
編譯原理 第三章 詞法分析(上)
3.1.1 為什麼編譯器要把詞法分析和語法分析分開

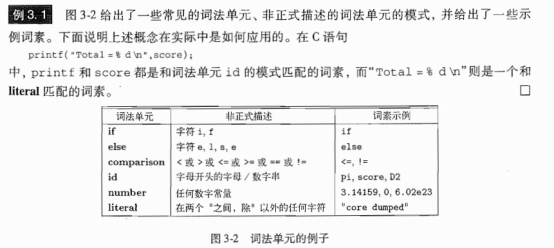
3.1.2 詞法單元、模式和詞素(重要)

例:

3.1.3 詞法單元的屬性(重要)

詞法單元的屬性是用來記錄相對應的詞素的一些相關屬性資訊。
例:
int x = 10 + 20;
這裡的 10 和 20 都是number的詞法單元。但是他們具有不同的詞素, 一個是10一個是20。在程式碼生成的階段需要使用到具體的數值,所以詞法單元的屬性需要儲存他們具體的值。
3.2.1 緩衝區對

3.2.2 哨兵標記
在每個緩衝區塊的最末尾新增一個
新增這個標記的目的是方便我們識別緩衝區結尾。如果沒有這個標記,我們在處理每一個字元的時候都需要去判斷一下是否到達了緩衝區某位。如果有一個標記我們就可以把這個標記也當做一個特殊的字元去處理。

綜合 3.2.1 和 3.2.2演算法舉個例子
下面的例子是一個C語言的函式,我們要對下面的程式進行詞法分析。
... 代表其他語句
main()
{
...
...
var_1 = var_2 + 10;
...
...
}
我們預設有兩個緩衝區
緩衝區A的內容
| m |
a |
i |
n |
( |
) |
{ |
. |
. |
. |
v |
a |
r |
_ |
1 |
= |
v |
a |
eof |
var_1 = var_2 + 10;其中有兩個識別符號 一個是 var_1, 一個是 var_2。
分析 var_1的時候lexemeBegin指向v, forward指標不斷的前移。
當forward 指向一個字元會去判斷這個字元是否符合這個詞法單元的模式,如果不符合那麼從lexemeBegin到foreward之間的詞素就可以提取出來當做一個詞素。
var_1我們當成識別符號去處理的時候,遇到=字元的時候,我們就會提取出var_1因為’=’不符合識別符號的模式。

分析 var_2的時候lexemeBegin指向v, forward指標不斷前移。
但是A緩衝區的內容只讀取到了var_2的va部分就到達了緩衝區的結束了。這時我們就要用緩衝區B來載入剩餘的檔案內容, 並且把forward指標指向緩衝區B的開頭。然後繼續之前的動作,forward指標一直前移直到遇到不匹配這個模式的字元位置。當遇到緩衝區B的eof的時候。我們就繼續載入檔案剩餘的內容到緩衝區A中。除非詞素的長度大於緩衝區的內容才有可能出問題。

3.4.1 狀態流轉圖(重要)

紅線部分表達的意思是:
從A狀態到B狀態經過標號為S的邊,這個標號為S的邊可以包含多個符號。
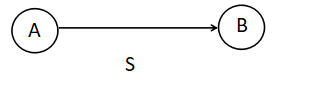
例如: [a-z]+([0-9]+|[A-Z+]) 這個正則表示式 小寫字母a-z的輸入在狀態A,當遇到大寫字母A-Z或者數字0-9的時候都經過S的邊到達狀態B。
3.4.2 區分識別符號和關鍵字

例子:3.10 如何識別多個詞法單元 (非常重要)
