
11.19分類與監督
阿新 • • 發佈:2018-11-19
1.理解分類與監督學習、聚類與無監督學習。
簡述分類與聚類的聯絡與區別。
分類指監督學習,就是按照某種標準給物件貼標籤,再根據標籤來區分歸類。
聚類是指事先沒有“標籤”而通過某種成團分析找出事物之間存在聚集性原因的過程。指無監督學習,是指根據“物以類聚”的原理,將本身沒有類別的樣本聚整合不同的組,這樣的一組資料物件的集合叫做簇,並且對每一個這樣的簇進行描述的過程。
區別是,分類是事先定義好類別 ,聚類則沒有事先預定的類別。
簡述什麼是監督學習與無監督學習。
監督學習指通過已有的訓練樣本來訓練,從而得到一個最優模型,再利用這個模型將所有新的資料樣本對映為相應的輸出結果,對輸出結果進行簡單的判斷從而實現分類的目的,那麼這個最優模型也就具有了對未知資料進行分類的能力。
無監督學習則是在我們事先沒有任何訓練樣本,需要直接對資料進行建模。我們只知道一些特徵,並不知道答案,但不同例項具有一定的相似性,然後把那些相似的聚集在一起
2.樸素貝葉斯分類演算法 例項
利用關於心臟情患者的臨床資料集,建立樸素貝葉斯分類模型。
有六個分類變數(分類因子):性別,年齡、KILLP評分、飲酒、吸菸、住院天數
目標分類變數疾病:–心梗–不穩定性心絞痛
新的例項:–(性別=‘男’,年齡<70, KILLP=‘I',飲酒=‘是’,吸菸≈‘是”,住院天數<7)
最可能是哪個疾病?
上傳演算過程。
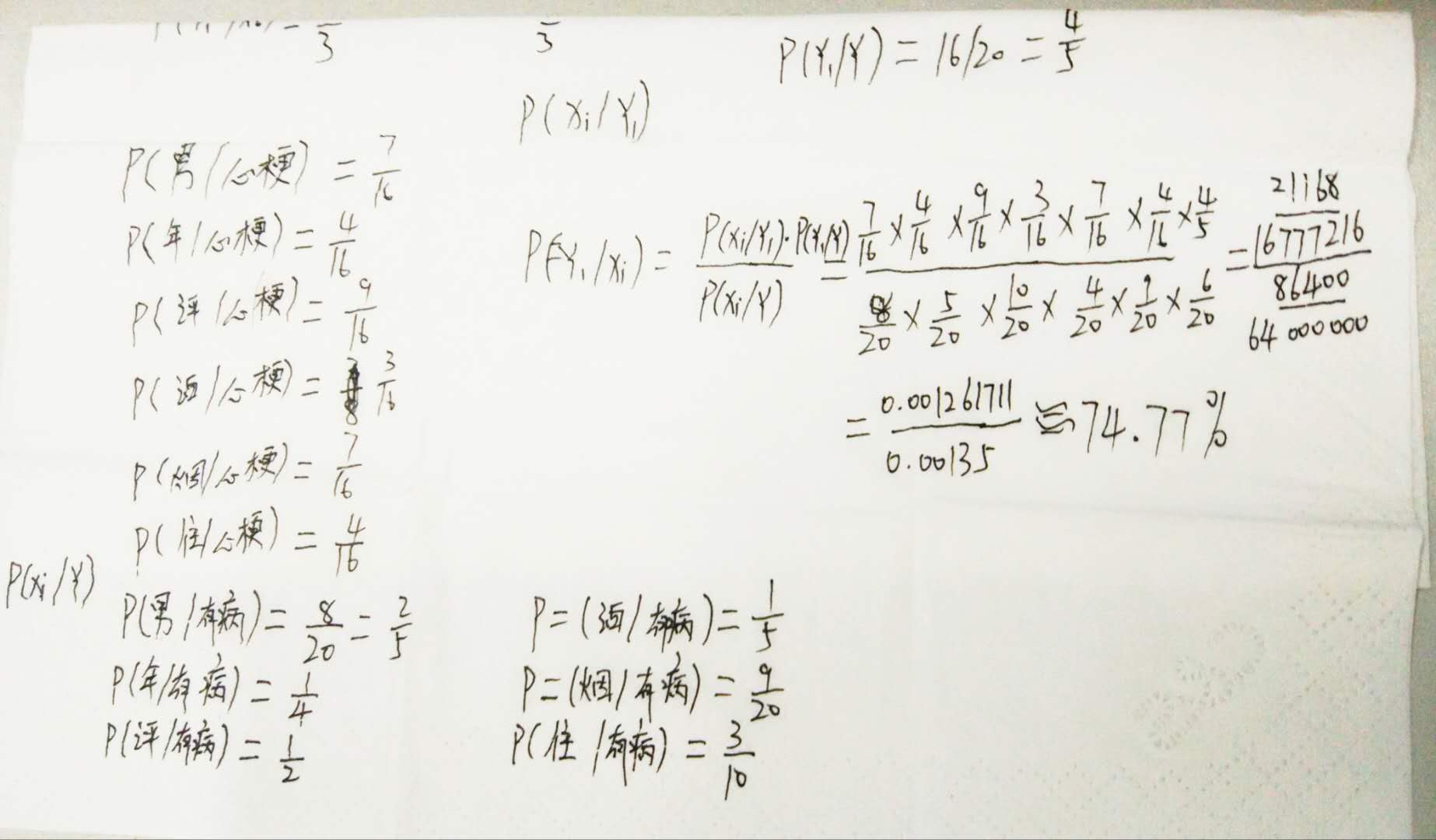
所以最可能得心梗。
3.程式設計實現樸素貝葉斯分類演算法
利用訓練資料集,建立分類模型。
輸入待分類項,輸出分類結果。
可以心臟情患者的臨床資料為例,但要對資料預處理。
from sklearn.datasets import load_iris iris = load_iris() print(iris.keys()) from sklearn.cluster import KMeans est = KMeans(n_clusters=4)#聚成四類 est.fit(iris.data)#計算 print(est.labels_)#聚類結果 print(iris.target) from sklearn.naive_bayes import GaussianNB gnb = GaussianNB()#建立模型 gnb.fit(iris.data,iris.target)#訓練 print(gnb.predict([iris.data[100]]))#預測結果 print(gnb.predict([[4.8,1.2,3.8,1.4]]))
