
徹底搞懂Scrapy的中介軟體(三)
在前面兩篇文章介紹了下載器中介軟體的使用,這篇文章將會介紹爬蟲中介軟體(Spider Middleware)的使用。
爬蟲中介軟體
爬蟲中介軟體的用法與下載器中介軟體非常相似,只是它們的作用物件不同。下載器中介軟體的作用物件是請求request和返回response;爬蟲中介軟體的作用物件是爬蟲,更具體地來說,就是寫在spiders資料夾下面的各個檔案。它們的關係,在Scrapy的資料流圖上可以很好地區分開來,如下圖所示。
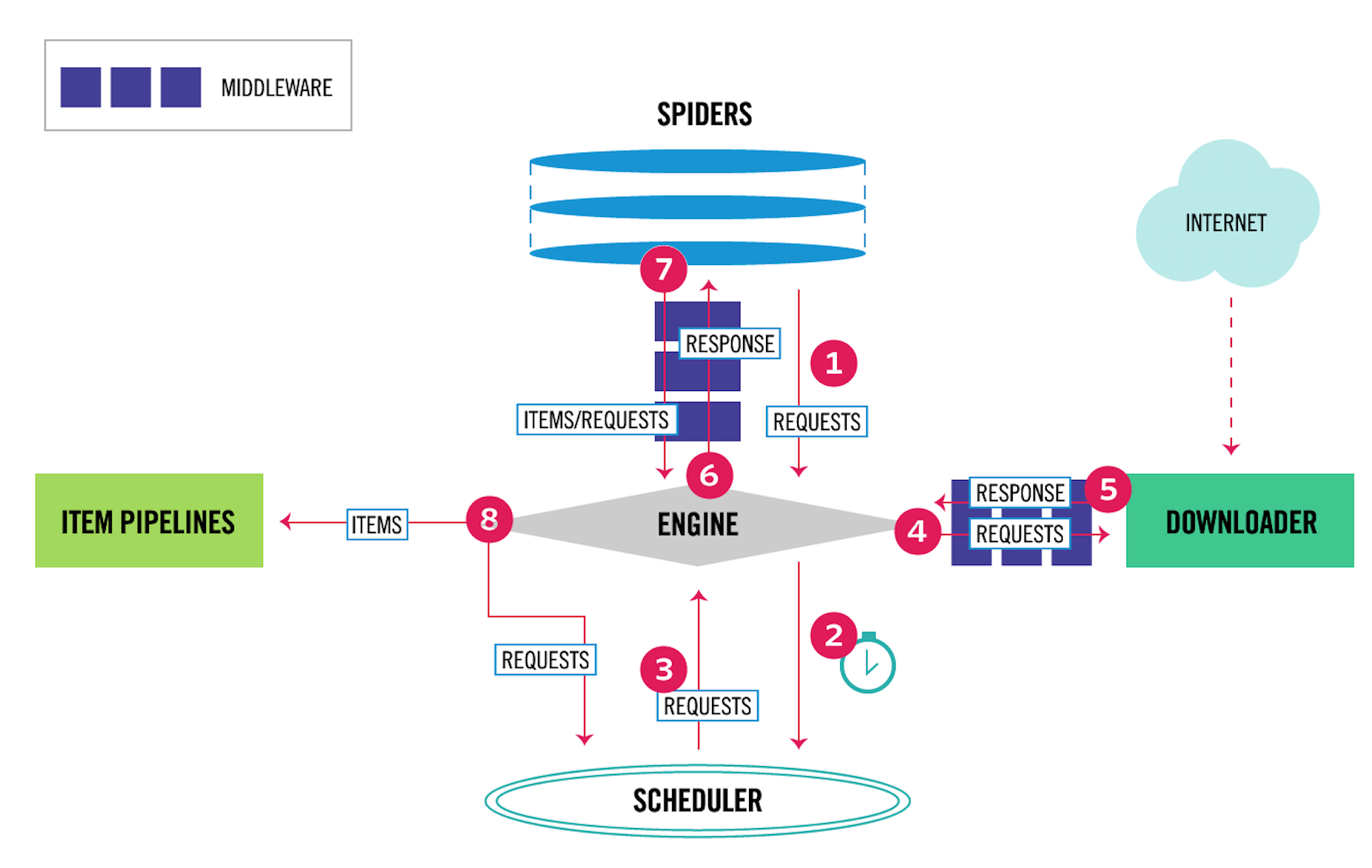
其中,4、5表示下載器中介軟體,6、7表示爬蟲中介軟體。爬蟲中介軟體會在以下幾種情況被呼叫。
- 當執行到
yield scrapy.Request()或者yield item的時候,爬蟲中介軟體的process_spider_output()方法被呼叫。 - 當爬蟲本身的程式碼出現了
Exception的時候,爬蟲中介軟體的process_spider_exception()方法被呼叫。 - 當爬蟲裡面的某一個回撥函式
parse_xxx()被呼叫之前,爬蟲中介軟體的process_spider_input()方法被呼叫。 - 當執行到
start_requests()的時候,爬蟲中介軟體的process_start_requests()方法被呼叫。
在中介軟體處理爬蟲本身的異常
在爬蟲中介軟體裡面可以處理爬蟲本身的異常。例如編寫一個爬蟲,爬取UA練習頁面http://exercise.kingname.info/exercise_middleware_ua
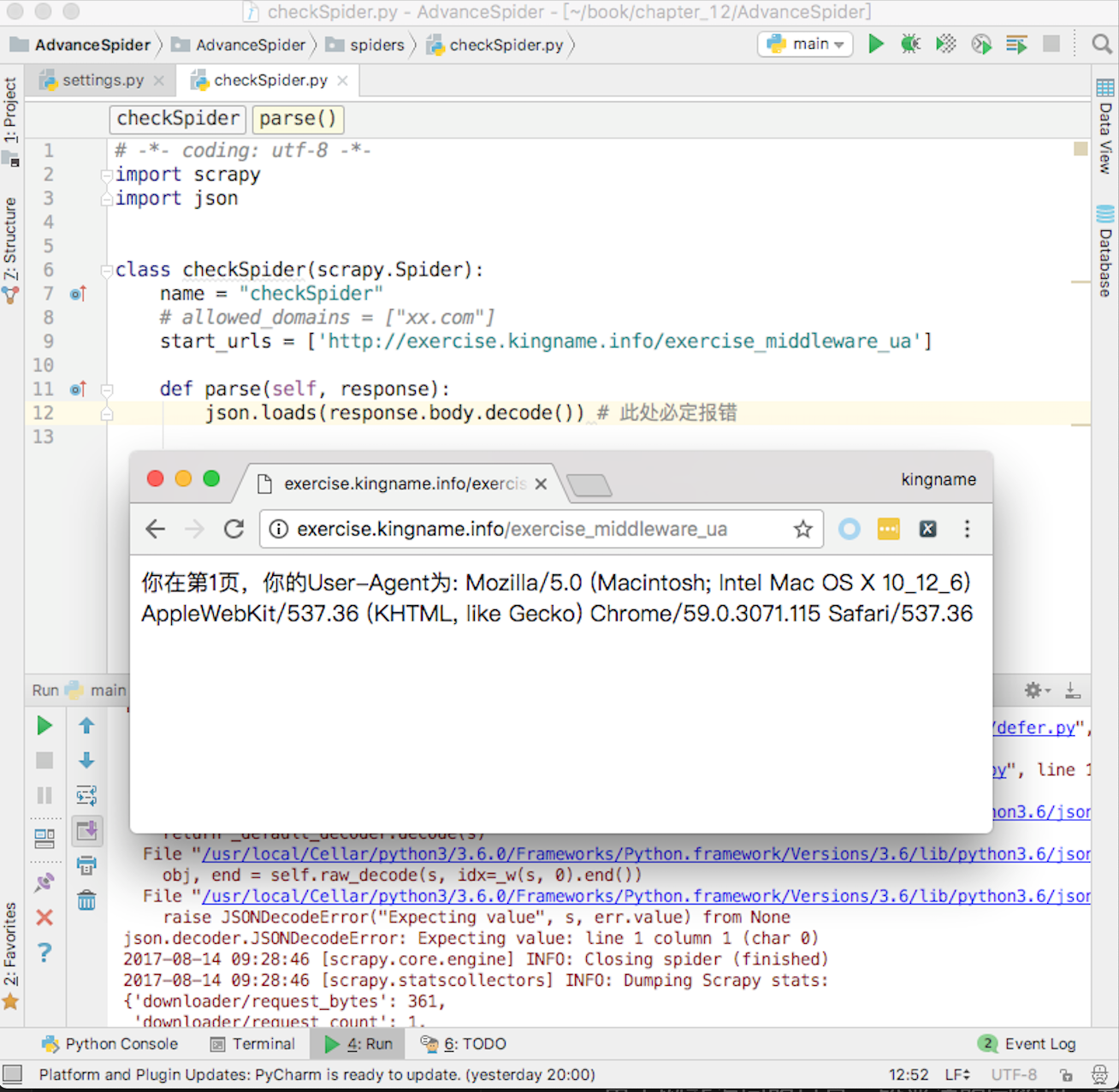
由於網站返回的只是一段普通的字串,並不是JSON格式的字串,因此使用JSON去解析,就一定會導致報錯。這種報錯和下載器中介軟體裡面遇到的報錯不一樣。下載器中介軟體裡面的報錯一般是由於外部原因引起的,和程式碼層面無關。而現在的這種報錯是由於程式碼本身的問題導致的,是程式碼寫得不夠周全引起的。
為了解決這個問題,除了仔細檢查程式碼、考慮各種情況外,還可以通過開發爬蟲中介軟體來跳過或者處理這種報錯。在middlewares.py中編寫一個類:
class ExceptionCheckSpider(object): def process_spider_exception(self, response, exception, spider): print(f'返回的內容是:{response.body.decode()}\n報錯原因:{type(exception)}') return None
這個類僅僅起到記錄Log的作用。在使用JSON解析網站返回內容出錯的時候,將網站返回的內容打印出來。
process_spider_exception()這個方法,它可以返回None,也可以執行yield item語句或者像爬蟲的程式碼一樣,使用yield scrapy.Request()發起新的請求。如果運行了yield item或者yield scrapy.Request(),程式就會繞過爬蟲裡面原有的程式碼。
例如,對於有異常的請求,不需要進行重試,但是需要記錄是哪一個請求出現了異常,此時就可以在爬蟲中介軟體裡面檢測異常,然後生成一個只包含標記的item。還是以抓取http://exercise.kingname.info/exercise_middleware_retry.html這個練習頁的內容為例,但是這一次不進行重試,只記錄哪一頁出現了問題。先看爬蟲的程式碼,這一次在meta中把頁數帶上,如下圖所示。

爬蟲裡面如果發現了引數錯誤,就使用raise這個關鍵字人工丟擲一個自定義的異常。在實際爬蟲開發中,讀者也可以在某些地方故意不使用try ... except捕獲異常,而是讓異常直接丟擲。例如XPath匹配處理的結果,直接讀裡面的值,不用先判斷列表是否為空。這樣如果列表為空,就會被丟擲一個IndexError,於是就能讓爬蟲的流程進入到爬蟲中介軟體的process_spider_exception()中。
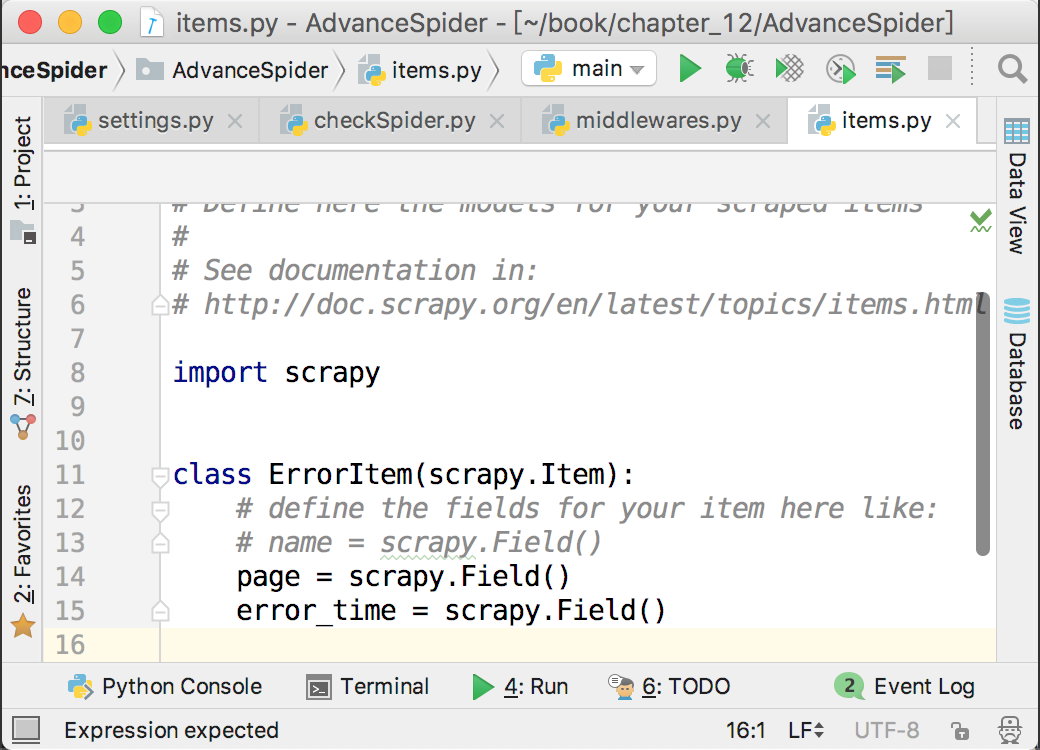
在items.py裡面建立了一個ErrorItem來記錄哪一頁出現了問題,如下圖所示。
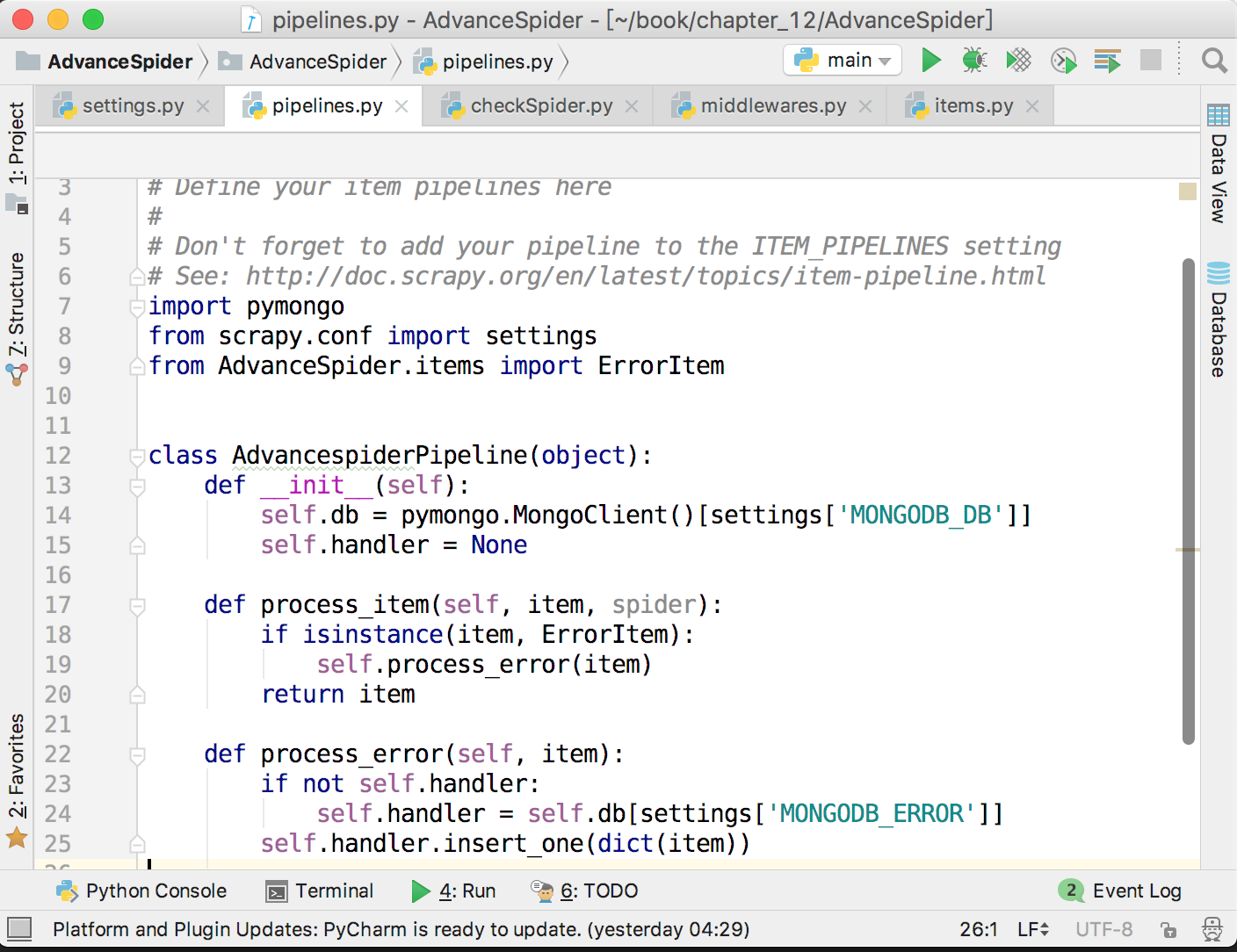
接下來,在爬蟲中介軟體中將出錯的頁面和當前時間存放到ErrorItem裡面,並提交給pipeline,儲存到MongoDB中,如下圖所示。
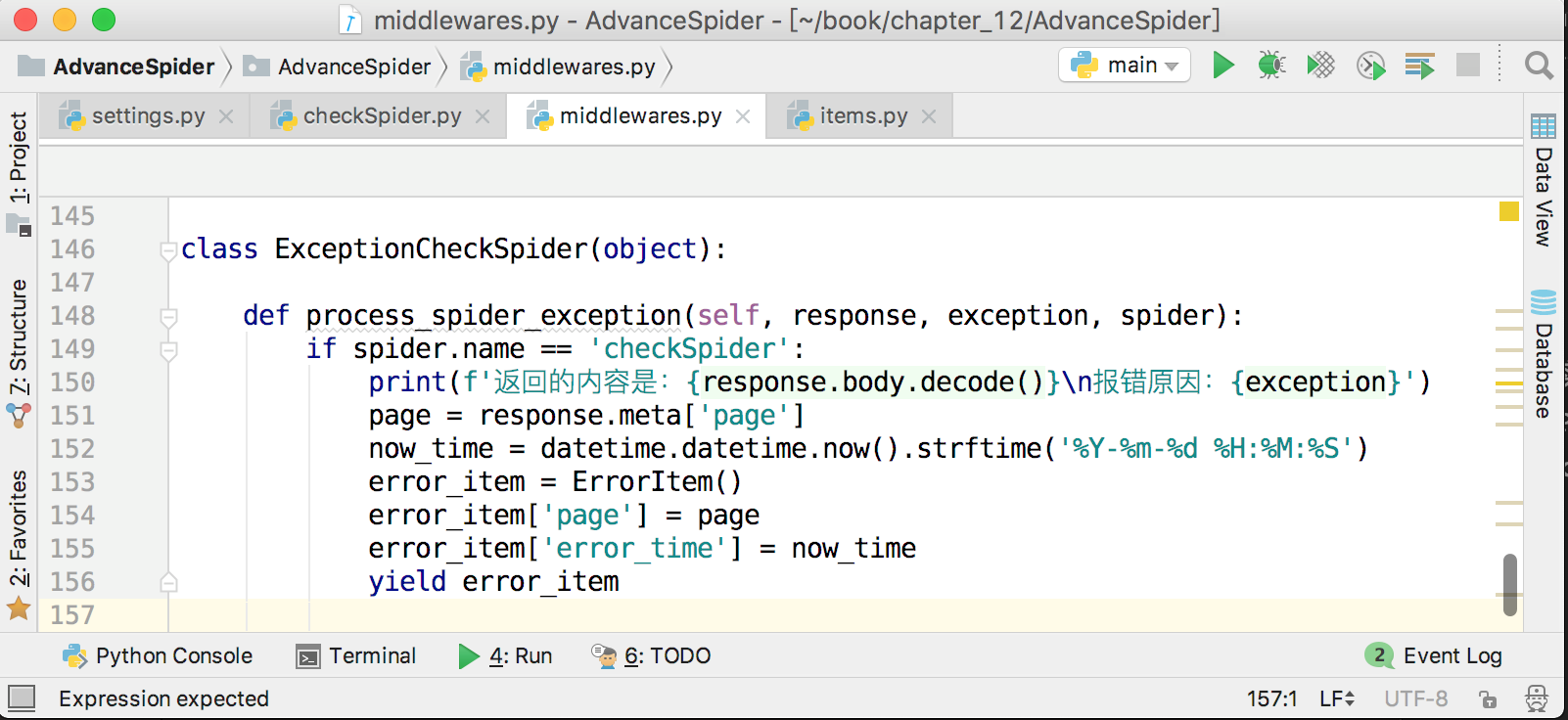
這樣就實現了記錄錯誤頁數的功能,方便在後面對錯誤原因進行分析。由於這裡會把item提交給pipeline,所以不要忘記在settings.py裡面開啟pipeline,並配置好MongoDB。儲存錯誤頁數到MongoDB的程式碼如下圖所示。
啟用爬蟲中介軟體
爬蟲中介軟體的啟用方式與下載器中介軟體非常相似,在settings.py中,在下載器中介軟體配置項的上面就是爬蟲中介軟體的配置項,它預設也是被註釋了的,解除註釋,並把自定義的爬蟲中介軟體新增進去即可,如下圖所示。
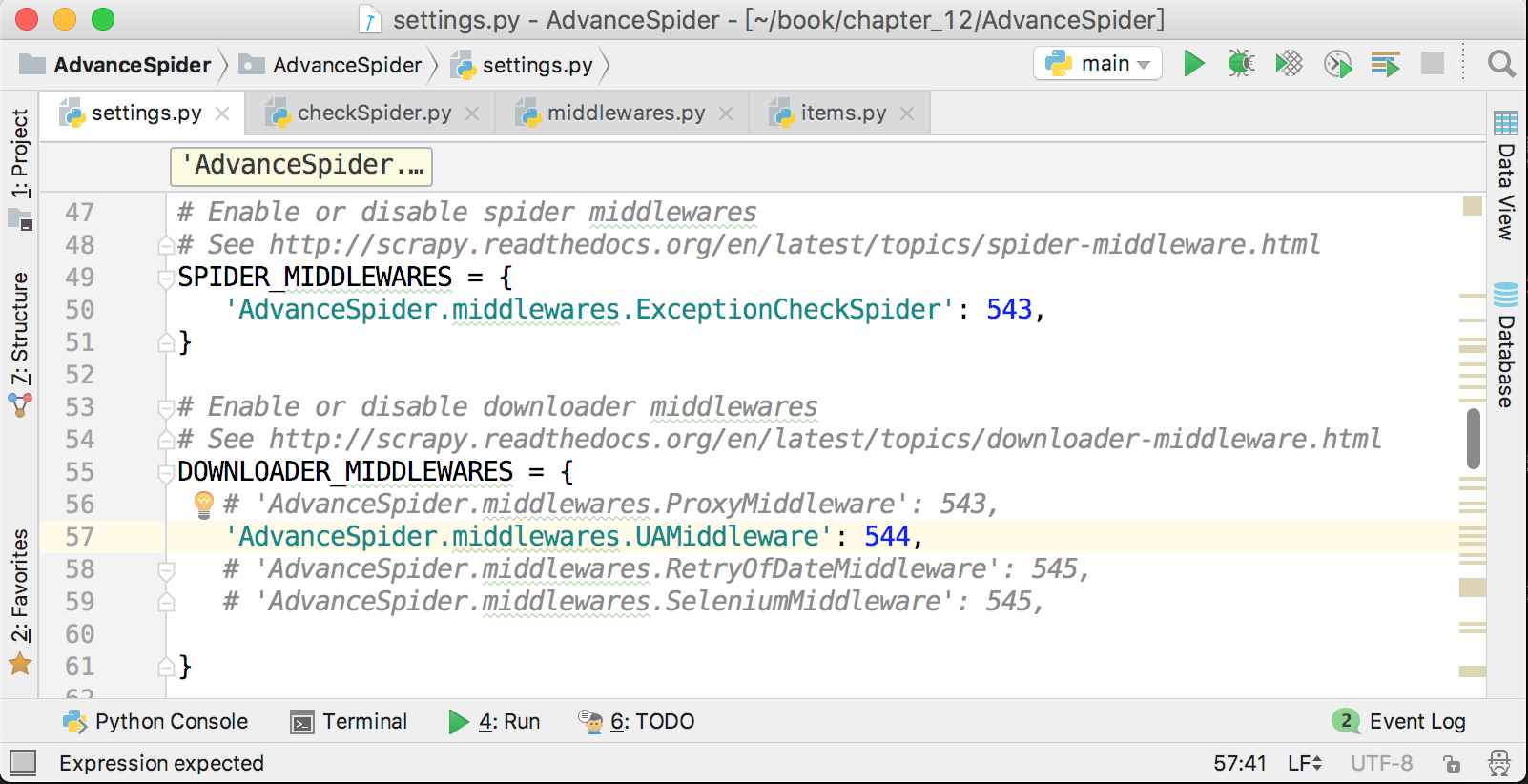
Scrapy也有幾個自帶的爬蟲中介軟體,它們的名字和順序如下圖所示。

下載器中介軟體的數字越小越接近Scrapy引擎,數字越大越接近爬蟲。如果不能確定自己的自定義中介軟體應該靠近哪個方向,那麼就在500~700之間選擇最為妥當。
爬蟲中介軟體輸入/輸出
在爬蟲中介軟體裡面還有兩個不太常用的方法,分別為process_spider_input(response, spider)和process_spider_output(response, result, spider)。其中,process_spider_input(response, spider)在下載器中介軟體處理完成後,馬上要進入某個回撥函式parse_xxx()前呼叫。process_spider_output(response, result, output)是在爬蟲執行yield item或者yield scrapy.Request()的時候呼叫。在這個方法處理完成以後,資料如果是item,就會被交給pipeline;如果是請求,就會被交給排程器,然後下載器中介軟體才會開始執行。所以在這個方法裡面可以進一步對item或者請求做一些修改。這個方法的引數result就是爬蟲爬出來的item或者scrapy.Request()。由於yield得到的是一個生成器,生成器是可以迭代的,所以result也是可以迭代的,可以使用for迴圈來把它展開。
def process_spider_output(response, result, spider):
for item in result:
if isinstance(item, scrapy.Item):
# 這裡可以對即將被提交給pipeline的item進行各種操作
print(f'item將會被提交給pipeline')
yield item或者對請求進行監控和修改:
def process_spider_output(response, result, spider):
for request in result:
if not isinstance(request, scrapy.Item):
# 這裡可以對請求進行各種修改
print('現在還可以對請求物件進行修改。。。。')
request.meta['request_start_time'] = time.time()
yield request本文節選自我的新書《Python爬蟲開發 從入門到實戰》完整目錄可以在京東查詢到 https://item.jd.com/12436581.html