
均值漂移聚類
均值漂移聚類是基於滑動視窗的演算法,它試圖找到資料點的密集區域。這是一個基於質心的演算法,這意味著它的目標是定位每個組/類的中心點,通過將中心點的候選點更新為滑動視窗內點的均值來完成。然後,在後處理階段對這些候選視窗進行過濾以消除近似重複,形成最終的中心點集及其相應的組。請看下面的圖例。
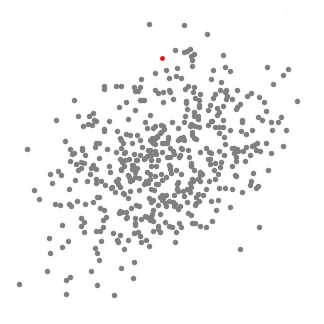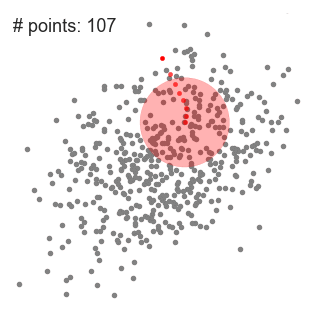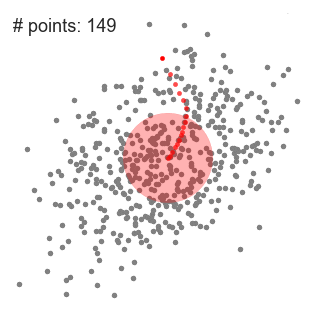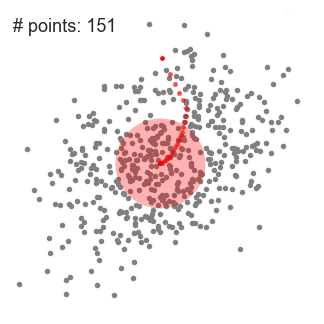
均值漂移聚類用於單個滑動視窗
為了解釋均值漂移,我們將考慮二維空間中的一組點,如上圖所示。
1.我們從一個以 C 點(隨機選擇)為中心,以半徑 r 為核心的圓形滑動視窗開始。均值漂移是一種爬山演算法,它包括在每一步中迭代地向更高密度區域移動,直到收斂。
2.在每次迭代中,滑動視窗通過將中心點移向視窗內點的均值(因此而得名)來移向更高密度區域。滑動視窗內的密度與其內部點的數量成正比。自然地,通過向視窗內點的均值移動,它會逐漸移向點密度更高的區域。
3.我們繼續按照均值移動滑動視窗直到沒有方向在核內可以容納更多的點。請看上面的圖;我們一直移動這個圓直到密度不再增加(即視窗中的點數)。
4.步驟 1 到 3 的過程是通過許多滑動視窗完成的,直到所有的點位於一個視窗內。當多個滑動視窗重疊時,保留包含最多點的視窗。然後根據資料點所在的滑動視窗進行聚類。
下面顯示了所有滑動視窗從頭到尾的整個過程。每個黑點代表滑動視窗的質心,每個灰點代表一個數據點。

均值漂移聚類的整個過程
與 K-means 聚類相比,這種方法不需要選擇簇數量,因為均值漂移自動發現這一點。這是一個巨大的優勢。聚類中心朝最大點密度聚集的事實也是非常令人滿意的,因為理解和適應自然資料驅動的意義是非常直觀的。它的缺點是視窗大小/半徑「r」的選擇很重要。
其中起始點的個數可以為所有樣本、隨機抽樣也可以通過一定方法(粗粒度分割槽抽樣)選擇;距離的度量可以直接使用歐式距離等也可以引入核函式;找到中心後可以使用k-means或者依據之前的對映關係分配到相關的聚類中心。
思考:
1.找中心的過程可以使用faiss庫進行加速,並且不適用平均值而是使用中位數可能更符合朝向密度最大方向去得過程。