
「mysql優化專題」90%程式設計師都會忽略的增刪改優化(2)
前文一篇「mysql優化專題」這大概是一篇最好的mysql優化入門文章(1)讓大家知道msql優化,究竟在優化什麼,本篇為mysql優化專題的第二篇,主要先從增刪改進行優化。
補充知識點:操作資料語句優化的認識
通常情況下,當訪問某張表的時候,讀取者首先必須獲取該表的鎖,如果有寫入操作到達,那麼寫入者一直等待讀取者完成操作(查詢開始之後就不能中斷,因此允許讀取者完成操作)。當讀取者完成對錶的操作的時候,鎖就會被解除。如果寫入者正在等待的時候,另一個讀取操作到達了,該讀取操作也會被阻塞(block),因為預設的排程策略是寫入者優先於讀取者。當第一個讀取者完成操作並解放鎖後,寫入者開始操作,並且直到該寫入者完成操作,第二個讀取者才開始操作。因此:要提高MySQL的更新/插入效率,應首先考慮降低鎖的競爭,減少寫操作的等待時間。 (本專題在後面會討論表設計的優化)本篇,要講的優化是增刪改。
一、INSERT語句:
基本:INSERT [INTO] 表名 [(欄位列表)] VALUES (值列表)[, (值列表), …]
注意:
如果要插入的值列表包含所有欄位並且順序一致,則可以省略欄位列表。
可同時插入多條資料記錄!
REPLACE 與 INSERT 完全一樣,可互換。
優化前例子:

優化策略:
(1)當我們需要批量插入資料的時候,這樣的語句卻會出現效能問題。例如說,如果有需要插入100000條資料,那麼就需要有100000條insert語句,每一句都需要提交到關係引擎那裡去解析,優化,然後才能夠到達儲存引擎做真的插入工作。上述所說的同時插入多條就是一種優化。(經測試,大概10條同時插入是最高效的)
優化後例子:

(2)將程序/執行緒數控制在2倍於CPU數目相對合適
(3)採用順序主鍵策略(例如自增主鍵,或者修改業務邏輯,讓插入的記錄儘可能順序主鍵)
(4)考慮使用replace 語句代替insert語句。(REPLACE語句請參考下文,有詳細講述)
二、DELETE語句:
DELETE FROM 表名[ 刪除條件子句](沒有條件子句,則會刪除全部)
例子:
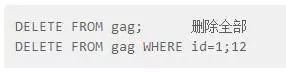
補充:Mysql中的truncate table和delete語句都可以刪除表裡面所有資料,但是在一些情況下有些不同!
例子:
truncate table gag;
(1)truncate table刪除速度更快,但truncate table刪除後不記錄mysql日誌,不可以恢復資料。(謹慎使用)
(2)如果沒有外來鍵關聯,innodb執行truncate是先drop table(原始表),再建立一個跟原始表一樣空表,速度要遠遠快於delete逐條刪除行記錄。(思考:刪除百萬級資料的時候是否可用truncate table)
(3)如果使用innodb_file_per_table引數,truncate table 能重新利用釋放的硬碟空間,在InnoDB Plugin中,truncate table為自動回收,如果不是用InnoDB Plugin,那麼需要使用optimize table來優化表,釋放空間。
truncate table刪除表後,optimize table尤其重要,特別是大資料資料庫,表空間可以得到釋放!
(4)表有外來鍵關聯,truncate table刪除表資料為逐行刪除,如果外來鍵指定級聯刪除(delete cascade),關聯的子表也會被刪除所有表資料。如果外來鍵未指定級聯(cascde),truncate table逐行刪除資料,如果是父行關聯子錶行資料,將會報錯。
注意:
一個大的 DELETE 或 INSERT 操作,要非常小心,因為這兩個操作是會鎖表的,表一鎖住,其他操作就進不來了。因此,我們要交給DBA去拆分,重整資料庫策略,比如限制處理1000條。
另外,擴充套件下刪除和索引的聯絡(關於索引優化,後面的查詢優化也會講解),由於索引需要額外的維護成本;因為索引檔案是單獨存在的檔案,所以當我們對資料的增加,修改,刪除,都會產生額外的對索引檔案的操作,這些操作需要消耗額外的IO,會降低增/改/刪的執行效率。所以,在我們刪除資料庫百萬級別資料的時候,查詢MySQL官方手冊得知刪除資料的速度和建立的索引數量是成正比的。所以我們想要刪除百萬資料的時候可以先刪除索引(此時大概耗時三分多鐘),然後刪除其中無用資料,此過程需要不到兩分鐘,刪除完成後重新建立索引(此時資料較少了)建立索引也非常快,約十分鐘左右。與之前的直接刪除絕對是要快速很多,更別說萬一刪除中斷,一切刪除會回滾。那更是坑了。
三、UPDATE語句:
UPDATE 表名 SET 欄位名=新值[, 欄位名=新值] [更新條件]
例子:

優化:更新多條記錄(往後會結合MyBatis寫個例項)

更新多條記錄的多個值
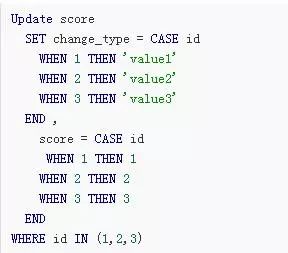
(1). 儘量不要修改主鍵欄位。(廢話,反正我就從沒改過..)
(2). 當修改VARCHAR型欄位時,儘量使用相同長度內容的值代替。
(3). 儘量最小化對於含有UPDATE觸發器的表的UPDATE操作。
(4). 避免UPDATE將要複製到其他資料庫的列。
(5). 避免UPDATE建有很多索引的列。
(6). 避免UPDATE在WHERE子句條件中的列。
四、REPLACE語句:
根據應用情況可以使用replace 語句代替insert/update語句。例如:如果一個表在一個欄位上建立了唯一索引,當向這個表中使用已經存在的鍵值插入一條記錄,將會丟擲一個主鍵衝突的錯誤。如果我們想用新記錄的值來覆蓋原來的記錄值時,就可以使用REPLACE語句。
使用REPLACE插入記錄時,如果記錄不重複(或往表裡插新記錄),REPLACE功能與INSERT一樣,如果存在重複記錄,REPLACE就使用新記錄的值來替換原來的記錄值。使用REPLACE的最大好處就是可以將DELETE和INSERT合二為一,形成一個原子操作。這樣就可以不必考慮同時使用DELETE和INSERT時新增事務等複雜操作了。
在使用REPLACE時,表中必須有唯一有一個PRIMARY KEY或UNIQUE索引,否則,使用一個REPLACE語句沒有意義。
用法:
(1)同INSERT
含義一:與普通INSERT一樣功能
REPLACE INTO score (change_type,score,user_id) VALUES ('吃飯',10,1),('喝茶',10,1),('喝茶',10,1);
含義二:找到第一條記錄,用後面的值進行替換
REPLACE INTO score (id,change_type,score,user_id) VALUES (1,'吃飯',10,1)
此語句的作用是向表table中插入3條記錄。如果主鍵id為1或2不存在就相當於插入語句:
INSERT INTO score (change_type,score,user_id) VALUES (‘吃飯’,10,1),(‘喝茶’,10,1),(‘喝茶’,10,1);
如果存在相同的值則不會插入資料。
(2)replace(object, search, replace),把object中出現search的全部替換為replace。
用法一:並不是修改資料,而只是單純做區域性替換資料返還而已。
SELECT REPLACE('喝茶','茶','喝')//結果: 喝喝123
用法二:修改表資料啦,對應下面就是,根據change_type欄位找到做任務的資料,用bb來替換
UPDATE score SET change_type=REPLACE(change_type,'做任務','bb')1
在此,做下對比:UPDATE和REPLACE的區別:
1)UPDATE在沒有匹配記錄時什麼都不做,而REPLACE在有重複記錄時更新,在沒有重複記錄時插入。
2)UPDATE可以選擇性地更新記錄的一部分欄位。而REPLACE在發現有重複記錄時就將這條記錄徹底刪除,再插入新的記錄。也就是說,將所有的欄位都更新了。
其實REPLACE更像INSERT與DELETE的結合。
結尾
今天mysql優化的增刪改優化就講到這裡,覺得有收穫的朋友可以收藏關注,下兩篇為查詢部分的優化。大家可以關注一波。