
TB級Elasticsearch全文檢索優化研究
阿新 • • 發佈:2018-11-21
TB級Elasticsearch全文檢索優化研究
背景
今年工作的一個重點是“新技術新模式”的匯入和研究。Elasticsearch技術比較火,各專案和產品用的都也比較多。其中某團隊遇到一個問題:“在TB級的資料量下進行全文檢索時,ES叢集檢索響應速度比較慢”。雖然由於各種原因沒有接觸到系統,沒有看到程式碼,甚至都沒見到具體現象,但是任務分配下來了,就要有結果就要出方案。“沒吃過豬肉,也得先見見豬跑”,先在一個30GB級別的ES叢集下做一下優化研究。
全文檢索的原理
- 全文檢索的定義
全文檢索和普通查詢最大的區別是,全文檢索判斷的是“相關度”,普通查詢判斷是“是與非”。比如在全文檢索裡搜尋“我愛你”,除了返回包含“我愛你”的文件,可能還會返回“我不愛你”、“我喜歡你”、“我中意你”、“我愛她” 等文件。相關度越高,也就是得分越高的文件越在前面。 - 檢索流程
全文檢索的基本流程可以分為兩部分,“存”和“取”。“存”部分就是將輸入的“字串”,經過分析器,切分成多個“詞”,將這些“詞”儲存到倒排索引中。“取”部分就是將使用者搜尋的"字串",使用相同的分析器,切分成多個“詞”,在倒排索引中檢索是否包含這些“詞”,包含就將這些詞對應的文件返回。
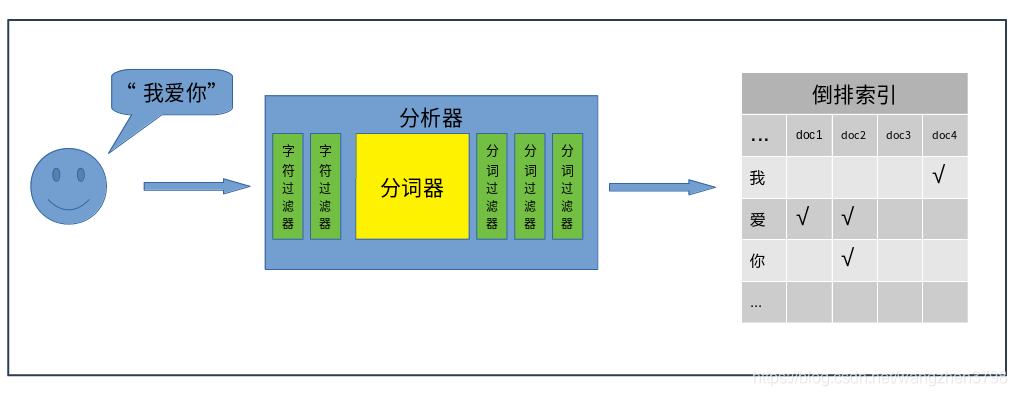
- 分析器
在整個全文檢索過程中,分析器扮演著非常重要的角色,ES提供的有內建的分析器,社群也提供各種分詞外掛(如中文的ik分析器)。分析器由以下幾個元件構成:字元過濾器(char filters)
主要職責是在分詞器前過濾字元流,在源字元流中新增、刪除、替換字元。一個分析器中可以有0個或多個字元過濾器。主要包括:html char filter、mapping char filter等。分詞器
主要職責是將接收到的字元流,按照某些規則切分成若干個“詞”,並記錄這些“詞”在源字串中的位置。比如將“我愛你”切分成"我"、“愛”、“你”、“我愛”,“愛你”,“我愛你”等等。分析器中有且只能有一個分詞器。分詞過濾器
主要職責是將分好的“詞”進行某種規則的過濾,可以新增、移除、替換“詞”,但是不能修改“詞”在源字串中的相對位置。一個分析器中可以有0個或多個分詞過濾器。常用的分詞過濾器包括:大小寫轉換過濾器、停用詞過濾器、同義詞過濾器、拼音過濾器 等等
一個分析器可以有字元過濾器、分詞器、分詞過濾器自由組合,形成新的自定義的分析器。
推理總結
- 全文檢索本質上是精確匹配。如果某分析器將“我愛你”切分成了“我愛”和“愛你”兩個詞。那麼直接搜尋“愛”,是查不到任何文件的。
- 全文檢索本質上是預先處理的檢索。分析器將所有可能被檢索的“詞”都預先建立了索引。理論上不能搜尋沒有被檢索的詞(或者檢索時會出現很低的效能)。
- 高頻詞會影響檢索的效能。比如1000萬文件,900萬都包含“愛”字。那麼檢索“愛”字時就會把900萬文件都查出來,然後計算出“愛”在每份文件的得分,返回得分最高的文件。
- 分析器會增加索引空間大小。比如某分詞器將“我愛你”切分成"我"、“愛”、“你”、“我愛”,“愛你”,“我愛你”,要比切分成"我愛你"一個詞的空間大N倍。
- 全文檢索本質上是精確匹配