
對抗樣本機器學習_Note1_機器學習
轉載自:https://yq.aliyun.com/ziliao/292780
機器學習方法,如SVM,神經網路等,雖然在如影象分類等問題上已經outperform人類對同類問題的處理能力,但是也有其固有的缺陷,即我們的訓練集喂的都是natural input,因此在正常情況下處理的比較好。然而如果我們想要對ML模型進行攻擊的話,可以通過一定的手段生成對抗樣本(adversarial examples),以影象為例,對抗樣本在每個畫素點只有微小的擾動(pertubations),因此對於人類的眼睛是無法分辨的,即生成前後我們人類還會將其歸為同一類別。然而ML模型在面對這些對抗樣本時會出現不魯棒的特點,對它們會產生錯分。對抗樣本生成的基本思路是:在訓練模型的過程中,我們把輸入固定去調整引數,使得最後的結果能對應到相應的輸入;而生成對抗樣本時,我們將模型固定,通過調整輸入,觀察在哪個特徵方向上只需要微小的擾動即可使得我們的模型給出我們想要的錯分的分類結果。研究對抗樣本機器學習的目的就是,希望我們的模型對於對抗樣本更加robust。
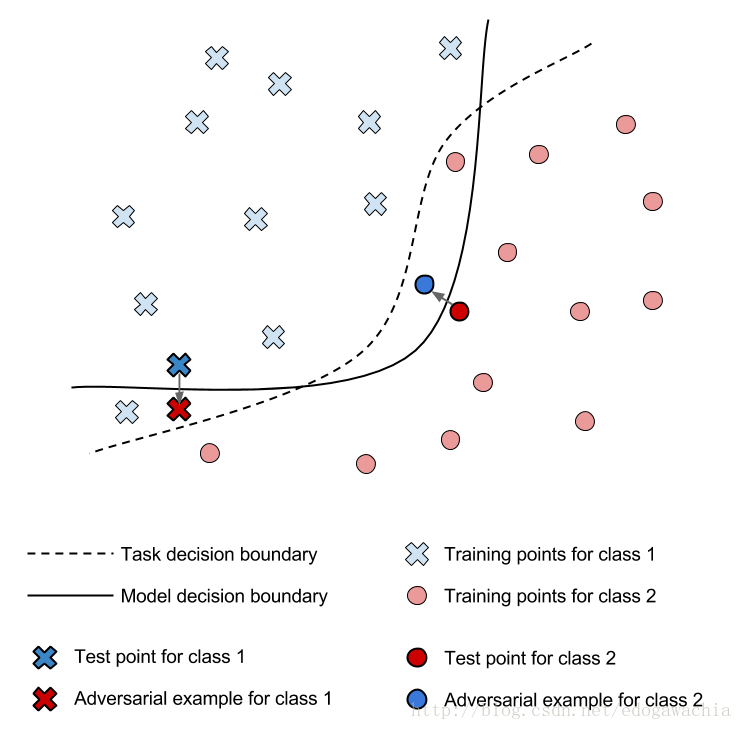
上圖可以說明對抗樣本是如何工作的。Model decision boundary 是我們訓練的模型的分類邊界,這個邊界可以較好的將兩類樣本分開,但是如果我們對標出來的兩個Test point 做一個微小的擾動,即可使其越過邊界產生misclassification,因此我們的Task decision boundary就應當將這些對抗樣本也分到其原本的類別。
對於這個問題,與普遍的安全問題類似,我們一般考慮兩種角度,即attack和defense。其中attack試圖更好的生成對抗樣本以便使得分類結果符合attacker自己的預期;defense希望通過提高模型的魯棒性,從而對這些adversarial examples 不敏感,從而抵禦攻擊。常見的attack方法,即生成對抗樣本的方法有 fast gradient sign method (FGSM)和 Jacobian-based saliency map approach(JSMA)。如下圖,生成的對抗樣本中的擾動對人類視覺來說不敏感,但是對於ML模型來說,原本以57.7percent的概率被判成熊貓的圖片在修改後以99.3的概率被判成了長臂猿。

對於defense,常見的方法有:
Adversarial training:該方法思路非常平凡,即在訓練網路的過程中,對每個圖片都生成一些對抗樣本,然後給他們與原圖相同的標籤餵給網路訓練,從而使得網路相對來說對於對抗樣本更魯棒一些。開源的cleverhans即為用FGSM或JSMA生成對抗樣本進行對抗訓練的一個library。
Defensive distillation:該方法用來smooth對抗樣本進行擾動的方向的decision surface,Distillation(勉強譯為 蒸餾。) 是Hinton大神提出來的一種用來使得小模型可以模仿大模型的方法,基本思路為,我們在訓練分類模型的時候,輸出來的時one-hot的向量,這種叫做hard label,用hard label對一個模型進行訓練後,我們不僅僅保留softmax之後最大的概率的那一個維度,而是將整個概率向量作為label(小編個人感覺和label smoothing的思路有點像),這叫做soft label, 這樣來說,每個輸入樣本不僅僅只有一個資訊量較小的(因為對於分類結果太過確定,即該圖片確定為該類別,其他類別完全無關)one-hot的向量,而是一個對每個類別都有一定概率的vector。這樣由於訓練網路,就會得到一些附加資訊,如有一張圖片可能在某兩類之間比較難以分別,這樣它們就會有較高的概率,這樣的label實際上附帶了大模型訓練得到的資訊,因此可以提高小模型的效果。(flag:以上為個人理解,之後閱讀Hinton的參考論文)所謂的Defensive distillation即先訓練用硬標籤一個網路,然後得到軟標籤,並訓練另一個網路(蒸餾網路),用蒸餾過的網路去分類就會對adversarial更加魯棒。
一個失敗的defense案例是 gradient masking,即直接輸出類別而不是概率,使得沒法通過gradient微小擾動影象,但是通過訓練一個有gradient 的網路,在此基礎上擾動,也可以attack經過該方法defense過的網路。
上圖說明,即使defense使得gradient被掩蓋,但是我們可以訓練替代模型用來生成對抗樣本。
相對於attack,機器學習的defense更難一些。因為缺少較好的theoratical model 來說明某種方法可以將某類對抗樣本排除出去。
對於設計一個穩定可靠的系統來說,需要有testing和verification,所謂testing是指,在若干不同的條件下評估該系統,觀察其在這些條件下的表現;而verification是指,給出一個有說服裡的理由證明該系統在broad range of circumstances下都不會misbehave。僅僅testing是不夠的,因為testing只給出了系統的失敗率的一個下界,但是為了安全防護的目的,我們需要知道失敗率的上界。但是對於機器學習的verification沒法對對抗樣本有一個guarantee,因此還很不完善。
reference:
cleverhans-blog : http://www.cleverhans.io/