
JUC包的兩大支柱之volatile
volatile在JUC包中所處的位置
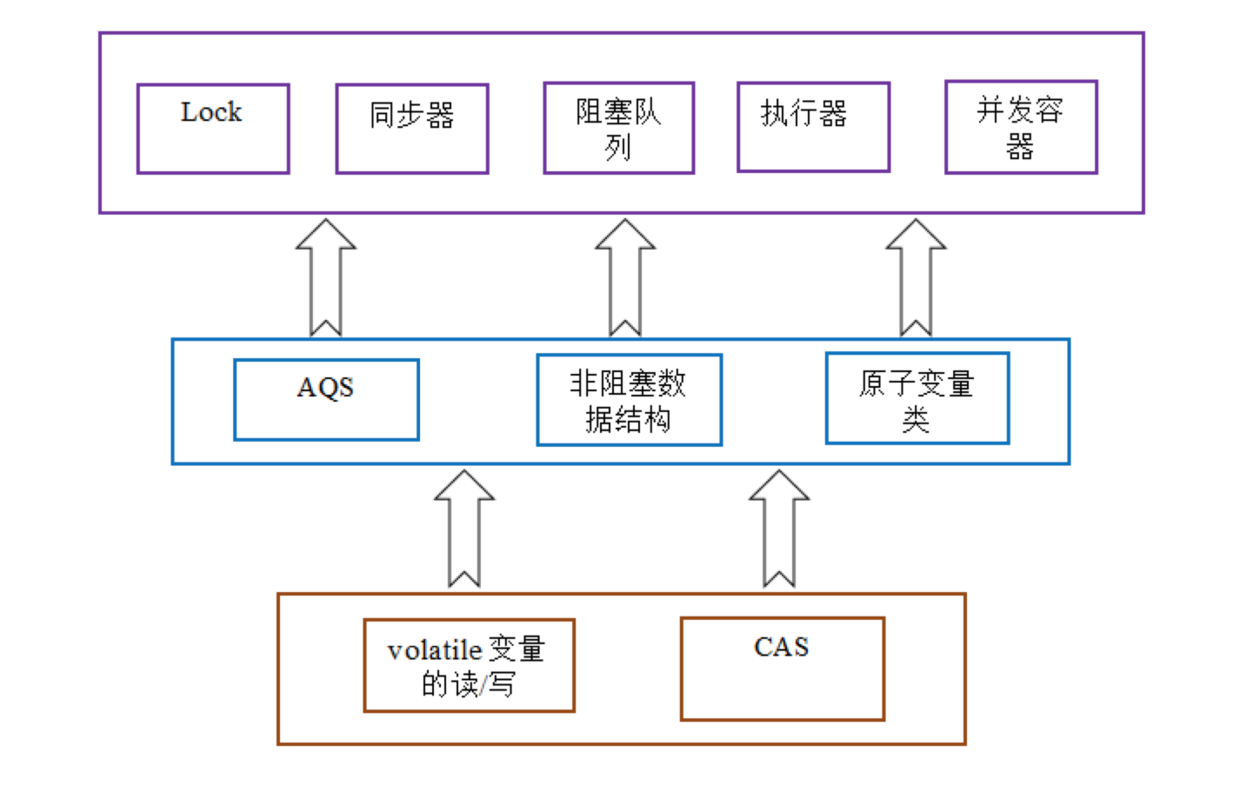
volatile兩大作用
一旦一個共享變數(類的成員變數、類的靜態成員變數)被volatile修飾之後,那麼就具備了兩層語義:1)保證了不同執行緒對這個變數進行操作時的可見性,即一個執行緒修改了某個變數的值,這新值對其他執行緒來說是立即可見的。
2)禁止進行指令重排序。
需注意volatile並不保證操作的原子性。
(一)記憶體可見性
1 概念
JVM記憶體模型(JMM):主記憶體和執行緒獨立的工作記憶體
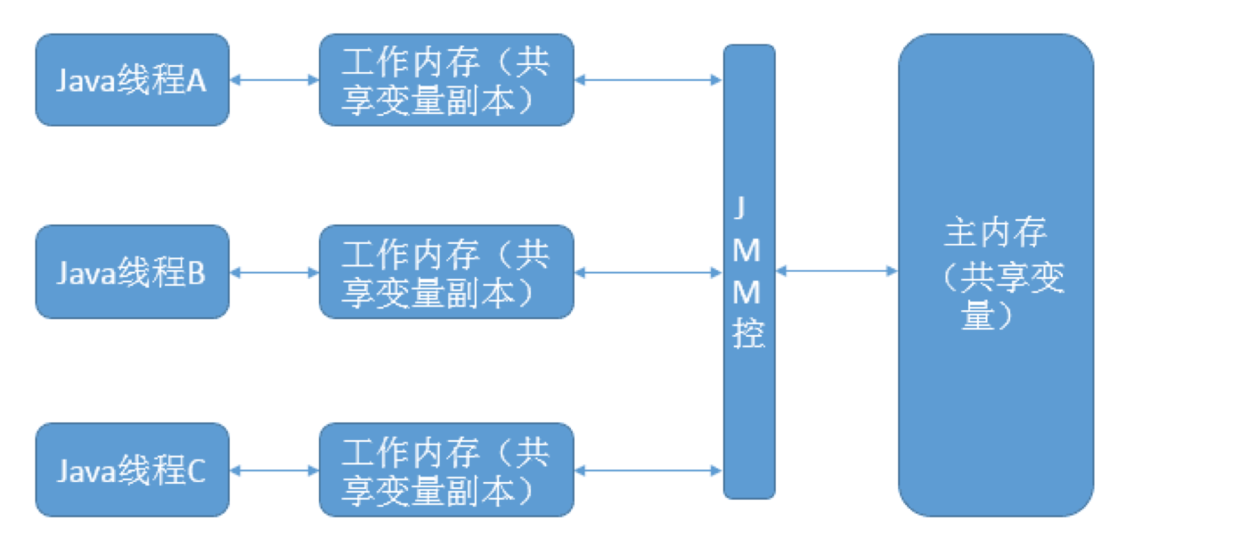
java記憶體模型
Java記憶體模型規定,對於多個執行緒共享的變數,儲存在主記憶體當中,每個執行緒都有自己獨立的工作記憶體(比如CPU的暫存器、CPU快取),執行緒只能訪問自己的工作記憶體,不可以訪問其它執行緒的工作記憶體。
工作記憶體中儲存了主記憶體共享變數的副本,執行緒要操作這些共享變數,只能通過操作工作記憶體中的副本來實現,操作完畢之後再同步回到主記憶體當中。
如何保證多個執行緒操作主記憶體的資料完整性是一個難題,Java記憶體模型也規定了工作記憶體與主記憶體之間互動的協議,定義了8種原子操作:
(1) lock:將主記憶體中的變數鎖定,為一個執行緒所獨佔
(2) unclock:將lock加的鎖定解除,此時其它的執行緒可以有機會訪問此變數
(3) read:將主記憶體中的變數值讀到工作記憶體當中
(4) load:將read讀取的值儲存到工作記憶體中的變數副本中。
(5) use:將值傳遞給執行緒的程式碼執行引擎
(6) assign:將執行引擎處理返回的值重新賦值給變數副本
(7) store:將變數副本的值儲存到主記憶體中。
(8) write:將store儲存的值寫入到主記憶體的共享變數當中。
通過上面Java記憶體模型的概述,我們會注意到這麼一個問題,每個執行緒在獲取鎖之後會在自己的工作記憶體來操作共享變數,操作完成之後將工作記憶體中的副本回寫到主記憶體,並且在其它執行緒從主記憶體將變數同步回自己的工作記憶體之前,共享變數的改變對其是不可見的。即其他執行緒的本地記憶體中的變數已經是過時的,並不是更新後的值。
(二)指令重排
1 概念
在執行程式時,為了提高效能,編譯器和處理器常常會對指令做重排序。重排序分3種類型:編譯器優化的重排序。編譯器在不改變單執行緒程式語義的前提下,可以重新安排語句的執行順序。指令級並行的重排序。現代處理器採用了指令級並行技術(Instruction-LevelParallelism,ILP)來將多條指令重疊執行。如果不存在資料依賴性,處理器可以改變語句對應機器指令的執行順序。記憶體系統的重排序。由於處理器使用快取和讀/寫緩衝區,這使得載入和儲存操作看上去可能是在亂序執行。
從Java原始碼到最終實際執行的指令序列,會分別經歷下面3種重排序:

對於編譯器,JMM的編譯器重排序規則會禁止特定型別的編譯器重排序(不是所有的編譯器重排序都要禁止)。對於處理器重排序,JMM的處理器重排序規則會要求Java編譯器在生成指令序列時,插入特定型別的記憶體屏障(Memory Barriers,Intel稱之為Memory Fence)指令,通過記憶體屏障指令來禁止特定型別的處理器重排序。JMM屬於語言級的記憶體模型,它確保在不同的編譯器和不同的處理器平臺之上,通過禁止特定型別的編譯器重排序和處理器重排序,為程式設計師提供一致的記憶體可見性保證。
指令重排序是JVM為了優化指令,提高程式執行效率,在不影響單執行緒程式執行結果的前提下,儘可能地提高並行度。編譯器、處理器也遵循這樣一個目標。注意是單執行緒。多執行緒的情況下指令重排序就會給程式設計師帶來問題。
不同的指令間可能存在資料依賴。比如下面計算圓的面積的語句:
double r = 2.3d;//(1)
double pi =3.1415926; //(2)
double area = pi* r * r; //(3)
area的計算依賴於r與pi兩個變數的賦值指令。而r與pi無依賴關係。
as-if-serial語義是指:不管如何重排序(編譯器與處理器為了提高並行度),(單執行緒)程式的結果不能被改變。這是編譯器、Runtime、處理器必須遵守的語義。
雖然,(1) – happensbefore -> (2),(2) – happens before -> (3),但是計算順序(1)(2)(3)與(2)(1)(3) 對於r、pi、area變數的結果並無區別。編譯器、Runtime在優化時可以根據情況重排序(1)與(2),而絲毫不影響程式的結果。
指令重排序包括編譯器重排序和執行時重排序。
2 指令重排帶來的問題
如果一個操作不是原子的,就會給JVM留下重排的機會。下面看幾個例子:
例子1:A執行緒指令重排導致B執行緒出錯
對於在同一個執行緒內,這樣的改變是不會對邏輯產生影響的,但是在多執行緒的情況下指令重排序會帶來問題。看下面這個情景:
線上程A中:
context = loadContext();
inited = true;
線上程B中:
while(!inited ){ //根據執行緒A中對inited變數的修改決定是否使用context變數
sleep(100);
}
doSomethingwithconfig(context);
假設執行緒A中發生了指令重排序:
inited = true;
context = loadContext();
那麼B中很可能就會拿到一個尚未初始化或尚未初始化完成的context,從而引發程式錯誤。
例子2:指令重排導致單例模式失效
我們都知道一個經典的懶載入方式的雙重判斷單例模式:
public class Singleton {
private static Singleton instance = null;
private Singleton() { }
public static Singleton getInstance() {
if(instance == null) {
synchronzied(Singleton.class) {
if(instance == null) {
instance = new Singleton(); //非原子操作
}
}
}
return instance;}
}
看似簡單的一段賦值語句:instance= new Singleton(),但是很不幸它並不是一個原子操作,其實際上可以抽象為下面幾條JVM指令:
memory =allocate(); //1:分配物件的記憶體空間
ctorInstance(memory); //2:初始化物件
instance =memory; //3:設定instance指向剛分配的記憶體地址
上面操作2依賴於操作1,但是操作3並不依賴於操作2,所以JVM是可以針對它們進行指令的優化重排序的,經過重排序後如下:
memory =allocate(); //1:分配物件的記憶體空間
instance =memory; //3:instance指向剛分配的記憶體地址,此時物件還未初始化
ctorInstance(memory); //2:初始化物件
可以看到指令重排之後,instance指向分配好的記憶體放在了前面,而這段記憶體的初始化被排在了後面。
線上程A執行這段賦值語句,在初始化分配物件之前就已經將其賦值給instance引用,恰好另一個執行緒進入方法判斷instance引用不為null,然後就將其返回使用,導致出錯。
3 防止指令重排
除了前面記憶體可見性中講到的volatile關鍵字可以保證變數修改的可見性之外,還有另一個重要的作用:在JDK1.5之後,可以使用volatile變數禁止指令重排序。
解決方案:例子1中的inited和例子2中的instance以關鍵字volatile修飾之後,就會阻止JVM對其相關程式碼進行指令重排,這樣就能夠按照既定的順序指執行。
volatile關鍵字通過提供“記憶體屏障”的方式來防止指令被重排序,為了實現volatile的記憶體語義,編譯器在生成位元組碼時,會在指令序列中插入記憶體屏障來禁止特定型別的處理器重排序。
大多數的處理器都支援記憶體屏障的指令。
對於編譯器來說,發現一個最優佈置來最小化插入屏障的總數幾乎不可能,為此,Java記憶體模型採取保守策略。下面是基於保守策略的JMM記憶體屏障插入策略:
在每個volatile寫操作的前面插入一個StoreStore屏障。
在每個volatile寫操作的後面插入一個StoreLoad屏障。
在每個volatile讀操作的後面插入一個LoadLoad屏障。
在每個volatile讀操作的後面插入一個LoadStore屏障。
(三)總結
volatile是輕量級同步機制
相對於synchronized塊的程式碼鎖,volatile應該是提供了一個輕量級的針對共享變數的鎖,當我們在多個執行緒間使用共享變數進行通訊的時候需要考慮將共享變數用volatile來修飾。
volatile是一種稍弱的同步機制,在訪問volatile變數時不會執行加鎖操作,也就不會執行執行緒阻塞,因此volatilei變數是一種比synchronized關鍵字更輕量級的同步機制。
volatile使用建議
使用建議:在兩個或者更多的執行緒需要訪問的成員變數上使用volatile。當要訪問的變數已在synchronized程式碼塊中,或者為常量時,沒必要使用volatile。
由於使用volatile遮蔽掉了JVM中必要的程式碼優化,所以在效率上比較低,因此一定在必要時才使用此關鍵字。
volatile和synchronized區別
1、volatile不會進行加鎖操作:
volatile變數是一種稍弱的同步機制在訪問volatile變數時不會執行加鎖操作,因此也就不會使執行執行緒阻塞,因此volatile變數是一種比synchronized關鍵字更輕量級的同步機制。
2、volatile變數作用類似於同步變數讀寫操作:
從記憶體可見性的角度看,寫入volatile變數相當於退出同步程式碼塊,而讀取volatile變數相當於進入同步程式碼塊。
3、volatile不如synchronized安全:
在程式碼中如果過度依賴volatile變數來控制狀態的可見性,通常會比使用鎖的程式碼更脆弱,也更難以理解。僅當volatile變數能簡化程式碼的實現以及對同步策略的驗證時,才應該使用它。一般來說,用同步機制會更安全些。
4、volatile無法同時保證記憶體可見性和原則性:
加鎖機制(即同步機制)既可以確保可見性又可以確保原子性,而volatile變數只能確保可見性,原因是宣告為volatile的簡單變數如果當 前值與該變數以前的值相關,那麼volatile關鍵字不起作用,也就是說如下的表示式都不是原子操作:“count++”、“count = count+1”。
當且僅當滿足以下所有條件時,才應該使用volatile變數:
1、 對變數的寫入操作不依賴變數的當前值,或者你能確保只有單個執行緒更新變數的值。
2、該變數沒有包含在具有其他變數的不變式中。
在需要同步的時候,第一選擇應該是synchronized關鍵字,這是最安全的方式,嘗試其他任何方式都是有風險的。尤其在、jdK1.5 之後,對synchronized同步機制做了很多優化,如:自適應的自旋鎖、鎖粗化、鎖消除、輕量級鎖等,使得它的效能明顯有了很大的提升。volatile相對於synchronized稍微輕量 些,在某些場合它可以替代synchronized,但是又不能完全取代synchronized,只有在某些場合才能夠使用volatile。volatile經常用於兩個場景:狀態標記、double check。