過主從複製可以允許多個slave server擁有和master server相同的資料庫副本。
master可以擁有多個salve server,多個slave可以連線同一個master外,還可以連線到其他slave。主從複製不會阻塞master,同步資料時,master可以繼續處理client,提高系統伸縮性。
Redis主從複製過程:
- Salve與master建立連線,傳送sync同步命令。
- Master會啟動一個後臺程序,將資料庫快照儲存到檔案中,同時master主程序會開始收集新的寫命令快取。
- 後臺完成儲存後,就將此檔案傳送給slave。
- slave將此檔案儲存到硬碟上。
Redis環境說明:
window下Redis服務作為master主機,window的IP為192.168.1.100,虛擬機器下linux下的Redis作為slave,linux的IP為192.168.1.150。
在redis從機(linux環境)的redis.conf配置檔案中加入以下配置:

主機寫入2條記錄到資料庫,然後從從機中讀取,注意:總計無法更新值,只能讀取。
master主機 slave從機

七、reids的事物管理?
事務處理
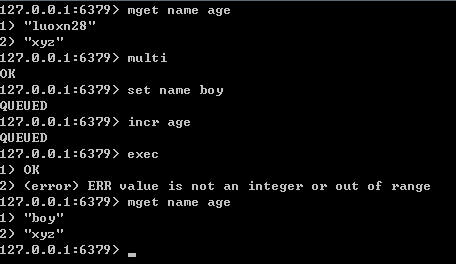
Redis對事務的支援還比較簡單,redis只能保證一個client發起的事務中的命令可以連續執行,而中間不會插入其他client的命令。當一個client在一個連線中發出multi命令時,這個連線會進入一個事務的上下文,連線後續命令不會立即執行,而是先放到一個佇列中,當執行exec命令時,redis會順序的執行佇列中的所有命令。

在事務處理中使用discard可以取消事務的處理。redis在事務中如果發生錯誤時事務退出,但是在該錯誤之前的操作無法回滾。
八、redis的持久化?
九、redis釋出、訂閱訊息?
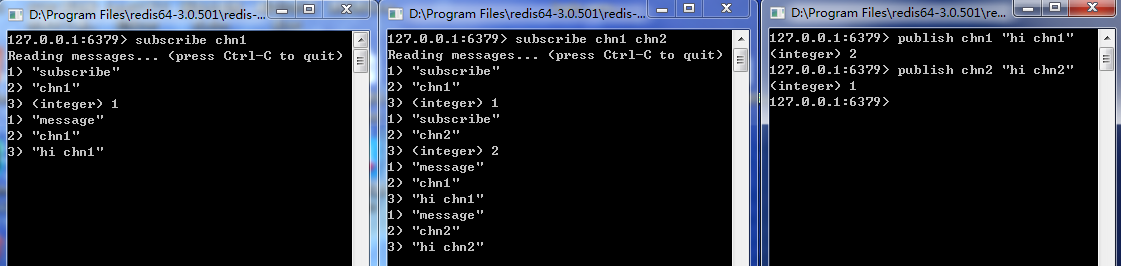
釋出訂閱(pub/sub)是一種訊息通知模式,主要的目的是截除訊息釋出者和訊息訂閱者之間的耦合,Redis作為一個pub/sub的server,在訂閱者和釋出者之間起到了訊息路由的功能。訂閱者可以通過subscribe和psubscribe命令向redis server訂閱自己感興趣的訊息型別,redis將訊息型別稱為通道(channel)。當釋出者通過publish命令向redis server傳送特定型別的資訊時,訂閱該資訊型別的全部client都會收到此訊息。
第一個redis客戶端訂閱changnel1,第二個redis客戶端訂閱channel1和channel2,第三個redis客戶端負責產生channel1和channel2訊息,然後觀察第一個和第二個redis客戶端是否收到了訂閱訊息。

十、AOF和RDB持久化
AOF持久化日誌,RDB持久化實體資料,AOF優先順序大於RDB。
1.AOF持久化
機制:通過定時事件將aof緩衝區內的資料定時寫到磁碟上。
2.AOF重寫
為了減少AOF大小,Redis提供了AOF重寫功能,這個重寫功能做的工作就是建立一個新AOF檔案代替老的AOF,並且這個新的AOF檔案沒有一條冗餘指令。(例如對list先插入A/B/C,後刪除B/C,再插入D共6條指令,最終狀態為A/D,只需1條指令就可以)
實現原理就是讀現有資料庫的狀態,根據狀態反推指令,跟之前的AOF無關。同樣,為了避免長時間耗時,重寫工作放在子程序進行。
3.RDB持久化
SAVE和BGSAVE兩個命令都是用於生成RDB檔案,區別在於BGSAVE會fork出一個子程序單獨進行,不影響Redis處理正常請求。
定時和定次數後進行持久化操作。
簡而言之,RDB的過程其實是比較簡單的,滿足條件後直接去寫RDB檔案就結束了。