nginx--upstream
upstream模組
upstream模組 (100%)
nginx模組一般被分成三大類:handler、filter和upstream。前面的章節中,讀者已經瞭解了handler、filter。利用這兩類模組,可以使nginx輕鬆完成任何單機工作。而本章介紹的upstream,將使nginx將跨越單機的限制,完成網路資料的接收、處理和轉發。
資料轉發功能,為nginx提供了跨越單機的橫向處理能力,使nginx擺脫只能為終端節點提供單一功能的限制,而使它具備了網路應用級別的拆分、封裝和整合的戰略功能。在雲模型大行其道的今天,資料轉發使nginx有能力構建一個網路應用的關鍵元件。當然,一個網路應用的關鍵元件往往一開始都會考慮通過高階開發語言編寫,因為開發比較方便,但系統到達一定規模,需要更重視效能的時候,這些高階語言為了達成目標所做的結構化修改所付出的代價會使nginx的upstream模組就呈現出極大的吸引力,因為他天生就快。作為附帶,nginx的配置提供的層次化和鬆耦合使得系統的擴充套件性也可能達到比較高的程度。
言歸正傳,下面介紹upstream的寫法。
upstream模組介面
從本質上說,upstream屬於handler,只是他不產生自己的內容,而是通過請求後端伺服器得到內容,所以才稱為upstream(上游)。請求並取得響應內容的整個過程已經被封裝到nginx內部,所以upstream模組只需要開發若干回撥函式,完成構造請求和解析響應等具體的工作。
這些回撥函式如下表所示:
| create_request | 生成傳送到後端伺服器的請求緩衝(緩衝鏈)。 |
| reinit_request | 在某臺後端伺服器出錯的情況,nginx會嘗試另一臺後端伺服器。 nginx選定新的伺服器以後,會先呼叫此函式,然後再次呼叫 create_request,以重新初始化upstream模組的工作狀態。 |
| process_header | 處理後端伺服器返回的資訊頭部。所謂頭部是與upstream server 通訊的協議規定的,比如HTTP協議的header部分,或者memcached 協議的響應狀態部分。 |
| abort_request | 在客戶端放棄請求時被呼叫。不需要在函式中實現關閉後端服務 器連線的功能,系統會自動完成關閉連線的步驟,所以一般此函 數不會進行任何具體工作。 |
| finalize_request | 正常完成與後端伺服器的請求後呼叫該函式,與abort_request 相同,一般也不會進行任何具體工作。 |
| input_filter | 處理後端伺服器返回的響應正文。nginx預設的input_filter會 將收到的內容封裝成為緩衝區鏈ngx_chain。該鏈由upstream的 out_bufs指標域定位,所以開發人員可以在模組以外通過該指標 得到後端伺服器返回的正文資料。memcached模組實現了自己的 input_filter,在後面會具體分析這個模組。 |
| input_filter_init | 初始化input filter的上下文。nginx預設的input_filter_init 直接返回。 |
memcached模組分析
memcache是一款高效能的分散式cache系統,得到了非常廣泛的應用。memcache定義了一套私有通訊協議,使得不能通過HTTP請求來訪問memcache。但協議本身簡單高效,而且memcache使用廣泛,所以大部分現代開發語言和平臺都提供了memcache支援,方便開發者使用memcache。
nginx提供了ngx_http_memcached模組,提供從memcache讀取資料的功能,而不提供向memcache寫資料的功能。作為web伺服器,這種設計是可以接受的。
下面,我們開始分析ngx_http_memcached模組,一窺upstream的奧祕。
Handler模組?
初看memcached模組,大家可能覺得並無特別之處。如果稍微細看,甚至覺得有點像handler模組,當大家看到這段程式碼以後,必定疑惑為什麼會跟handler模組一模一樣。
clcf = ngx_http_conf_get_module_loc_conf(cf, ngx_http_core_module); clcf->handler = ngx_http_memcached_handler;
因為upstream模組使用的就是handler模組的接入方式。同時,upstream模組的指令系統的設計也是遵循handler模組的基本規則:配置該模組才會執行該模組。
{ ngx_string("memcached_pass"),
NGX_HTTP_LOC_CONF|NGX_HTTP_LIF_CONF|NGX_CONF_TAKE1,
ngx_http_memcached_pass,
NGX_HTTP_LOC_CONF_OFFSET,
0,
NULL }
所以大家覺得眼熟是好事,說明大家對Handler的寫法已經很熟悉了。
Upstream模組!
那麼,upstream模組的特別之處究竟在哪裡呢?答案是就在模組處理函式的實現中。upstream模組的處理函式進行的操作都包含一個固定的流程。在memcached的例子中,可以觀察ngx_http_memcached_handler的程式碼,可以發現,這個固定的操作流程是:
1. 建立upstream資料結構。
if (ngx_http_upstream_create(r) != NGX_OK) {
return NGX_HTTP_INTERNAL_SERVER_ERROR;
}
2. 設定模組的tag和schema。schema現在只會用於日誌,tag會用於buf_chain管理。
u = r->upstream; ngx_str_set(&u->schema, "memcached://"); u->output.tag = (ngx_buf_tag_t) &ngx_http_memcached_module;
3. 設定upstream的後端伺服器列表資料結構。
mlcf = ngx_http_get_module_loc_conf(r, ngx_http_memcached_module); u->conf = &mlcf->upstream;
4. 設定upstream回撥函式。在這裡列出的程式碼稍稍調整了程式碼順序。
u->create_request = ngx_http_memcached_create_request; u->reinit_request = ngx_http_memcached_reinit_request; u->process_header = ngx_http_memcached_process_header; u->abort_request = ngx_http_memcached_abort_request; u->finalize_request = ngx_http_memcached_finalize_request; u->input_filter_init = ngx_http_memcached_filter_init; u->input_filter = ngx_http_memcached_filter;
5. 建立並設定upstream環境資料結構。
ctx = ngx_palloc(r->pool, sizeof(ngx_http_memcached_ctx_t));
if (ctx == NULL) {
return NGX_HTTP_INTERNAL_SERVER_ERROR;
}
ctx->rest = NGX_HTTP_MEMCACHED_END;
ctx->request = r;
ngx_http_set_ctx(r, ctx, ngx_http_memcached_module);
u->input_filter_ctx = ctx;
6. 完成upstream初始化並進行收尾工作。
r->main->count++; ngx_http_upstream_init(r); return NGX_DONE;
任何upstream模組,簡單如memcached,複雜如proxy、fastcgi都是如此。不同的upstream模組在這6步中的最大差別會出現在第2、3、4、5上。其中第2、4兩步很容易理解,不同的模組設定的標誌和使用的回撥函式肯定不同。第5步也不難理解,只有第3步是最為晦澀的,不同的模組在取得後端伺服器列表時,策略的差異非常大,有如memcached這樣簡單明瞭的,也有如proxy那樣邏輯複雜的。這個問題先記下來,等把memcached剖析清楚了,再單獨討論。
第6步是一個常態。將count加1,然後返回NGX_DONE。nginx遇到這種情況,雖然會認為當前請求的處理已經結束,但是不會釋放請求使用的記憶體資源,也不會關閉與客戶端的連線。之所以需要這樣,是因為nginx建立了upstream請求和客戶端請求之間一對一的關係,在後續使用ngx_event_pipe將upstream響應傳送回客戶端時,還要使用到這些儲存著客戶端資訊的資料結構。這部分會在後面的原理篇做具體介紹,這裡不再展開。
將upstream請求和客戶端請求進行一對一繫結,這個設計有優勢也有缺陷。優勢就是簡化模組開發,可以將精力集中在模組邏輯上,而缺陷同樣明顯,一對一的設計很多時候都不能滿足複雜邏輯的需要。對於這一點,將會在後面的原理篇來闡述。
回撥函式
前面剖析了memcached模組的骨架,現在開始逐個解決每個回撥函式。
1. ngx_http_memcached_create_request:很簡單的按照設定的內容生成一個key,接著生成一個“get $key”的請求,放在r->upstream->request_bufs裡面。
2. ngx_http_memcached_reinit_request:無需初始化。
3. ngx_http_memcached_abort_request:無需額外操作。
4. ngx_http_memcached_finalize_request:無需額外操作。
5. ngx_http_memcached_process_header:模組的業務重點函式。memcache協議將頭部資訊被定義為第一行文字,可以找到這段程式碼證明:
for (p = u->buffer.pos; p < u->buffer.last; p++) {
if ( * p == LF) {
goto found;
}
如果在已讀入緩衝的資料中沒有發現LF(‘n’)字元,函式返回NGX_AGAIN,表示頭部未完全讀入,需要繼續讀取資料。nginx在收到新的資料以後會再次呼叫該函式。
nginx處理後端伺服器的響應頭時只會使用一塊快取,所有資料都在這塊快取中,所以解析頭部資訊時不需要考慮頭部資訊跨越多塊快取的情況。而如果頭部過大,不能儲存在這塊快取中,nginx會返回錯誤資訊給客戶端,並記錄error log,提示快取不夠大。
process_header的重要職責是將後端伺服器返回的狀態翻譯成返回給客戶端的狀態。例如,在ngx_http_memcached_process_header中,有這樣幾段程式碼:
r->headers_out.content_length_n = ngx_atoof(len, p - len - 1); u->headers_in.status_n = 200; u->state->status = 200; u->headers_in.status_n = 404; u->state->status = 404;
u->state用於計算upstream相關的變數。比如u->status->status將被用於計算變數“upstream_status”的值。u->headers_in將被作為返回給客戶端的響應返回狀態碼。而第一行則是設定返回給客戶端的響應的長度。
在這個函式中不能忘記的一件事情是處理完頭部資訊以後需要將讀指標pos後移,否則這段資料也將被複制到返回給客戶端的響應的正文中,進而導致正文內容不正確。
u->buffer.pos = p + 1;
process_header函式完成響應頭的正確處理,應該返回NGX_OK。如果返回NGX_AGAIN,表示未讀取完整資料,需要從後端伺服器繼續讀取資料。返回NGX_DECLINED無意義,其他任何返回值都被認為是出錯狀態,nginx將結束upstream請求並返回錯誤資訊。
6. ngx_http_memcached_filter_init:修正從後端伺服器收到的內容長度。因為在處理header時沒有加上這部分長度。
7. ngx_http_memcached_filter:memcached模組是少有的帶有處理正文的回撥函式的模組。因為memcached模組需要過濾正文末尾CRLF “END” CRLF,所以實現了自己的filter回撥函式。處理正文的實際意義是將從後端伺服器收到的正文有效內容封裝成ngx_chain_t,並加在u->out_bufs末尾。nginx並不進行資料拷貝,而是建立ngx_buf_t資料結構指向這些資料記憶體區,然後由ngx_chain_t組織這些buf。這種實現避免了記憶體大量搬遷,也是nginx高效的奧祕之一。
負載均衡模組 (100%)
負載均衡模組用於從”upstream”指令定義的後端主機列表中選取一臺主機。nginx先使用負載均衡模組找到一臺主機,再使用upstream模組實現與這臺主機的互動。為了方便介紹負載均衡模組,做到言之有物,以下選取nginx內建的ip hash模組作為實際例子進行分析。
配置
要了解負載均衡模組的開發方法,首先需要了解負載均衡模組的使用方法。因為負載均衡模組與之前書中提到的模組差別比較大,所以我們從配置入手比較容易理解。
在配置檔案中,我們如果需要使用ip hash的負載均衡演算法。我們需要寫一個類似下面的配置:
upstream test {
ip_hash;
server 192.168.0.1;
server 192.168.0.2;
}
從配置我們可以看出負載均衡模組的使用場景: 1. 核心指令”ip_hash”只能在upstream {}中使用。這條指令用於通知nginx使用ip hash負載均衡演算法。如果沒加這條指令,nginx會使用預設的round robin負載均衡模組。請各位讀者對比handler模組的配置,是不是有共同點? 2. upstream {}中的指令可能出現在”server”指令前,可能出現在”server”指令後,也可能出現在兩條”server”指令之間。各位讀者可能會有疑問,有什麼差別麼?那麼請各位讀者嘗試下面這個配置:
upstream test {
server 192.168.0.1 weight=5;
ip_hash;
server 192.168.0.2 weight=7;
}
神奇的事情出現了:
nginx: [emerg] invalid parameter "weight=7" in nginx.conf:103 configuration file nginx.conf test failed
可見ip_hash指令的確能影響到配置的解析。
指令
配置決定指令系統,現在就來看ip_hash的指令定義:
static ngx_command_t ngx_http_upstream_ip_hash_commands[] = {
{ ngx_string("ip_hash"),
NGX_HTTP_UPS_CONF|NGX_CONF_NOARGS,
ngx_http_upstream_ip_hash,
0,
0,
NULL },
ngx_null_command
};
沒有特別的東西,除了指令屬性是NGX_HTTP_UPS_CONF。這個屬性表示該指令的適用範圍是upstream{}。
鉤子
以從前面的章節得到的經驗,大家應該知道這裡就是模組的切入點了。負載均衡模組的鉤子程式碼都是有規律的,這裡通過ip_hash模組來分析這個規律。
static char *
ngx_http_upstream_ip_hash(ngx_conf_t *cf, ngx_command_t *cmd, void *conf)
{
ngx_http_upstream_srv_conf_t *uscf;
uscf = ngx_http_conf_get_module_srv_conf(cf, ngx_http_upstream_module);
uscf->peer.init_upstream = ngx_http_upstream_init_ip_hash;
uscf->flags = NGX_HTTP_UPSTREAM_CREATE
|NGX_HTTP_UPSTREAM_MAX_FAILS
|NGX_HTTP_UPSTREAM_FAIL_TIMEOUT
|NGX_HTTP_UPSTREAM_DOWN;
return NGX_CONF_OK;
}
這段程式碼中有兩點值得我們注意。一個是uscf->flags的設定,另一個是設定init_upstream回撥。
設定uscf->flags
- NGX_HTTP_UPSTREAM_CREATE:建立標誌,如果含有建立標誌的話,nginx會檢查重複建立,以及必要引數是否填寫;
- NGX_HTTP_UPSTREAM_MAX_FAILS:可以在server中使用max_fails屬性;
- NGX_HTTP_UPSTREAM_FAIL_TIMEOUT:可以在server中使用fail_timeout屬性;
- NGX_HTTP_UPSTREAM_DOWN:可以在server中使用down屬性;
此外還有下面屬性:
- NGX_HTTP_UPSTREAM_WEIGHT:可以在server中使用weight屬性;
- NGX_HTTP_UPSTREAM_BACKUP:可以在server中使用backup屬性。
聰明的讀者如果聯想到剛剛遇到的那個神奇的配置錯誤,可以得出一個結論:在負載均衡模組的指令處理函式中可以設定並修改upstream{}中”server”指令支援的屬性。這是一個很重要的性質,因為不同的負載均衡模組對各種屬性的支援情況都是不一樣的,那麼就需要在解析配置檔案的時候檢測出是否使用了不支援的負載均衡屬性並給出錯誤提示,這對於提升系統維護性是很有意義的。但是,這種機制也存在缺陷,正如前面的例子所示,沒有機制能夠追加檢查在更新支援屬性之前已經配置了不支援屬性的”server”指令。
設定init_upstream回撥
nginx初始化upstream時,會在ngx_http_upstream_init_main_conf函式中呼叫設定的回撥函式初始化負載均衡模組。這裡不太好理解的是uscf的具體位置。通過下面的示意圖,說明upstream負載均衡模組的配置的記憶體佈局。
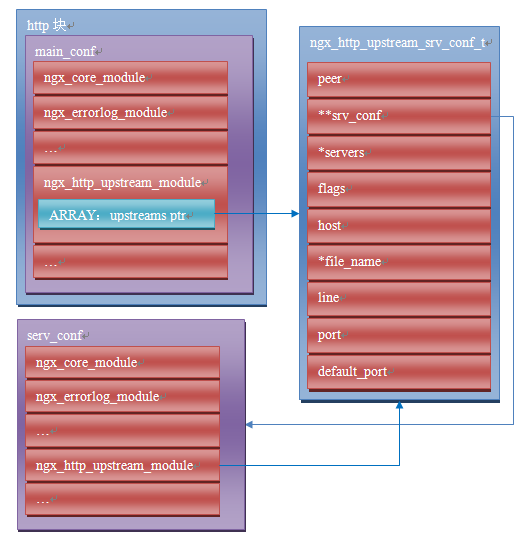
從圖上可以看出,MAIN_CONF中ngx_upstream_module模組的配置項中有一個指標陣列upstreams,陣列中的每個元素對應就是配置檔案中每一個upstream{}的資訊。更具體的將會在後面的原理篇討論。
初始化配置
init_upstream回撥函式執行時需要初始化負載均衡模組的配置,還要設定一個新鉤子,這個鉤子函式會在nginx處理每個請求時作為初始化函式呼叫,關於這個新鉤子函式的功能,後面會有詳細的描述。這裡,我們先分析IP hash模組初始化配置的程式碼:
ngx_http_upstream_init_round_robin(cf, us); us->peer.init = ngx_http_upstream_init_ip_hash_peer;
這段程式碼非常簡單:IP hash模組首先呼叫另一個負載均衡模組Round Robin的初始化函式,然後再設定自己的處理請求階段初始化鉤子。實際上幾個負載均衡模組可以組成一條連結串列,每次都是從鏈首的模組開始進行處理。如果模組決定不處理,可以將處理權交給連結串列中的下一個模組。這裡,IP hash模組指定Round Robin模組作為自己的後繼負載均衡模組,所以在自己的初始化配置函式中也對Round Robin模組進行初始化。
初始化請求
nginx收到一個請求以後,如果發現需要訪問upstream,就會執行對應的peer.init函式。這是在初始化配置時設定的回撥函式。這個函式最重要的作用是構造一張表,當前請求可以使用的upstream伺服器被依次新增到這張表中。之所以需要這張表,最重要的原因是如果upstream伺服器出現異常,不能提供服務時,可以從這張表中取得其他伺服器進行重試操作。此外,這張表也可以用於負載均衡的計算。之所以構造這張表的行為放在這裡而不是在前面初始化配置的階段,是因為upstream需要為每一個請求提供獨立隔離的環境。
為了討論peer.init的核心,我們還是看IP hash模組的實現:
r->upstream->peer.data = &iphp->rrp; ngx_http_upstream_init_round_robin_peer(r, us); r->upstream->peer.get = ngx_http_upstream_get_ip_hash_peer;
第一行是設定資料指標,這個指標就是指向前面提到的那張表;
第二行是呼叫Round Robin模組的回撥函式對該模組進行請求初始化。面前已經提到,一個負載均衡模組可以呼叫其他負載均衡模組以提供功能的補充。
第三行是設定一個新的回撥函式get。該函式負責從表中取出某個伺服器。除了get回撥函式,還有另一個r->upstream->peer.free的回撥函式。該函式在upstream請求完成後呼叫,負責做一些善後工作。比如我們需要維護一個upstream伺服器訪問計數器,那麼可以在get函式中對其加1,在free中對其減1。如果是SSL的話,nginx還提供兩個回撥函式peer.set_session和peer.save_session。一般來說,有兩個切入點實現負載均衡演算法,其一是在這裡,其二是在get回撥函式中。
peer.get和peer.free回撥函式
這兩個函式是負載均衡模組最底層的函式,負責實際獲取一個連線和回收一個連線的預備操作。之所以說是預備操作,是因為在這兩個函式中,並不實際進行建立連線或者釋放連線的動作,而只是執行獲取連線的地址或維護連線狀態的操作。需要理解的清楚一點,在peer.get函式中獲取連線的地址資訊,並不代表這時連線一定沒有被建立,相反的,通過get函式的返回值,nginx可以瞭解是否存在可用連線,連線是否已經建立。這些返回值總結如下:
| 返回值 | 說明 | nginx後續動作 |
| NGX_DONE | 得到了連線地址資訊,並且連線已經建立。 | 直接使用連線,傳送資料。 |
| NGX_OK | 得到了連線地址資訊,但連線並未建立。 | 建立連線,如連線不能立即建立,設定事件, 暫停執行本請求,執行別的請求。 |
| NGX_BUSY | 所有連線均不可用。 | 返回502錯誤至客戶端。 |
各位讀者看到上面這張表,可能會有幾個問題浮現出來:
| Q: | 什麼時候連線是已經建立的? |
|---|---|
| A: | 使用後端keepalive連線的時候,連線在使用完以後並不關閉,而是存放在一個佇列中,新的請求只需要從佇列中取出連線,這些連線都是已經準備好的。 |
| Q: | 什麼叫所有連線均不可用? |
| A: | 初始化請求的過程中,建立了一張表,get函式負責每次從這張表中不重複的取出一個連線,當無法從表中取得一個新的連線時,即所有連線均不可用。 |
| Q: | 對於一個請求,peer.get函式可能被呼叫多次麼? |
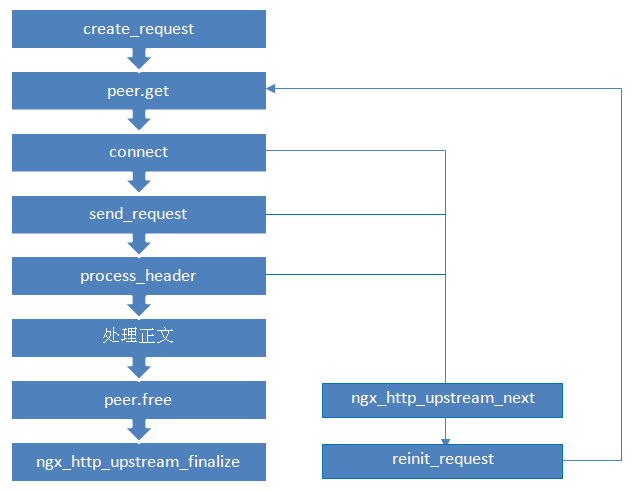
| A: | 正式如此。當某次peer.get函式得到的連線地址連線不上,或者請求對應的伺服器得到異常響應,nginx會執行ngx_http_upstream_next,然後可能再次呼叫peer.get函式嘗試別的連線。upstream整體流程如下: |