
文件識別&深度學習OCR
最近人工智慧太火了,大家都在說什麼Deeplearning、神經網路、深度學習,各行各業都搞起了這方面的業務,誠然,深度學習確實有很大的技術改進優勢,但是也不是馬上就能秒殺一切傳統的技術的。針對於圖片文字識別OCR這方面,我想跟大家探討幾個方面的問題。
首先我要跟大家說明的是:我不是技術開發人員,對各種OCR演算法有一些基礎認識,但瞭解內容有限,我僅僅是針對目前遇到的一些現狀,並結合實際場景應用,與大家做個分享與討論,有不當之處,大家可以留言或者聯絡我進行交流溝通。
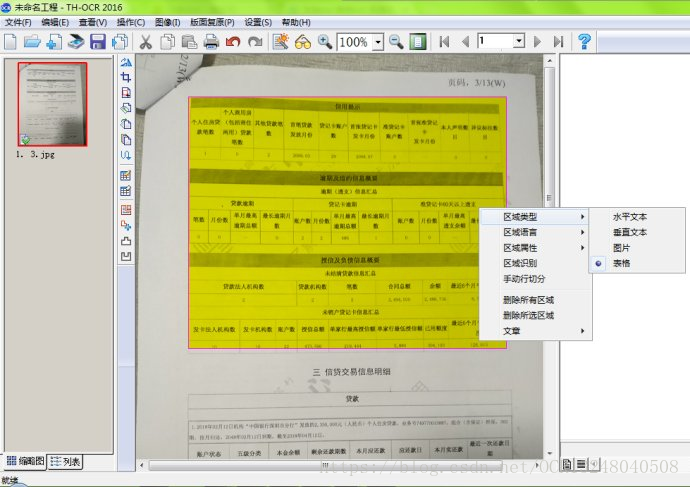
首先我這邊要說的是傳統的的文件OCR文字識別技術,他是有對圖片上的內容進行認識分析的過程,其中比較重要的就是有個四要素,橫排文字、豎排文字、表格、配圖;每一個人們寫的材料,文章等檔案中都是由這四個基本要素組成。
在傳統的文件OCR識別技術中,演算法會先分析圖片中有幾個佈局區域,然後分析出水平橫向文字,豎向垂直文字,表格和配圖照片等區域,然後在針對各自的特點進行切分字元,保留區域型別,進行OCR識別調整;所以可以適應各種型別的文字識別。有些小角度的傾斜文字,OCR程式也可以進行智慧調整識別;
深度學習的OCR技術是最近一年興起來的,這個技術的抗干擾能力很強,可以識別比較複雜背景情況下的圖片,但是現在的深度OCR識別技術並沒有專門的公司去做深度研究和技術演練,目前的情況是可以很好地輸出“行文字資訊”以及“列文字資訊”,所以如果想用深度學習的OCR技術去處理文件資料的話,會很不合適!
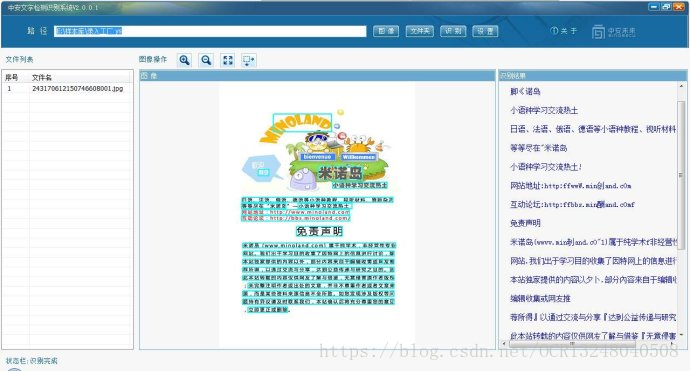
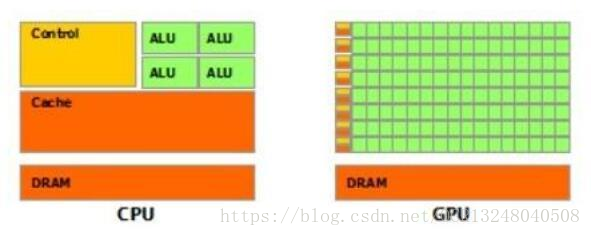
但是如果用來處理各種非文件型別的,場景照片中文字,廣告海報中的文字,那麼深度學習技術的OCR程式就會很有優勢,如果您想做這方面的技術應用,就需要配備一臺顯示卡比較牛的伺服器,因為深度學習的技術跑的是GPU,對顯示卡的等級要求很高,不像跑CPU的傳統OCR文字識別技術。
好了,先討論分享這麼多,大家還有什麼想了解的,可以與我溝通!