
python新手總結(二)
random模組
隨機小數
- random
- uniform
隨機整數
- randint
- randrange
隨機抽取
- choice
- sample
打亂順序
- shuffle
random.random() 生成:0<n<1.0
uniform(x,y) 一定範圍的隨機浮點數 (包左包右)
random.uniform(x,y)randint(x,y) 隨機整數 (包左包右)
randrange(x,y,z) 隨機整數(包左不包右)
random.randrange(10,100,4) #輸出為10到100內以4遞增的序列[10,14,18,22...]
choice(seq) 從序列中獲取一個隨機元素,引數seq表示有序型別,並不是一種特定型別,泛指list tuple 字串等
import random random.choice(range(10)) #輸出0到10內隨機整數 random.choice(range(10,100,2)) #輸出隨機值[10,12,14,16...] random.choice("I love python") #輸出隨機字元I,o,v,p,y... random.choice(("I love python")) #同上 random.choice(["I love python"]) #輸出“I love python” random.choice("I","love","python") #Error random.choice(("I","love","python")) #輸出隨機字串“I”,“love”,“python” random.choice(["I","love","python"]) #輸出隨機字串“I”,“love”,“python”
shuffle(list) 用於將一個列表中的元素打亂
sample() 從指定序列中隨機獲取k個元素作為一個片段返回,sample不會改變原有序列
a='1232445566'
b=[1,2,3,4,4,5]
print(random.sample(b,2))
print(random.sample(a,2))time 時間模組
time.strftime('%Y-%m-%d %H:%M:%S')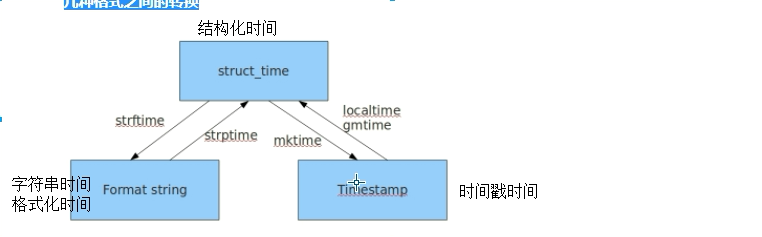
sys模組
sys 是與python直譯器相關的
sys.path 尋找檔案的路徑
sys.modules 匯入多少路徑
在編譯器不能執行
name=sys.argv[1] # 有點類似input() 不過input是阻塞的 pwd=sys.argv[2] if name='alex' and pwd =='alex3714': print('執行以下程式碼') else: exit()
os模組

print(os.getcwd()) # 在哪個地方執行這個檔案,getcwd的結果就是哪個路徑
removedirs
遞歸向上刪除資料夾,只要刪除當前目錄之後,發現上一級目錄也為空了,就把上一級目錄刪除
如果發現上一級目錄有其他檔案,就停止
os.listdir() (重要)列出指定目錄下的所有檔案和子目錄,包括隱藏檔案,並以列表方法列印

print(os.path.dirname(os.path.dirname(__file__)))#上一級再上一級目錄,也就是工作區序列化
得到一個字串的結果,過程就叫序列化
字典/列表/數字/物件 -序列化-->字串
為什麼要序列化
- 要把內容寫入檔案
- 網路傳輸資料
eval不能隨便用
dump dumps load loads
import json
dic={'aaa':'bbb','ccc':'ddd'}
str_dic=json.dumps(dic) # 序列化
print(dic)
print(str_dic,type(str_dic))
with open('json_dump','w') as f:
# f.write(str_dic) # 反序列化
json.dump(dic,f)
ret=json.loads(str_dic) # 反序列化
print(ret,type(ret))
with open('json_dump1') as f:
print(type(json.load(f)))json的限制
json格式的key必須是字串資料型別,如果是數字為key那麼dump之後會強行轉成字串資料型別
json格式中的字串只能是雙引號
json是否支援元祖,對元組做value的字典會把元組強制轉換成列表
dic={'abc':(1,2,3)} str_dic=json.dumps(dic) print(str_dic)json是否支援元組做key,會報錯
pickle
- pickle 支援幾乎所有物件
dic={1:(12,3,4),('a','b'):4}
pic_dic=pickle.dumps(dic)# 序列化 看不見 bytes型別
print(pic_dic)
new_dic=pickle.loads(pic_dic)# 反序列化
對於物件的序列化需要這個物件對應的類在記憶體中
dump的結果是bytes, dump用的f檔案控制代碼需要以wb的形式開啟,load所用的f是'rb'模式
with open('pickle_demo','wb') as f:
pickle.dump(alex,f)
with open('pickle_demo','rb') as f:
wangcai=pickle.load(f)
print(wangcai.name)
with open('pickle_demo','rb') as f:
while True: # 不知道迴圈幾次不能用for 用while
try:
print(pickle.load(f))
except EOFError:
break
import shelve # 不建議使用
# 存值
f=shelve.open("shelve_demo")
f['key']={'k1':(1,2,3),'k2':'v2'}
f.close()
# 取值
f=shelve.open('shelve_demo')
content=f['key']
f.close()
print(content)加密md5 sha1
# hashlib.md5()
# hashlib.sha1()
#md5是一個演算法,32位的字串 ,每個字串是一個十六進位制
# sha1也是一個演算法,40位的字串,每個字元都是一個十六進位制
# 演算法相對複雜 計算速度也慢
md5_obj=hashlib.md5()
md5_obj.update(s.encode('utf-8'))
res=md5_obj.hexdigest()
print(res,len(res),type(res))
# 資料庫 撞庫
# 加鹽
md5_obj=hashlib.md5("加鹽".encode('utf-8'))
md5_obj.update(s.encode('utf-8'))
# 動態加鹽
username=input('username:')
passwd=input('passwd')
md5obj=hashlib.md5(username.encode('utf-8'))
md5obj.update(passwd.encode('utf-8'))
print(md5obj.hexdigest())configparser模組
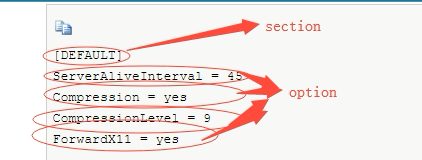
logging 模組
功能
- 日誌格式的規範
- 操作的簡化
- 日誌的分級管理
logging 模組的使用
logging.basicConfig(level=logging.DEBUG) #級別
logging.debug('debug message') #除錯模式
logging.info('info message') # 基礎資訊
logging.warning('warning message')# 警告
logging.error('error message') # 錯誤
logging.critical('critical message') # 嚴重錯誤
basicConfig
不能將一個log資訊既能輸出到螢幕上有輸出到檔案上
# logger 物件的形式來操作日誌檔案
# 建立一個logger物件
logger=logging.getLogger()
# 建立一個檔案管理操作符
fh=logging.FileHandler()
# 建立一個螢幕管理操作符
sh=logging.StreamHandler()
# 建立一個日誌輸出的格式
format1=logging.Formatter('%(asctime)s-%(name)s-%(lecelname))
# 檔案管理操作符 繫結一個格式
sh.setFormatter(format1)
# 螢幕管理操作符 繫結一個格式
# logger物件 繫結 檔案管理操作符
# logger物件 繫結 螢幕管理操作符網路程式設計
由於不同機器上的程式要通訊,才產生了網路
server 服務端
client 客戶端
b/s 架構 ----> 統一入口 (解耦分支)
b/s 和c/s 架構的關係
- b/s架構師c/s架構的一種
閘道器的概念
- 區域網中的機器想要訪問區域網外的機器,需要通過閘道器
- 埠 找到的程式
- 在計算機上,沒一個需要網路通訊的程式,都會開一個埠
- 在同一時間只會有一個程式佔用一個埠
- 不可能在同一時間有兩個程式佔用同一個埠
- 埠的範圍0-65545,一般情況下8000之後的埠
- ip 確定唯一一臺機器
- 埠--- 確定唯一的一個程式
- ip+埠 找到唯一的一臺機器上的唯一的一個程式
tcp協議和udp協議
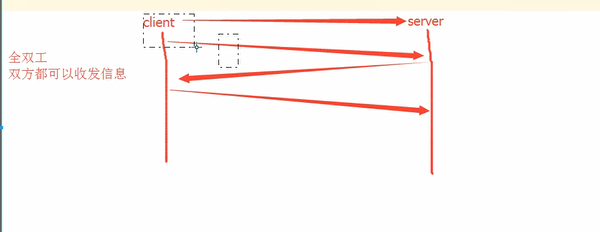
這個全雙工的通訊將佔用兩個計算機之間的通訊線路,直到它被一方或雙方關閉為止
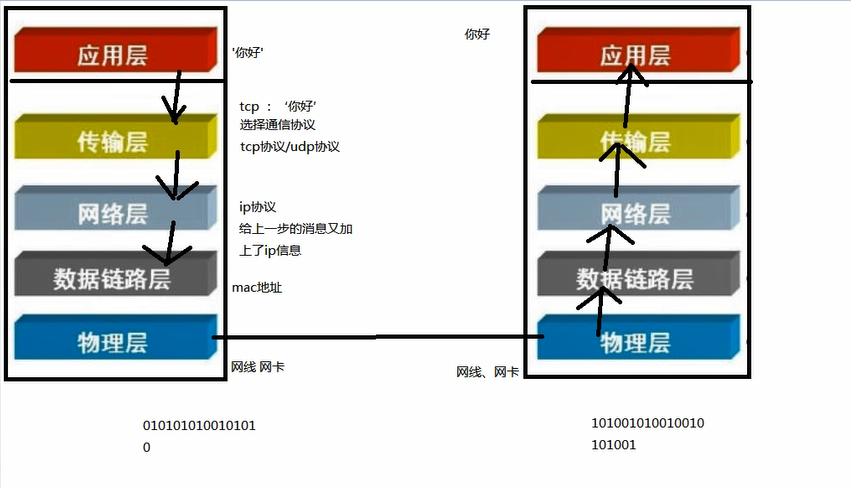
arp地址 通過ip找mac
ip協議屬於網路osi 七層協議中的哪一層,網路層
tcp協議 udp協議屬於傳輸層
arp 協議 屬於資料鏈路層
黏包問題 不知道客戶端傳送的資料的長度
大檔案的傳輸一定要按照位元組讀,每一次讀固定的位元組
> 實現一個大檔案的上傳或者下載---server端
import json
import socket
import struct
sk=socket.socket()
sk.bind(('127.0.0.1',8090))
sk.listen()
buffer=1024
conn,addr=sk.accept()# 接受
head_len=conn.recv(4)
head_len=struct.unpack('i',head_len)[0]
json_head=conn.recv(head_len).decode('utf-8')
head=json.loads(json_head)
filesize=head['filesize']
with open(head['filename'],'wb') as f:
while filesize:
if filesize>=buffer:
content=conn.recv(buffer)
f.write(content)
filesize-=buffer
else:
content=conn.recv(filesize)
f.write(content)
filesize=0
break
conn.close()
sk.close()client端
import json
import socket
import os
import struct
buffer = 1024
sk = socket.socket()
sk.connect(('127.0.0.1', 8090))
head = {# 傳送檔案
'filepath': r'檔案路徑',
'filename': r'檔名',
'filesize': None
}
file_path = os.path.join(head['filepath'], head['filename'])
filesize = os.path.getsize(file_path)
head['filesize'] = filesize
json_head = json.dumps(head) # 字典轉成字串
bytes_head = json_head.encode('utf-8') # 字串轉成bytes
print(json_head)
print(bytes_head)
head_len = len(bytes_head)# 計算head長度
pack_len = struct.pack('i', head_len)
sk.send(pack_len) # 先發報頭的長度
sk.send(bytes_head)
with open(file_path, 'rb') as f:
while filesize:
if filesize > buffer:
content = f.read(buffer) # 每次讀出來的內鵝絨
sk.send(content)
filesize -= buffer
else:
content = f.read(filesize)
f.read(content)
break
# 解決黏包問題
# 為什麼會會出現黏包現象
# 首先 只有在TCP協議中才會出現黏包現象
# 是因為TCP協議是面向流的協議
# 在傳送的資料傳輸的過程中還有快取機制避免資料丟失
# 因此在連續傳送小資料的時候,以及接受大小不符的時候都容易出現黏包現象
# 本質還是因為我們在接受資料的時候不知道傳送的資料的長短
# 解決黏包問題
# 在傳輸大量資料之前先告訴接受端要傳送的資料大小
# 如果想更漂亮的解決問題,可以通過struct模組來定製協議
# struct 模組
# pack unpack
# 模式: 'i'
# pack之後的長度: 4個位元組
#unpack之後拿到的資料是一個元組:元組的第一個元素才是pack的值```