
機器學習 -- 分類
1. 樸素貝葉斯
貝葉斯決策理論方法是統計模型決策中的一個基本方法,基本思想如下:
(1) 已知類條件概率密度引數表示式和先驗概率
(2) 利用貝葉斯公式轉換成後驗概率
(3) 根據後驗概率大小進行決策分類。
貝葉斯概率研究的是條件概率,也就是研究的場景是在帶有某些前提條件下,或者在某些背景條件的約束下發生的概率問題。貝葉斯公式:
設 D1、D2、...、Dn 為樣本空間 S 的一個劃分,如果以 P(Di) 表示 Di 發生的概率,且 P(Di)
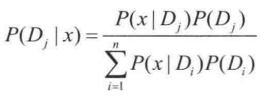
解釋: 在一個樣本空間裡有很多事件發生, Di 就是指不同的事件劃分,並且用 Di 可以把整個空間劃分完畢,在每個 Di 事件發生的同時都記錄事件 x 的發生, 並記錄 Di 事件發生下 x 發生的概率。 等式右側的分母部分就是 Di 發生的概率和 Di 發生時 x 發生的概率的加和, 所以分母這一項其實就是在整個樣本空間裡 x 發生的概率。 

也就是說在,在全樣本空間下,發生 x 的概率乘以在發生 x 的情況下發生 Dj 的概率,等於發生 Dj 的概率乘以在發生 Dj 的情況下發生 x 的概率。
貝葉斯分類器通常是基於這樣一個假定: 給定目標值時屬性之間相互條件獨立。
舉例: 假設某商品只有甲,乙,丙三家,市場佔有率分別為 30%, 20%, 50%,他們次品率分別為 3%, 4%, 1%。上面的 x 就是指商品是次品這個事件。 指的就是商品是次品時,生產廠家是甲或乙或丙(也就是D1, D2, D3)的概率。
問題一: 購買此商品是次品的概率是多少?
此處就是求次品的全概率 = 30%*3% + 20%*4% + 50%*%1 這個全概率就是第一個公式中的分母。
問題二: 購買的商品是次品,求生產廠家分別是甲或乙或丙的概率?
利用第一個公式可得: 甲的概率 = 50%*1/全概率
2. 決策樹歸納
比較好理解,如下圖所示:
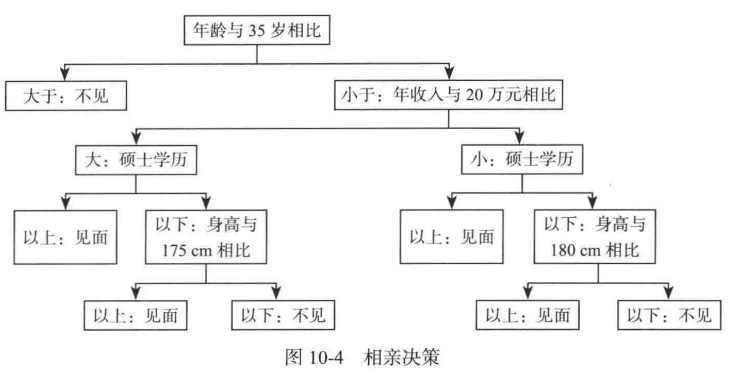
歸納過程:
(1) 樣本收集。
以相親為例,收集一個人看到各種條件的人後做出是否相親的選擇。這些資料為樣本資料。
(2) 資訊增益
整個樣本的熵的計算如下(得出的值也叫期望資訊):

m 的數量就是最後分類(決策)的種類,這個例子裡 m 就是 2 --- 要麼見面,要麼不見。 pi 指的是這個決策項產生的概率。本例中有兩個決策項,其概率就是兩個決策項分別在結果集中出現的概率。
上面是以 “年齡與35歲相比”做為決策樹的根,這是怎麼得來的呢? 其實我們需要對樣本資料用不同的欄位(如身高,學歷)來劃分, 在這種劃分規則下的熵為:

其中 v 表示一共劃分為多少組。比如:如果以學歷來劃分並且有三種學歷,則 v 就是3,pj 表示這種分組產生的概率,也可以認為是一種權重。 Info(Aj) 是在當前分組狀態下的期望資訊值。
用總體樣本的期望資訊減去以學歷作為根計算出來的期望資訊,就是資訊增益。應該嘗試其它欄位做為根時的資訊增益。資訊增益越大,說明劃分越有效。
注:需要對每個欄位做計算以求得出較好的決策樹模型,比較複雜。
3. 隨機森林
隨機森林演算法會構造好棵樹。當有新樣本需要進行分類時,同時把這個樣本給這幾棵樹,然後用類似民主投票表決的方式來決定新樣本應該歸屬於哪類,哪一類得票多就歸為哪一類。構建步驟:
(1) 隨機挑選一個欄位構造樹的第一層,
(2) 隨機挑選一個欄位構造樹的第二層;
。。。
(3) 隨機挑選一個欄位構造樹的第n層;
(4) 在本棵樹建造完畢後,還需要照這種方式建造 m 棵決策樹。
4. 隱馬爾可夫模型(Hidden Markov Model -- HMM)
馬爾可夫鏈的核心是:在給定當前知識或資訊的情況下,觀察物件過去的歷史狀態對於預測將來是無關的。
假設有三種骰子(6面,4面,8面),隨機抽一個骰子,擲出一個數字並記錄。迴圈多次後,會得到一串數字。在隱馬爾可夫模型中,不僅僅有這麼一串可見狀態鏈,還有一串隱含狀態鏈,就是選出的骰子的序列。
一般來說, HMM 中的馬爾可夫鏈其實就是指隱含狀態鏈,因為實際是隱含狀態(所選骰子)之間存在轉換概率。
和 HMM 模型相關的演算法主要分為3類,分別解決3種問題:
(1) 知道骰子有幾種(隱含狀態數量),每種骰子是什麼(轉換概率),根據擲骰子擲出的結果(可見狀態鏈),想知道每次擲出來的都是哪種骰子(隱含狀態鏈)。
這個問題在語音識別領域叫做解碼問題。這個問題其實有兩種解法。一種解法求最大似然狀態路徑。通俗地說就是求一串骰子序列,這串骰子序列產生觀測結果的概率最大。第二種解法是求每次擲出的骰子分別是某種骰子的概率。
(2) 知道骰子有幾種(隱含狀態數量),每種骰子是什麼(轉換概率),根據擲骰子擲出的結果(可見狀態鏈),想知道擲出這個結果的概率。
這個問題的目的其實是檢測觀察到的結果和已知的模型是否吻合。如果很多次結果都對應了比較小的概率,那麼就說明已知的模型很有可能是錯的。
(3) 知道骰子有幾種(隱含狀態數量),不知道每種骰子是什麼(轉換概率),觀測多次擲骰子的結果(可見狀態鏈),想反推出每種骰子是什麼(轉換概率)。
5. SVM(支援向量機)
支援向量機。樣本中含N 個維度,當無法在 N 維空間上劃分這些樣本時,可以通過升維的方式,使得 N 維空間上的分類邊界是 N + 1 維上的分類函式在 N 維空間上的投影。
使用核函式(Kernel) 進行構造高維的函式,常用的核函式是可以拿來直接使用的。如線性核函式、多項式核函式、徑向基核函式(RBF核函式)、高斯核函式等。
SVM 解決問題的方法大概有以下幾步:
(1) 把所有的樣本和其對應的分類標記交給演算法進行訓練
(2) 如果發現線性可分,就直接找出超平面
(3) 如果發現線性不可分,那就對映到 n + 1維空間, 找出超平面
(4) 最後得到超平面的表示式,也就是分類函式
6. 遺傳演算法
遺傳演算法是處理問題的一種思想。以 0-1 揹包問題為例,假設有6個物品(物品很少,可以用窮舉法,這裡僅作為說明),以下為大概的步驟
(1) 基因編碼。 取某一物品的話,就標為1,不取就標為0
(2) 設計初始群體。 可以設計隨機生成4個初始生物個體,假設隨機的4個基因序列為: 101101, 011001, 100100, 110010
(3) 適應度計算。首先要用一個適應度的函式來做標尺。
此例適應度函式為物品的總價值。淘汰總質量不符全要求的。假設剩下的基因為前3個,各個基因的總價值分別為 62, 85, 103,其和為 62+85+103= 250,根據各自總價值所佔的比例(即 62/250, 85/250, 103/250), 利用類似輪船堵來選擇哪幾個基因可以產生下一代。
(4) 產生下一代。上面得出的基因中,以某個位置為交叉點,進行基因重組。即一個基因在交叉點的前半段與另一個基因在交叉點的後半段組成一個新的基因。這樣就組成了新的一代
(5) 迭代計算。 重複(3),(4)。如果發現連續幾代適應度基本不增加甚至減少,則說明函式已經收斂了。則基本為我們所求的值。注意這個解並不一定是最優解。
遺傳演算法的注意事項:
(1) 初始群體的數量。 初始數量太少可能會導致在向量空間中覆蓋面積過小而導致收斂琶了非最優解就終止了演算法。
(2) 適應度函式。上面的輪盤賭演算法只是一種演算法。需要注意的是,淘汰比較弱的基因是可以的,但是不建議淘汰的比例太大。
(3) 基因重組。這個環節是變數比較大的。斷開的位置幾乎是可以隨意進行的。