
CSRF漏洞原理說明與利用方法
翻譯者:Fireweed
原文連結:http://seclab.stanford.edu/websec/
一 、什麼是CSRF
Cross-Site Request Forgery(CSRF),中文一般譯作跨站請求偽造。經常入選owasp漏洞列表Top10,在當前web漏洞排行中,與XSS和SQL注入並列前三。與前兩者相比,CSRF相對來說受到的關注要小很多,但是危害卻非常大。
通常情況下,有三種方法被廣泛用來防禦CSRF攻擊:驗證token,驗證HTTP請求的Referer,還有驗證XMLHttpRequests裡的自定義header。鑑於種種原因,這三種方法都不是那麼完美,各有利弊。
二、 CSRF的分類
在跨站請求偽造(CSRF)攻擊裡面,攻擊者通過使用者的瀏覽器來注入額外的網路請求,來破壞一個網站會話的完整性。而瀏覽器的安全策略是允許當前頁面傳送到任何地址的請求,因此也就意味著當用戶在瀏覽他/她無法控制的資源時,攻擊者可以控制頁面的內容來控制瀏覽器傳送它精心構造的請求。
1、網路連線。例如,如果攻擊者無法直接訪問防火牆內的資源,他可以利用防火牆內使用者的瀏覽器間接的對他所想訪問的資源傳送網路請求。甚至還有這樣一種情況,攻擊者為了繞過基於IP地址的驗證策略,利用受害者的IP地址來發起他想發起的請求。
2、獲知瀏覽器的狀態。當瀏覽器傳送請求時,通常情況下,網路協議裡包含了瀏覽器的狀態。這其中包括很多,比如cookie,客戶端證書或基於身份驗證的header。因此,當攻擊者藉助瀏覽器向需要上述這些cookie,證書和header等作驗證的站點發送請求的時候,站點則無法區分真實使用者和攻擊者。
3、改變瀏覽器的狀態。當攻擊者藉助瀏覽器發起一個請求的時候,瀏覽器也會分析並相應服務端的response。舉個例子,如果服務端的response裡包含有一個Set-Cookie的header,瀏覽器會相應這個Set-Cookie,並修改儲存在本地的cookie。這些改動都會導致很微妙的攻擊,我們將在第三部分描述。
作用範圍內的威脅:我們按照產生危害的大小將此部分分成三種不同的危害模型。
1、論壇可互動的地方。很多網站,比如論壇允許使用者自定義有限種類的內容。舉例來說,通常情況下,網站允許使用者提交一些被動的如影象或連結等內容。如果攻擊者讓影象的url指向一個惡意的地址,那麼本次網路請求很有可能導致CSRF攻擊。這些地方都可以發起請求,但這些請求不能自定義HTTP header,而且必須使用GET方法。儘管HTTP協議規範要求請求不能帶有危害,但是很多網站並不符合這一要求。
2、Web攻擊者。在這裡web攻擊者的定義是指有自己的獨立域名的惡意代理,比如attacker.com,並且擁有attacker.com的HTTPS證書和web伺服器。所有的這些功能只需要花10美元即可以做到。一旦使用者訪問attacker.com,攻擊者就可以同時用GET和POST方法發起跨站請求,即為CSRF攻擊。
3、網路攻擊者。這裡的網路攻擊者指的是能控制使用者網路連線的惡意代理。比如,攻擊者可以通過控制無線路由器或者DNS伺服器來控制使用者的網路連線。這種攻擊比web攻擊需要更多的資源和準備,但我們認為這對HTTPS站點也有威脅。因為HTTPS站點只能防護有源網路。
作用範圍外的威脅:下面我們還列出了一些不在本論文討論範圍的相關危害模型。對這些危害的防禦措施可以與CSRF的防禦措施形成很好的互補。
1、跨站指令碼(XSS)。如果攻擊者能夠向網站注入指令碼,那麼攻擊者就會破壞該網站使用者會話的完整性和保密性。有些XSS攻擊需要發起網路請求,比如將使用者銀行賬戶裡的錢轉移到攻擊者的賬戶裡,但是通常情況下,對CSRF的防禦並沒有考慮到這些情況。考慮到更安全的做法,網站必須實現對XSS和CSRF的同時防禦。
2、惡意軟體。如果攻擊者能夠在使用者的電腦上執行惡意軟體,那麼攻擊者就可以控制使用者的瀏覽器向那些可信的網站注入指令碼。這時候基於瀏覽器的防禦策略將會失效,因為攻擊者可以用含有惡意外掛的瀏覽器來替換使用者的瀏覽器。
3、DNS的重新繫結。像CSRF一樣,DNS重新繫結可以使用使用者的IP地址來連線攻擊者指定的伺服器。處在防火牆保護內的伺服器或者那些基於IP地址驗證的伺服器需要一個對抗DNS重新繫結的防禦方案。儘管DNS重新繫結的攻擊和CSRF攻擊的意圖非常相似,但是他們還是需要各自不同的解決方案。一個簡單的解決DNS重新繫結攻擊的方案就是要驗證主機的HTTP請求header,確保包含有預期值。還有一個替代方案就是過濾DNS流量,防止將外部的DNS名稱解析成內部私有地址。
4、證書錯誤。如果使用者在出現HTTPS證書錯誤的時候還願意繼續點選訪問,那麼HTTPS能夠提供的很多安全保護就沒有意義。有一些安全研究者指出了針對這一種情況的威害,但是在本文中,我們假設使用者不會在出現了HTTPS證書錯誤之後繼續點選訪問。
5、釣魚。當用戶在訪問釣魚網站的時候,在身份驗證的時候輸入個人資訊,釣魚攻擊就發生了。釣魚攻擊現今非常普遍也很有效,因為使用者有的時候真的很難區分釣魚網站和真正的網站。
6、使用者跟蹤。一些合作網站會利用跨站請求來對使用者的瀏覽習慣建立一個關聯行為庫。大多數瀏覽器都通過組織第三方cookie傳送來阻止類似的跟蹤,但是利用掛站請求,瀏覽器的這一特性可以被繞過。
三 、登入CSRF
無論是利用瀏覽器的網路連線還是利用瀏覽器的狀態,大多數對CSRF的討論都集中在能改變服務端狀態的請求上面。儘管CSRF攻擊能通過改變瀏覽器的狀態來對使用者在訪問可信網站時候造成危害,但是對它的重視程度還是不夠。再登陸CSRF攻擊裡面,攻擊者利用使用者在可信網站的使用者名稱和密碼來對網站發起一個偽造請求。一旦請求成功,伺服器端就會響應一個Set-Cookie的header,瀏覽器接收到以後就會建立一個session cookie,並記錄使用者的登陸狀態。這個session cookie被用作繫結後續的請求,因而也可被攻擊者用來作為身份驗證。依據不同的網站,登陸CSRF攻擊還可以造成很嚴重的後果。
搜尋記錄:包括谷歌和雅虎等很多搜尋引擎允許他們的使用者選擇是否同意儲存他們的搜尋記錄,並且為使用者提供一個介面來檢視他們自己的私人搜尋記錄。搜尋請求裡面包含了使用者的行為習慣和興趣的一些敏感細節,攻擊者可以利用這些細節來欺騙使用者,盜竊使用者的身份或者窺探使用者。當攻擊者以使用者身份登陸到搜尋引擎裡,就可以看到使用者的搜尋記錄。如圖1. 這樣,使用者的搜尋查詢記錄就被儲存到了攻擊者的搜尋記錄裡,攻擊者就可以登陸自己的賬戶隨便查詢使用者的搜尋記錄。

圖1. 登陸CSRF攻擊事件的跟蹤圖。受害人訪問攻擊者的網站,攻擊者向谷歌偽造一個跨站點請求的登陸框,造成受害者被攻擊者登陸到谷歌。隨後,受害者使用搜索的時候,搜尋記錄就被攻擊者記錄下來。
PayPal:PayPal允許它的使用者相互之間任意轉移資金。轉移資金的時候,使用者要註冊信用卡或者銀行賬戶。攻擊者可以利用登陸CSRF來發起以下攻擊:
1、受害者訪問了惡意商家的網站,並選擇使用PayPal支付。
2、受害者被重定向到PayPal並且要求登陸他/她的賬戶。
3、網站等待使用者登陸他/她的PayPal賬戶。
4、付款的時候,受害者先是登記自己的信用卡,但是信用卡實際上已經被新增到惡意商家的PayPal賬戶。
iGoogle:使用者可以通過使用iGoogle來定製自己的谷歌主頁,也包括一些外掛。為了易用性,這些外掛是“嵌入到iGoogle的”,這也就意味著他們將影響到iGoogle的安全。通常情況下,iGoogle在新增新外掛的時候,都會詢問使用者做出信任決定。但是攻擊者可以通過登入CSRF攻擊來幫助使用者做出決定,從而安裝任意的外掛。
1、攻擊者通過使用者的瀏覽器授權安裝一個iGoogle外掛(含有惡意指令碼),並將外掛新增到使用者的定製化iGoogle主頁。
2、攻擊者使使用者登陸谷歌,並開一個到iGoogle的框架。
3、谷歌認為受害者就是攻擊者,並將攻擊者的外掛推送給受害者,而且允許攻擊者在https://www.google.com域下執行指令碼。
4、攻擊者現在可以:(a)在正確的URL頁面構造一個登陸框(b)盜取使用者自動填充的密碼(c)在另一個視窗等待使用者登陸並讀取document.cookie。
我們已經將上述漏洞告知了谷歌,他們已經在兩方面來減緩漏洞帶來的危害。首先,谷歌已經棄用內嵌的外掛並禁止開發者開發類似的外掛,只允許少部分比較受歡迎的內嵌外掛。其次,谷歌已經開發了私密token策略來防禦登陸CSRF(下面將會討論),但是這個策略只對登陸了的使用者才有效。我們預計,谷歌一旦充分測試了他們的防禦方案並覺得有效之後,會否認他們的登陸CSRF漏洞。
四 、現有的CSRF防禦方案
一般網站有三種防禦CSRF攻擊的方案。(1)驗證token值。(2)驗證HTTP頭的Referer。(3)用XMLHttpRequest附加在header裡。以上三種方法都在廣泛使用,但是他們的效果都不是那麼的令人滿意。
4.2 Token驗證
在每個HTTP請求裡附加一部分資訊是一個防禦CSRF攻擊的很好的方法,因為這樣可以判斷請求是否已經授權。這個“驗證token”應該不能輕易的被未登入的使用者猜測出來。如果請求裡面沒有這個驗證token或者token不能匹配的話,伺服器應該拒絕這個請求。
Token驗證的方法可以用來防禦登陸CSRF,但是開發者往往會忘記驗證,因為如果沒有登陸,就不能通過session來繫結CSRF token。網站要想用驗證token的方式來防禦登陸CSRF攻擊的話,就必須先建立一個“前session”,這樣才能部署CSRF的防禦方案,在驗證通過了之後,再建立一個真正的session。
Token的設計。有很多技術可以生成驗證token。
• session識別符號。瀏覽器的cookie儲存方式就是為了防止不同域之間互相訪問cookie。一個普遍的做法是直接利用使用者的session識別符號來作為驗證token。伺服器在處理每一個請求時,都將使用者的token與session識別符號來匹配。如果攻擊者能夠猜測出使用者的token,那麼他就能登入使用者的賬戶。而且這樣做有個不好的地方在於,偶爾使用者正在瀏覽的內容會發送給第三方,比如通過電子郵件直接上網頁內容上傳到瀏覽器廠商的bug跟蹤資料庫。如果正好這個頁面包含有使用者的session識別符號,任何能看到這個頁面的人都能模擬使用者登陸到網站,直到會話過期。
• 獨立session隨機數。與直接使用使用者的session識別符號不一樣的是,當用戶第一次登陸網站的時候,伺服器可以產生一個隨機數並將它儲存在使用者的cookie裡面。對於每一個請求,伺服器都會將token與儲存在cookie裡的值匹配。例如,廣泛使用的Trac問題跟蹤系統就是用的此技術。但是這個方法不能防禦主動的網路攻擊,即使是整個web應用都使用的是HTTPS協議。因為攻擊者可以使用他自己的CSRF token來覆蓋來覆蓋這個獨立session隨機數,進而可以使用一個匹配的token來偽造一個跨站請求。
• 依賴session隨機數。有一個改進產生隨機數的方法是將使用者的session識別符號與CSRF token建立對應關係後儲存在服務端。伺服器在處理請求的時候,驗證請求中的token是否與session識別符號匹配。這個方法有個不好的地方就是服務端必須要維護一個很大的對應關係表(雜湊表)。
• session識別符號的HMAC。有一種方法不需要服務端來維護雜湊表,就是可以對使用者的session token做一個加密後用作CSRF 的token。例如, Ruby on Rails的web程式一般都是使用的這種方法,而且他們是使用session識別符號的HMAC來作為CSRF token的。只要所有的網站伺服器都共享了HMAC金鑰,那麼每個伺服器都可以驗證請求裡的CSRF token 是否與session識別符號匹配。HMAC的特效能確保即使攻擊者知道使用者的CSRF token,也不能推斷出使用者的session識別符號。
鑑於有充足的資源,網站都可以使用HMAC方法來防禦CSRF攻擊。但是,很多網站和一些CSRF的防禦框架(比如NoForge, CSRFx 和CSRFGuard)都不能正確的實現比較隱祕的token防禦。一個常見的錯誤就是在處理跨站請求的時候暴露了CSRF token。舉個例子,一個可信的網站在對另一個網站發起請求的時候附加上了CSRF token,那麼那個網站就可以對這個可信的網站偽造一個跨站請求。
案例研究:NoForge.NoForge就是使用服務端儲存雜湊表的方式來驗證使用者的CSRF token。它在所有連結和表單提交的時候會附加一個CSRF token,造成這種技術不太完善的原因有以下三個:
1、HTML是在瀏覽器裡動態建立的,而不會被重新加上CSRF token。有些網站是在客戶端建立HTML的。比如Gmail, Flickr, 和 Digg都是用JavaScript 來建立表單,而這些表單正是需要CSRF防禦措施的。
2、NoForge並沒有對指向本站和外站的超連結作區分。如果有一個指向外站的超連結,那麼外站可以用請求裡面獲取到使用者的CSRF token。比如,如果phpBB部署了NoForge,那麼一旦使用者點選了一個連線,連線的站點就可以獲取到使用者的CSRF token,即使NoForge區分了是本站的連結還是外站的連結,因為Referer 還是會暴露使用者的CSRF token。
3、NoForge對登陸CSRF並沒有什麼效果,因為如果使用者已經有了session識別符號(登陸了),那麼NoForge只會驗證CSRF token。儘管這種缺陷是可以修復,但是這也說明了要想正確的實施token驗證策略並不是一件很容易的事情。
雖然上述三個原因都是可以修復的,但是這些缺陷都說明了要想正確地實施token驗證策略,是很複雜的一件事情。CSRFx 和 CSRFGuard,還有很多網站都說明了這一問題。
4.2 Referer
大多數情況下,當瀏覽器發起一個HTTP請求,其中的Referer標識了請求是從哪裡發起的。如果HTTP頭裡包含有Referer的時候,我們可以區分請求是同域下還是跨站發起的,因為Referer離標明瞭發起請求的URL。網站也可以通過判斷有問題的請求是否是同域下發起的來防禦CSRF攻擊。
不幸的是,通常Referer會包含有一些敏感資訊,可能會侵犯使用者的隱私。比如,Referer可以顯示使用者對某個私密網站的搜尋和查詢。儘管這些內容對私密網站站長來說是好事,因為他們可以通過這些內容來優化搜尋引擎排名,但是一些使用者還是認為侵犯了他們的隱私。另外,許多組織也很擔憂Referer可能會將內網的一些機密資訊洩露出去。
漏洞。從歷史上來看,瀏覽器的一些漏洞使得一些惡意網站有欺騙Referer的價值,尤其是在使用代理伺服器的時候。很多對Referer欺騙的討論都標明瀏覽器允許Referer可以偽造。Mozilla在Fire-fox 1.0.7裡面已經修復了Referer欺騙的漏洞。目前的IE則還有這方面的漏洞,但是這些漏洞只能影響XMLHttpRequest,並且只能用來偽造Referer跳轉到攻擊者自己的網站。
尺度。如果網站選擇使用Referer來防禦CSRF攻擊的話,那麼網站的開發人員就需要決定到底是使用比較寬鬆還是比較嚴格的Referer驗證策略。如果採用寬鬆的Referer驗證策略,網站就應該阻止Referer值不對的請求。如果請求裡面沒有Referer,就接收請求。儘管這個方法用的很普遍,但是它很容易被繞過。因為攻擊者可以在header裡面去掉Referer。例如,FTP和資料URL發起的請求裡面就不包含Referer。如果使用嚴格的Referer驗證策略,網站還要阻止沒有Referer的請求。這樣做主要是為了防止惡意網站主動隱藏Referer,但也會帶來相容性問題,比如會誤殺一部分合法的請求,因為有些瀏覽器和網路的設定預設就是不含有Referer的。所以說這個度一定要掌握好,很多時候取決於經驗。我們還會在4.2.1裡討論這個問題。
個案研究:Facebook。縱觀Facebook的大部分網站都是使用token認證的方式來防禦CSRF攻擊的。但是,在Facebook的登陸框部分則使用的是寬鬆的Referer驗證策略。這種方法在面對登陸CSRF的攻擊時沒有什麼作用。舉例來說,攻擊者可以講使用者從http://attacker.com/重定向到ftp://attacker.com/index.html ,然後再對Facebook發起一個跨站的登陸請求。因為請求來自FTP URL,所以大多數瀏覽器都不會在請求裡包含Referer。
4.2.1 實驗
為了評估嚴格的Referer驗證策略的相容性,我們進行了一項實驗來衡量到底有多大概率以及在什麼情況下,合法的請求裡面不含有Referer。
設計。廣告是一個很方便測量瀏覽器和網路特徵的渠道,因此我們可以利用廣告作為實驗平臺。在2008年4月5日到4月8日期間,我們從163,767個獨立IP購買了283,945 個廣告,分別是兩個不同的廣告渠道。在渠道A,我們以每千次展示0.50美元的價格購買了網路旗幟廣告,關鍵字為“火狐”,“遊戲”,“IE”,“視訊”,“YouTube”。在渠道B,我們以每千次展示5美元的價格的間隙廣告,關鍵字為“芭蕾”,“金融“,“花”,“食品”和“園藝”。我們在每個廣告渠道上花了100美元,渠道A有241,483點選量(146,310個獨立IP),渠道B有42,406點選量(18,314個獨立IP)。
廣告服務是由我們實驗室裡的兩臺主機提供,兩個獨立的域名是從不同的註冊商處購買。每當顯示廣告時,廣告會在接下來的每個請求裡面生成一個特定的識別符號,並隨機選擇一臺主機作為主伺服器。主伺服器通過HTTP或者HTTPS協議將客戶端HTML傳送到我們的伺服器,這些HTML能發起一個GET或者POST請求。其中,請求包括提交表單,影象請求和XMLHttpRequests。請求的順序是隨機的並且跟使用者的操作無關。當廣告通過了瀏覽器的安全策略之後,就向主伺服器發起一個同域的請求,同時向次伺服器發起一個跨域請求。每個伺服器的成本是400美元,域名是7美元,從一個合法的證書頒發機構獲得的90天域驗證的HTTPS證書是免費的。伺服器根據接收到的網路請求來記錄請求引數,包括Referer,User-Agent頭,日期,客戶端的C類網路,會話識別符號。伺服器還通過DOM API記錄了document.referrer的值,但是不記錄客戶端的IP地址。為了統計獨立的IP地址,伺服器利用一個隨機產生的KEY而不是記錄HMAC的方式,這個KEY會被丟棄。伺服器記錄的資訊不足以單獨確定廣告的瀏覽者到底有多少。
倫理。實驗的設計遵守兩個廣告渠道的規則。實驗中的行為基本上都是web廣告每天的行為,所以都能正常的從廣告商那裡請求額外的資源,比如圖片,音訊和視訊。儘管我們的廣告產生的HTTP請求數目遠大於普通的廣告,但是我們需要的頻寬明顯比一個視訊廣告需要的頻寬要小。我們的伺服器也像廣告商一樣,只記錄他們所記錄的資訊。實際上我們的伺服器記錄的資訊明顯要比商業的廣告商要少,因為我們並不記錄客戶端的IP地址。
結果。我們已經將結果在圖2和圖3裡總結出來了,我們還發現以下結果只有95%的可信度。
• HTTP方法裡, 跨域請求比同域請求不包含Referer頭的情況更普遍,而在POST方法(卡方係數= 2130, p值<0.001) 和GET方法(卡方係數= 2175, p值<0.001) 裡比較,前者不包含Referer頭的情況更為普遍。
• 在不包含Referer頭的統計中,HTTP比HTTPS更為普遍,包括跨域POST(卡方係數= 6754, p值<0.001)請求,跨域GET(卡方係數= 6940, p值<0.001)請求,同域POST(卡方係數= 2286, p值<0.001)請求和同域GET請求(卡方係數= 2377, p值<0.001)。
• 在不包含Referer頭的統計中,廣告渠道B所有形式的請求都比A要更普遍。這些請求形式包括:HTTP跨域POST(卡方係數= 3060, p值<0.001),HTTP同域POST(卡方係數= 6537, p值<0.001),HTTPS跨域POST(卡方係數= 49.13, p值<0.001)和HTTPS同域POST(卡方係數= 44.52, p值<0.001)請求。
• 我們還統計了自定義的header X-Requested-By(參見4.3節)和Origin(見第5章),X-Requested-By大概有0.029%到0.047%的HTTP POST請求,0.084%到0.112%的HTTP GET請求,0.008%到0.018%的HTTPS POST請求和 0.009%到0.020%的HTTPS GET請求裡不包含有Referer頭。Origin則在與上述相同的請求裡都不包含Referer頭。

圖2. 不包含Referer和Referer不正確的請求(283,945 個結果)。x和y分別代表主伺服器和次伺服器的域名
討論。下面有兩個有力的證據可以表明在不包含Referer的請求裡,通常是來自網路(攻擊)而不是瀏覽器。
1、HTTP請求比HTTPS請求不包含Referer更為普遍是因為,網路代理可以刪除HTTP請求裡的header,但是不能刪除HTTPS請求裡的header。當然,在一些企業的網路裡,一些HTTPS的終端就是一個網路代理,這種情況下代理可以修改HTTPS請求,但是這種情況是比較罕見的。
2、瀏覽器在去掉Referer的時候也會去掉document.referrer的值,但是如果Referer是在網路裡去掉的話,document.referrer卻還在。但是我們發現,Referer去掉的情況比document.referrer去掉的情況要更為普遍。
實際上,在實驗中,document.referrer值被去掉主要是因為兩種特殊的瀏覽器:PlayStation 3 瀏覽器不支援document.referrer,Opera去掉document.referrer(但是並不去掉Referer)是為了跨站HTTPS請求。XMLHttpRequest中的Referer被去掉的比例較高是由於Firefox 1.0和1.5中的bug引起的。所有的這些結果都表明只有極少數的瀏覽器被配置成不傳送Referer。
也有證據表明,Referer被去掉是由於涉及到隱私問題,當瀏覽器把Referer從網站A傳送到網站B時,使用者的隱私也在被暴露,因為網站B可以通過Referer來收集使用者在網站A的瀏覽行為。相比之下,在同域下發送Referer則不會引起隱私問題,因為網站完全可以通過cookie來收集使用者的隱私(也就是完全沒有必要通過Referer來收集)。我們還發現,跨站請求比同站請求要更多的阻止Referer,說明由於考慮到隱私的問題,所以才會人為的阻止Referer傳送。
由此,我們得出兩個主要的結論:
1、通過HTTPS來防禦CSRF。在HTTPS請求裡,Referer可以被用來防禦CSRF。為了實施用Referer來防禦CSRF的策略,網站必須拒絕那些沒有Referer的請求,因為攻擊者可以控制瀏覽器來去掉Referer。而在HTTP裡,網站則不能一味的拒絕沒有Referer的請求,因為考慮到相容性,可能有相當大一部分 (大約 3–11%)使用者可能就訪問不了網站了。不同的是在HTTPS裡,則可以執行嚴格的Referer驗證策略,因為只有很小的一部分(0.05–0.22%)瀏覽器會去掉Referer。特別需要指出的是,嚴格的Referer驗證策略非常適合用來防禦登陸CSRF,因為通常情況下,登陸請求都是通過HTTPS協議發起的。
2、隱私問題。嚴格的Referer策略是很好的CSRF的防禦方案,因為它實施起來很簡單。不幸的是,隱私策略可能會阻止此方案的流行。因此,瀏覽器新的安全效能和新的CSRF防禦機制都必須要先解決好隱私問題,才能大規模的部署。
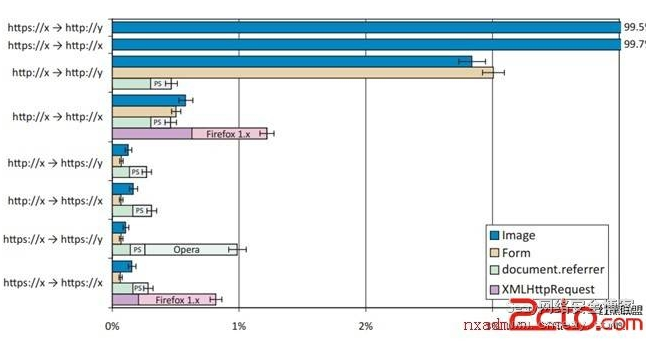
圖3. 廣告渠道A中不包含Referer和Referer不正確的請求(241,483 個結果)。Opera阻止了跨站的HTTPS document.referrer,Firefox 1.0和1.5由於bug在XMLHttpRequest的時候不傳送Referer,PlayStation 3(圖中即為PS)不支援document.referrer。
4.3 自定義HTTP header
我們也可以用自定義HTTP頭的方法來防禦CSRF攻擊,因為雖然瀏覽器會阻止向外站傳送自定義的HTTP頭,但是允許向本站通過XMLHttpRequest的方式傳送自定義HTTP頭。比如,prototype.js這個JavaScript庫就是使用這種方法,並且增加了 X-Requested-By頭到XMLHttpRequest裡面 。Google Web Toolkit 也建議開發者用在XMLHttpRequest裡增加一個X-XSRF-Cookie頭的方法來防禦CSRF攻擊,其中XMLHttpRequets包含有cookie的值。當然XMLHttpRequets裡面的cookie並不需要用來防禦CSRF,因為只需要有頭部分就足夠了。
在使用這種方法來防禦CSRF攻擊的時候,網站必須在所有的請求裡使用XMLHttpRequest並附加一個自定義頭(比如X-Requested-By),並且拒絕所有沒有自定義頭的的請求。例如,為了防禦登陸CSRF的攻擊,網站必須通過XMLHttpRequest的方式傳送使用者的身份驗證資訊到伺服器。在我們的實驗裡,在伺服器接收到的請求裡面,大約有99.90–99.99%的請求是含有X-Requested-By頭的,這表明這一方法適用於絕大多數的使用者。
五 、建議:Origin欄位
為了防止CSRF的攻擊,我們建議修改瀏覽器在傳送POST請求的時候加上一個Origin欄位,這個Origin欄位主要是用來標識出最初請求是從哪裡發起的。如果瀏覽器不能確定源在哪裡,那麼在傳送的請求裡面Origin欄位的值就為空。
隱私方面:這種Origin欄位的方式比Referer更人性化,因為它尊重了使用者的隱私。
1、Origin欄位裡只包含是誰發起的請求,並沒有其他資訊 (通常情況下是方案,主機和活動文件URL的埠)。跟Referer不一樣的是,Origin欄位並沒有包含涉及到使用者隱私的URL路徑和請求內容,這個尤其重要。
2、Origin欄位只存在於POST請求,而Referer則存在於所有型別的請求。
隨便點選一個超連結(比如從搜尋列表裡或者企業intranet),並不會傳送Origin欄位,這樣可以防止敏感資訊的以外洩露。
在應對隱私問題方面,Origin欄位的方法可能更能迎合使用者的口味。
服務端要做的:用Origin欄位的方法來防禦CSRF攻擊的時候,網站需要做到以下幾點:
1、在所有能改變狀態的請求裡,包括登陸請求,都必須使用POST方法。對於一些特定的能改變狀態的GET請求必須要拒絕,這是為了對抗上文中提到過的論壇張貼的那種危害型別。
2、對於那些有Origin欄位但是值並不是我們希望的(包括值為空)請求,伺服器要一律拒絕。比如,伺服器可以拒絕一切Origin欄位為外站的請求。
安全性分析:雖然Origin欄位的設計非常簡單,但是用它來防禦CSRF攻擊可以起到很好的作用。
1、去掉Origin欄位。由於支援這種方法的瀏覽器在每次POST請求的時候都會帶上源header,那麼網站就可以通過檢視是否存在這種Origin欄位來確定請求是否是由支援這種方法的瀏覽器發起的。這種設計能有效防止攻擊者將一個支援這種方法的瀏覽器改變成不支援這種方法的瀏覽器,因為即使你改變瀏覽器去掉了Origin欄位,Origin欄位還是存在,只不過值變為空了。這跟Referer很不一樣,因為Referer 只要是在請求裡去掉了,那伺服器就探測不到了。
2、DNS重新繫結。在現有的瀏覽器裡面,對於同站的XMLHttpRequests,Origin欄位可以被偽造。只依賴網路連線進行身份驗證的網站應當使用在第2章裡提到的DNS重新繫結的方法,比如驗證header裡的Host欄位。在使用Origin欄位來防禦CSRF攻擊的時候,也需要用到DNS重新繫結的方法,他們是相輔相成的。當然對於在第四章裡提到的CSRF防禦方法,也需要用到DNS重新繫結的方法。
3、外掛。如果網站根據crossdomain.xml準備接受一個跨站HTTP請求的時候,攻擊者可以在請求裡用Flash Player來設定Origin欄位。在處理跨站請求的時候,token驗證的方法處理的不好,因為token會暴露。為了應對這些攻擊,網站不應當接受不可信來源的跨站請求。
4、應用。Origin欄位跟以下四個用來確定請求來源的建議非常類似。Origin欄位以下四個建議的基礎上統一併改進了,目前已經有幾個組織採用了Origin欄位的方法建議。
• Cross-Site XMLHttp Request。Cross-Site XMLHttp Request的方法規定了一個Access-Control-Origin 欄位,用來確定請求來源。這個欄位存在於所有的HTTP方法,但是它只在XMLHttpRequests請求的時候才會帶上。我們對Origin欄位的設想就是來源於這個建議,而且Cross-Site XMLHttp Request工作組已經接受我們的建議願意將欄位統一命名為Origin。
•XDomainRequest。在Internet Explorer 8 Beta 1裡有XDomainRequest的API,它在傳送HTTP請求的時候將Referer裡的路徑和請求內容刪掉了。被縮減後的Referer欄位可以標識請求的來源。我們的實驗結果表明這種刪減的Referer欄位經常會被拒絕,而我們的Origin欄位卻不會。微軟已經發表宣告將會採用我們的建議將XDomainRequest裡的刪減Referer更改為Origin欄位。
• JSONRequest。在JSONRequest這種設計裡,包含有一個Domain欄位用來標識發起請求的主機名。相比之下,我們的Origin欄位方法不僅包含有主機,還包含請求的方案和埠。JSONRequest規範的設計者已經接受我們的建議願意將Domain欄位更改為Origin欄位,以用來防止網路攻擊。
• Cross-Document Messaging。在HTML5規範裡提出了一個建議,就是建立一個新的瀏覽器API,用來驗證客戶端在HTML檔案之間連結。這種設計裡面包含一個不能被覆蓋的origin屬性,如果不是在客戶端的話,在服務端驗證這種origin屬性的過程與我們驗證origin欄位的過程其實是一樣的。
具體實施:我們在伺服器和瀏覽器端都實現了利用origin欄位的方法來防止CSRF攻擊。在瀏覽器端我們的實現origin欄位方式是,在WebKit新增一個8行程式碼的補丁,Safari裡有我們的開源元件,Firefox裡有一個466行程式碼的外掛。在伺服器端我們實現origin欄位的方式是,在ModSecurity應用防火牆裡我們只用3行程式碼,在Apache裡新增一個應用防火牆語言(見圖4)。這些規則在POST請求裡能驗證Host欄位和具有合法值的origin欄位。在實現這些規則來防禦CSRF攻擊的時候,網站並不需要做出什麼改變,而且這些規則還能確保GET請求沒有任何攻擊性(前提是瀏覽器端已經實現了origin欄位方法)。
圖4. 在ModSecurity裡實現origin欄位方法來防禦CSRF攻擊
六 、session初始化
在session初始化的時候,登陸CSRF只是其中一個很普遍的漏洞。在session初始化了之後,web伺服器通常會將使用者的身份與session識別符號繫結起來。因此有兩種型別的session初始化漏洞,一種是伺服器將可信使用者的身份與新初始化的session繫結到了一起,另一種是伺服器將攻擊者的身份與session繫結到了一起。
• 作為可信使用者的驗證。在某些特定的情況下,攻擊者可以使用一個可預見的session識別符號強制網站開啟一個新的session。這一型別的漏洞一般都被稱為session定位漏洞。當用戶提供他們的身份資訊給一個可信網站來驗證後,網站會將使用者的身份與一個可預見的session識別符號繫結到一起。攻擊者此時就可以通過這個session識別符號來扮演使用者的身份登入網站。
• 作為攻擊者的驗證。攻擊者也可以通過使用者的瀏覽器強制網站開始一個新的session,並且強制session與攻擊者的身份繫結到一起(第3章已經說明了攻擊是怎麼完成的)。登入CSRF攻擊只是這一型別中的最簡單漏洞,但是攻擊者還可以有其他的方法強制通過使用者的瀏覽器將session與自己繫結到一起。
6.1 HTTP請求
OpenID:像LiveJournal、Movable Type和WordPress等很多網站都在使用OpenID 協議,建議這些可以使用自簽名隨機數的方式來對抗回覆攻擊,但不要將OpenID session與使用者的瀏覽器繫結到一起,因為攻擊者可以強制使用者的瀏覽器初始化一個session然後將session與自己繫結到一起。規範中聲明瞭: return_to 這個URL可能被委託方用來在使用者的驗證請求與驗證答覆之間建立聯絡。但是LiveJournal, Movable Type和WordPress都認為這不是必須的,也沒有實施它。為了對抗這種攻擊,在協議初始化的時候委託方應該生成一個新的隨機數,並將它與瀏覽器的cookie儲存到一起,將它包含到return_to引數裡。委託方會將在cookie裡的隨機數與return_to引數裡的隨機數匹配。這種方法其實與token驗證的方法很類似,並且確保了從一開始OpenID 協議的session就能在同一個瀏覽器上完成。
PHP cookieless(不用cookie的)驗證:這種方法被Hushmail 等網站用來防止使用者的電腦上還保留有cookie。Cookieless 驗證方法是將使用者的session識別符號儲存在請求的引數裡面。但是這個方法不能將session與使用者的瀏覽器繫結到一起,因此攻擊者可以強制使用者的瀏覽器初始化一個session與攻擊者繫結到一起。為了防止這種攻擊,網站必須使用另外的方法將session識別符號與使用者的瀏覽器繫結到一起。例如,網站可以構造一個長時間的frame,其中包含有session識別符號。這種方式是通過將session識別符號儲存在記憶體裡來將使用者的瀏覽器與session繫結。使用PHP cookieless驗證方法的網站通常也會存在session初始化漏洞,會讓攻擊者可以模仿一個可信的使用者。當然,類似的session定位漏洞有很多標準的防禦方法,例如,當用戶登陸後,網站可以再次生成一個session識別符號。
6.2 Cookie重寫
漏洞。伺服器可以在Set-Cookie欄位裡用一個Secure flag方式告訴瀏覽器此cookie只能通過HTTPS協議傳送。現金的瀏覽器都支援這個特性,並且在一些對安全性要求比較高的網站,這個特性通常被用來保護session。但是,這個Secure flag並不能保證完整性。攻擊者可以模仿網站通過HTTP向同一個主機發送Set-Cookie欄位,並在主機上設立了cookie。當瀏覽器通過HTTPS向網站傳送cookie的時候,網站並沒有一個機制來確定cookie是否被攻擊者重寫。如果這個cookie裡面包含有使用者的session識別符號,攻擊者就可以很容易的通過重寫使用者的cookie來發起一個session初始化攻擊。基本上沒有網站能夠防禦這種攻擊,因為他們需要客戶端提供一個cookie來作完整性驗證。但是,有人建議使用瀏覽器的特性,比如localStorage,它可以彌補這一不足。換句話說,如果網站聲稱它的應用層session的驗證完全跟基於cookie的HTTP層的session無關的話,攻擊者可以在驗證之前就重寫使用者的cookie,然後扮演使用者登陸網站。儘管安全人員很多年前就知道攻擊者可以重寫cookie,但是瀏覽器廠商並沒有什麼好的對抗辦法。廠商考慮到了通過拒絕HTTP請求的方式來對抗cookie重寫的攻擊,但是這一做法顯然不太合理。更糟糕的是,這一方法並不能提供cookie的完整性,因為Cookie 欄位本身並不能區分cookie 裡是否含有Secure flag。
防禦方法。為了不改變現有的cookie欄位而就能保護cookie的完整性(是否包含有Secure flag),我們建議瀏覽器可以在HTTPS請求裡面新加一個Cookie-Integrity欄位,專門用來檢測cookie的完整性狀態。這樣也是考慮了相容以前策略的做法。例如
Cookie: SID=DQAAAHQA…; pref=ac81a9…; TM=1203…
Cookie-Integrity: 0, 2
當cookie被設定成使用HTTPS協議傳送的時候,Cookie-Integrity欄位可以在請求裡面用來描述cookie欄位的索引。如果請求裡面的cookie都沒有被設定成HTTPS,那麼Cookie-Integrity欄位的值就為空。對Cookie-Integrity欄位的完整性的保護與Secure flag能提供的機密是相輔相成的,並且這樣做也具備很好的相容性,因為伺服器會忽略具有無法識別的header的請求。下面是幾個設計的建議:
頻寬。在每一個HTTP請求中新增內容必然會增加所有網路的延遲,為了節省頻寬,我們只在cookie欄位裡新增cookie的索引值。還有一個建議做法就是新增一個類似cookie欄位的副本,命名為cookie2。
多樣性。當主機準備建立一個與已有cookie同名的cookie,那麼cookie完全可以包含兩個同名的cookie。因為在此種情況下,也許Cookie-Integrity欄位不能根據cookie名來分辨它們,但是我們可以在cookie欄位裡面通過索引值來區別它們。
Rollback。在HTTPS請求裡面加入Cookie-Integrity欄位可以有效的防止rollback攻擊。 如果沒有Cookie-Integrity欄位,並且在不能保證cookie完整性的時候,那麼伺服器此時也不能確定請求裡面的cookie是否具備完整性(假設請求是從一個低版本的主機發出的,即不支援Cookie-Integrity欄位)。
同胞域。假設有這樣一種情況,example.com分別包含有一個可信的和一個不可信的子域,www.example.com 和 users.example.com。在對example.com設定cookie的時候,不可信的子域就可以注入可信子域的cookie欄位。Cookie-Integrity欄位並不能防止這種攻擊,但是我們可以通過增加一個欄位來標識每個cookie的來源(當然這要取決於對頻寬和複雜性的考慮)。
我們在Firefox裡用202行JavaScript程式碼新增實現了Cookie-Integrity欄位,並增加了一個Integrity flag儲存到cookie裡面,主要用來記錄這個cookie是否被設定成使用HTTPS傳輸。
七 、總結和建議
CSRF是當今一個被利用的非常廣泛的漏洞。很多網站修復了他們的包括登陸CSRF漏洞在內的CSRF漏洞。基於這篇文章中提到的實驗和分析,我們建議網站在不同的情況下使用不同的CSRF防禦策略。
• 登陸CSRF。我們建議使用嚴格的Referer驗證策略來防禦登陸CSRF,因為登陸的表單一般都是通過HTTPS傳送,在合法請求裡面的Referer都是真實可靠的。如果碰到沒有Referer欄位的登陸請求,那麼網站應該直接拒絕以防禦這種惡意的修改。
• HTTPS。對於那些專門使用HTTPS協議的網站,比如銀行類,我們也建議使用嚴格的Referer驗證策略來防禦CSRF攻擊。對於那些有特定跨站需求的請求,網站應該建立一份白名單,比如主頁等。
• 第三方內容。如果網站納入了第三方的內容,比如影象外鏈和超連結,網站應該使用一個正確的驗證token 的框架,比如 Ruby-on-Rails。如果這樣的一個框架效果不好的話,網站就應該花時間來設計更好的token 驗證策略,可以用HMAC方法將使用者的session與token 繫結到一起。
對於更長遠的建議,我們希望能用Origin欄位來替代Referer,因為這樣既保留了既有效果,又尊重了使用者的隱私。最終要廢除利用token來防禦CSRF的方式,因為這樣網站就可以更好的保護無論是HTTP還是HTTPS請求,而不用擔心token是否會洩露。
未來的工作。如果使用Origin欄位的方法來防禦CSRF攻擊,網站要注意在處理GET請求的時候不要有什麼副作用。儘管HTTP規範裡已經這樣要求,但是很多網站並沒有很好的遵守這一要求。讓網站都執行這一要求正是我們未來的工作重點。
CSRF攻擊還興起了一個變種,即攻擊者在一個可信的網站嵌入一個frame並引誘使用者點選(點選劫持)。儘管從我們的定義上講,這個並不能算是CSRF攻擊,但是他們有一個很相似的地方就在於,攻擊者都是利用使用者的瀏覽器來對他信任的網站發起一個請求。防禦這種攻擊的傳統辦法都是frame busting,但是這種方法有個問題就是它依賴JavaScript,而JavaScript很有可能會被使用者或者攻擊者禁用。在這裡我們有個建議是,可以在Origin欄位裡新增一些內容用來描述frame的來源,也就是frame裡面的超連結,這樣受信任的網站就可以根據frame的來源來決定是拒絕還是接受這個請求。