
網路爬蟲框架Webmagic
1 談談網路爬蟲
1.1 什麼是網路爬蟲
在大資料時代,資訊的採集是一項重要的工作,而網際網路中的資料是海量的,如果單純靠人力進行資訊採集,不僅低效繁瑣,蒐集的成本也會提高。如何自動高效地獲取網際網路中我們感興趣的資訊併為我們所用是一個重要的問題,而爬蟲技術就是為了解決這些問題而生的。
網路爬蟲(Web crawler)也叫做網路機器人,可以代替人們自動地在網際網路中進行資料資訊的採集與整理。它是一種按照一定的規則,自動地抓取全球資訊網資訊的程式或者指令碼,可以自動採集所有其能夠訪問到的頁面內容,以獲取或更新這些網站的內容和檢索方式。
從功能上來講,爬蟲一般分為資料採集,處理,儲存三個部分。爬蟲從一個或若干初始網頁的URL開始,獲得初始網頁上的URL,在抓取網頁的過程中,不斷從當前頁面上抽取新的URL放入佇列,直到滿足系統的一定停止條件。
1.2 網路爬蟲可以做什麼
我們初步認識了網路爬蟲,網路爬蟲具體可以做什麼呢?
a.可以實現搜尋引擎
b.大資料時代,可以讓我們獲取更多的資料來源。
c.快速填充測試和運營資料
d.為人工智慧提供訓練資料集
1.3 網路爬蟲常用的技術(Java)
1.3.1 底層實現 HttpClient + Jsoup
HttpClient 是 Apache Jakarta Common 下的子專案,用來提供高效的、最新的、功能豐富的支援 HTTP 協議的客戶端程式設計工具包,並且它支援 HTTP 協議最新的版本和建議。 HttpClient 已經應用在很多的專案中,比如 Apache Jakarta 上很著名的另外兩個開源專案 Cactus 和 HTMLUnit 都使用了 HttpClient。更多資訊請關注
jsoup 是一款Java 的HTML解析器,可直接解析某個URL地址、HTML文字內容。它提供了一套非常省力的API,可通過DOM,CSS以及類似於jQuery的操作方法來取出和操作資料。
1.3.2 開源框架 Webmagic
webmagic是一個開源的Java爬蟲框架,目標是簡化爬蟲的開發流程,讓開發者專注於邏輯功能的開發。webmagic的核心非常簡單,但是覆蓋爬蟲的整個流程,也是很好的學習爬蟲開發的材料。
webmagic的主要特色:
a.完全模組化的設計,強大的可擴充套件性。
b.核心簡單但是涵蓋爬蟲的全部流程,靈活而強大,也是學習爬蟲入門的好材料。
c.提供豐富的抽取頁面API。
d.無配置,但是可通過POJO+註解形式實現一個爬蟲。
e. 支援多執行緒。
f. 支援分散式。
g.支援爬取js動態渲染的頁面。
h.無框架依賴,可以靈活的嵌入到專案中去。
2 爬蟲框架Webmagic
2.1 架構解析
WebMagic專案程式碼分為核心和擴充套件兩部分。核心部分(webmagic-core)是一個精簡
的、模組化的爬蟲實現,而擴充套件部分則包括一些便利的、實用性的功能。擴充套件部分(webmagic-extension)提供一些便捷的功能,例如註解模式編寫爬蟲等。同時內建了一些常用的元件,便於爬蟲開發。
WebMagic的設計目標是儘量的模組化,並體現爬蟲的功能特點。這部分提供非常簡單、靈活的API,在基本不改變開發模式的情況下,編寫一個爬蟲。
WebMagic的結構分為Downloader、PageProcessor、Scheduler、Pipeline四大元件,並由Spider將它們彼此組織起來。這四大元件對應爬蟲生命週期中的下載、處理、管
理和持久化等功能。而Spider則將這幾個元件組織起來,讓它們可以互相互動,流程化的執行,可以認為Spider是一個大的容器,它也是WebMagic邏輯的核心。
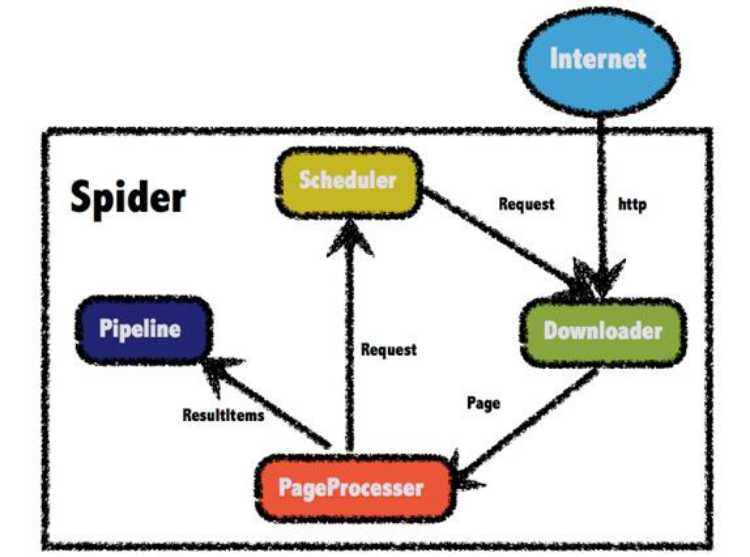
四大元件
Downloader
北京市昌平區建材城西路金燕龍辦公樓一層 電話:400-618-9090
Downloader負責從網際網路上下載頁面,以便後續處理。WebMagic預設使用了ApacheHttpClient作為下載工具。
PageProcessor
PageProcessor負責解析頁面,抽取有用資訊,以及發現新的連結。WebMagic使用Jsoup作為HTML解析工具,並基於其開發瞭解析XPath的工具Xsoup。
在這四個元件中,PageProcessor對於每個站點每個頁面都不一樣,是需要使用者定製的部分。
Scheduler
Scheduler負責管理待抓取的URL,以及一些去重的工作。WebMagic預設提供了JDK的記憶體佇列來管理URL,並用集合來進行去重。也支援使用Redis進行分散式管理。
Pipeline
Pipeline負責抽取結果的處理,包括計算、持久化到檔案、資料庫等。WebMagic預設提供了“輸出到控制檯”和“儲存到檔案”兩種結果處理方案。
2.2 PageProcessor
需求:編寫爬蟲程式,爬取csdn中部落格--工人智慧的內容
2.2.1 爬取頁面全部內容
(1)建立工程,引入依賴
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic‐core</artifactId>
<version>0.7.3</version>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic‐extension</artifactId>
<version>0.7.3</version>
</dependency>
北京市昌平區建材城西路金燕龍辦公樓一層 電話:400-618-9090
(2)編寫類實現網頁內容的爬取
package cn.itcast.demo;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor; /**
* 爬取類
*/
public class MyProcessor implements PageProcessor {
public void process(Page page) {
System.out.println(page.getHtml().toString());
}
public Site getSite() {
return Site.me().setSleepTime(100).setRetryTimes(3);
}
public static void main(String[] args) {
Spider.create( new MyProcessor() ).addUrl("https://blog.csdn.net").run();
}
}
Spider是爬蟲啟動的入口。在啟動爬蟲之前,我們需要使用一個PageProcessor建立一個Spider物件,然後使用run()進行啟動。
北京市昌平區建材城西路金燕龍辦公樓一層 電話:400-618-9090
| 方法** |
說明** |
示例** |
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
| create(PageProcessor) |
建立Spider |
Spider.create(new |
|
||||||||
| GithubRepoProcessor()) |
|
||||||||||
|
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
| addUrl(String…) |
新增初始的 |
spider |
|
||||||||
| URL |
.addUrl("http://webmagic.io/docs/") |
|
|||||||||
|
|
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
| thread(n) |
開啟n個執行緒 |
spider.thread(5) |
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
| run() |
啟動,會阻塞 |
spider.run() |
|
||||||||
| 當前執行緒執行 |
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
非同步啟動,當 |
|
|
|
|
|
|
|
|
|
|
| start()/runAsync() |
前執行緒繼續執 |
spider.start() |
|
||||||||
|
|
行 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| stop() |
停止爬蟲 |
spider.stop() |
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
新增一個 |
|
|
|
|
|
|
|
|
|
|
| addPipeline(Pipeline) |
Pipeline,一個 |
spider .addPipeline(new |
|
||||||||
| Spider可以有 |
ConsolePipeline()) |
|
|||||||||
|
|
|
||||||||||
|
|
多個Pipeline |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
設定 |
|
|
|
|
|
|
|
|
|
|
| setScheduler(Scheduler) |
Scheduler,一 |
spider.setScheduler(new |
|
||||||||
| 個Spider只能 |
RedisScheduler()) |
|
|||||||||
|
|
有個一個 |
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Scheduler |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
設定 |
|
|
|
|
|
|
|
|
|
|
| setDownloader(Downloader) |
Downloader, |
spider .setDownloader( new |
|
||||||||
| 一個Spider只 |
SeleniumDownloader()) |
|
|||||||||
|
|
能有個一個 |
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Downloader |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| get(String) |
同步呼叫,並 |
ResultItems result = spider |
|
||||||||
| 直接取得結果 |
.get("http://webmagic.io/docs/") |
|
|||||||||
|
|
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
同步呼叫,並 |
List results = spider |
|
||||||||
| getAll(String…) |
直接取得一堆 |
.getAll("http://webmagic.io/docs/", |
|
||||||||
|
|
|
|
|
|
|
|
|
||||
|
|
結果 |
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
北京市昌平區建材城西路金燕龍辦公樓一層 電話:400-618-9090
同時Spider的其他元件(Downloader、Scheduler、Pipeline)都可以通過set方法來進行設定。
Page代表了從Downloader下載到的一個頁面——可能是HTML,也可能是JSON或者其他文字格式的內容。Page是WebMagic抽取過程的核心物件,它提供一些方法可供抽取、結果儲存等。
Site用於定義站點本身的一些配置資訊,例如編碼、HTTP頭、超時時間、重試策略等、代理等,都可以通過設定Site物件來進行配置。
| 方法** |
說明** |
示例** |
|
||
|
|
|
|
|
|
|
| setCharset(String) |
設定編碼 |
site.setCharset("utf-8") |
|
||
|
|
|
|
|
|
|
| setUserAgent(String) |
設定 |
site.setUserAgent("Spider") |
|
||
| UserAgent |
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
設定超時時 |
|
|
|
|
| setTimeOut(int) |
間, 單位 |
site.setTimeOut(3000) |
|
||
|
|
是毫秒 |
|
|
|
|
|
|
|
|
|
|
|
| setRetryTimes(int) |
設定重試次 |
site.setRetryTimes(3) |
|
||
|
|
數 |
|
|
|
|
|
|
|
|
|
|
|
| setCycleRetryTimes(int) |
設定迴圈重 |
site.setCycleRetryTimes(3) |
|
||
|
|
試次數 |
|
|
|
|
|
|
|
|
|
|
|
| addCookie(String,String) |
新增一條 |
site.addCookie("dotcomt_user","code4craft") |
|
||
| cookie |
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
設定域名, |
|
|
|
|
|
|
需設定域名 |
|
|
|
|
| setDomain(String) |
後, |
site.setDomain("github.com") |
|
||
|
|
addCookie |
|
|
|
|
|
|
才可生效 |
|
|
|
|
|
|
|
|
|
|
|
| addHeader(String,String) |
新增一條 |
site.addHeader("Referer","https://github.com") |
|
||
|
|
addHeader |
|
|
|
|
|
|
|
|
|
|
|
| setHttpProxy(HttpHost) |
設定Http代 |
site.setHttpProxy(new |
|
||
| 理 |
HttpHost("127.0.0.1",8080)) |
|
|||
|
|
|
||||
|
|
|
|
|
|
|
北京市昌平區建材城西路金燕龍辦公樓一層 電話:400-618-9090
2.2.2 爬取指定內容(XPath)
如果我們想爬取網頁中部分的內容,需要指定xpath。
XPath,即為XML路徑語言(XMLPathLanguage),它是一種用來確定XML文件中某部分位置的語言。XPath 使用路徑表示式來選取 XML 文件中的節點或者節點集。這些路徑表示式和我們在常規的電腦檔案系統中看到的表示式非常相似。 語法詳見附錄A
我們通過指定xpath來抓取網頁的部分內容
System.out.println(page.getHtml().xpath("//* [@id=\"nav\"]/div/div/ul/li[5]/a").toString());
以上程式碼的含義:id為nav的節點下的div節點下的div節點下的ul下的第5個li節點下的a節點
看一下輸出結果
<a href="/nav/ai">人工智慧</a>
2.2.3 新增目標地址
我們可以通過新增目標地址,從種子頁面爬取到更多的頁面
public void process(Page page) {
page.addTargetRequests( page.getHtml().links().all() );//將當前頁面
裡的所有連結都新增到目標頁面中
System.out.println(page.getHtml().xpath("//* [@id=\"nav\"]/div/div/ul/li[5]/a").toString());
}
執行後發現好多地址都出現在控制檯
2.2.4 目標地址正則匹配
需求:只提取播客的文章詳細頁內容,並提取標題
北京市昌平區建材城西路金燕龍辦公樓一層 電話:400-618-9090
package cn.itcast.demo;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor; /**
* 爬取類
*/
public class MyProcessor implements PageProcessor {
public void process(Page page) {
//page.addTargetRequests( page.getHtml().links().all() );//將當前頁
面裡的所有連結都新增到目標頁面中
//
page.addTargetRequests(
page.getHtml().links().regex("https://blog.csdn.net/[a‐z 0‐9
‐]+/article/details/[0‐9]{8}").all() );
System.out.println(page.getHtml().xpath("//* [@id=\"mainBox\"]/main/div[1]/div[1]/h1/text()").toString());
}
public Site getSite() {
return Site.me().setSleepTime(100).setRetryTimes(3);
}
public static void main(String[] args) {
Spider.create( new MyProcessor()
).addUrl("https://blog.csdn.net/nav/ai").run();
}
}
2.3 Pipeline
2.3.1 ConsolePipeline 控制檯輸出
北京市昌平區建材城西路金燕龍辦公樓一層 電話:400-618-9090
/**
* 爬取類
*/
public class MyProcessor implements PageProcessor {
public void process(Page page) {
//page.addTargetRequests( page.getHtml().links().all() );//將當前頁
面裡的所有連結都新增到目標頁面中
//
page.addTargetRequests(
page.getHtml().links().regex("https://blog.csdn.net/[a‐z 0‐9
‐]+/article/details/[0‐9]{8}").all() );
//System.out.println(page.getHtml().xpath("//* [@id=\"mainBox\"]/main/div[1]/div[1]/h1/text()").toString()); page.putField("title",page.getHtml().xpath("//* [@id=\"mainBox\"]/main/div[1]/div[1]/h1/text()").toString());
}
public Site getSite() {
return Site.me().setSleepTime(100).setRetryTimes(3);
}
public static void main(String[] args) { Spider.create( new MyProcessor() )
.addUrl("https://blog.csdn.net")
.addPipeline(new ConsolePipeline())
.run();
}
}
2.3.2 FilePipeline 檔案儲存
public static void main(String[] args) { Spider.create( new MyProcessor() )
.addUrl("https://blog.csdn.net")
.addPipeline(new ConsolePipeline())
.addPipeline(new FilePipeline("e:/data"))//以檔案方式儲存
.run();
}
北京市昌平區建材城西路金燕龍辦公樓一層 電話:400-618-9090
2.3.3 JsonFilePipeline
以json方式儲存
public static void main(String[] args) { Spider.create( new MyProcessor() )
.addUrl("https://blog.csdn.net")
.addPipeline(new ConsolePipeline())
.addPipeline(new FilePipeline("e:/data"))
.addPipeline(new JsonFilePipeline("e:/json"))// 以json方式保
存
.run();
}
2.3.4 定製Pipeline
如果以上Pipeline都不能滿足你的需要,你可以定製Pipeline(1)建立類MyPipeline實現介面Pipeline
package cn.itcast.demo;
import us.codecraft.webmagic.ResultItems; import us.codecraft.webmagic.Task;
import us.codecraft.webmagic.pipeline.Pipeline;
public class MyPipeline implements Pipeline {
public void process(ResultItems resultItems, Task task) {
String title=resultItems.get("title");
System.out.println("我的定製的 title:"+title);
}
}
(2)修改main方法
北京市昌平區建材城西路金燕龍辦公樓一層 電話:400-618-9090
public static void main(String[] args) { Spider.create( new MyProcessor() )
.addUrl("https://blog.csdn.net")
.addPipeline(new ConsolePipeline())
.addPipeline(new FilePipeline("e:/data"))
.addPipeline(new JsonFilePipeline("e:/json"))
.addPipeline(new MyPipeline())//定製化輸出
.run();
}
2.4 Scheduler
我們剛才完成的功能,每次執行可能會爬取重複的頁面,這樣做是沒有任何意義的。Scheduler(URL管理) 最基本的功能是實現對已經爬取的URL進行標示。可以實現URL的增量去重。
目前scheduler主要有三種實現方式:
1)記憶體佇列 QueueScheduler
2)檔案佇列 FileCacheQueueScheduler
3) Redis佇列 RedisScheduler
2.4.1 記憶體佇列
使用setScheduler來設定Scheduler
public static void main(String[] args) { Spider.create( new MyProcessor() )
.addUrl("https://blog.csdn.net")
.setScheduler(new QueueScheduler())
.run();
}
2.4.2 檔案佇列
使用檔案儲存抓取URL,可以在關閉程式並下次啟動時,從之前抓取到的URL繼續抓取(1)建立資料夾E:\scheduler
北京市昌平區建材城西路金燕龍辦公樓一層 電話:400-618-9090
(2)修改程式碼
public static void main(String[] args) { Spider.create( new MyProcessor() )
.addUrl("https://blog.csdn.net") //.setScheduler(new QueueScheduler())//設定記憶體佇列
.setScheduler(new
FileCacheQueueScheduler("E:\\scheduler"))//設定檔案佇列
.run();
}
執行後文件夾E:\scheduler會產生兩個檔案blog.csdn.net.urls.txt和 blog.csdn.net.cursor.txt
2.4.3 Redis佇列
使用Redis儲存抓取佇列,可進行多臺機器同時合作抓取
(1)執行redis服務端
(2)修改程式碼
public static void main(String[] args) { Spider.create( new MyProcessor() )
.addUrl("https://blog.csdn.net") //.setScheduler(new QueueScheduler())//設定記憶體佇列 //.setScheduler(new
FileCacheQueueScheduler("E:\\scheduler"))//設定檔案佇列
.setScheduler(new RedisScheduler("127.0.0.1"))//設定Redis隊
列
.run();
}
3 十次方文章爬取
3.1 需求分析
每日某時間段整從CSDN播客中爬取文件,存入文章資料庫中。
3.2 頻道設定
北京市昌平區建材城西路金燕龍辦公樓一層 電話:400-618-9090
| 頻道名稱 |
地址 |
|||||||
|
|
|
|
|
|
|
|
|
|
| 資訊 |
||||||||
|
|
|
|
|
|
|
|
|
|
| 人工智慧 |
||||||||
|
|
|
|
|
|
|
|
|
|
| 區塊鏈 |
||||||||
|
|
|
|
|
|
|
|
|
|
| 資料庫 |
||||||||
|
|
|
|
|
|
|
|
|
|
| 前端 |
||||||||
|
|
|
|
|
|
|
|
|
|
| 程式語言 |
||||||||
|
|
|
|
|
|
|
|
|
|
向資料庫tensquare_article的tb_channel表中新增記錄
3.3 程式碼編寫
3.3.1 模組搭建
(1)建立模組tensquare_article_crawler ,引入依賴
北京市昌平區建材城西路金燕龍辦公樓一層 電話:400-618-9090