
java之collection總結
https://www.cnblogs.com/taiwan/p/6954135.html
Collection
來源於Java.util包,是非常實用常用的資料結構!!!!!字面意思就是容器。具體的繼承實現關係如下圖,先整體有個印象,再依次介紹各個部分的方法,注意事項,以及應用場景。
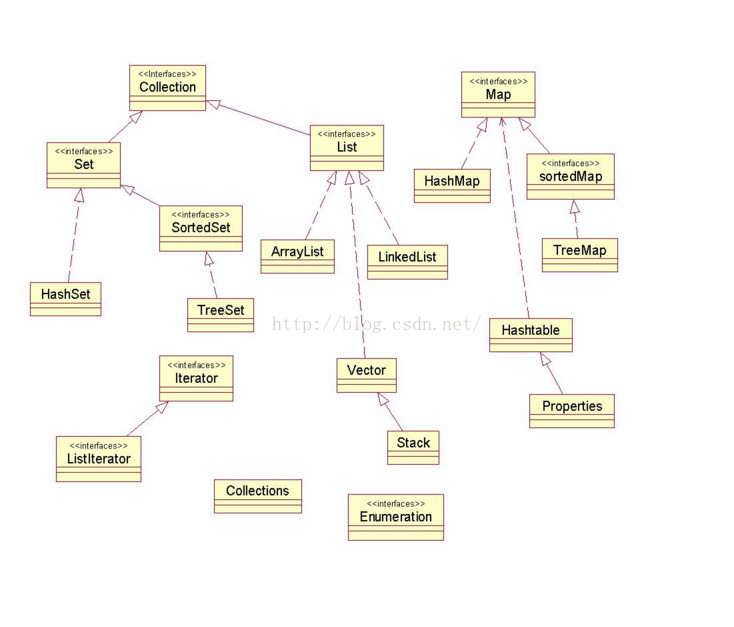
--------------------------------------------------------------------------------------------
collection主要方法:
boolean add(Object o)新增物件到集合
boolean remove(Object o)刪除指定的物件
int size()返回當前集合中元素的數量
boolean contains(Object o)查詢集合中是否有指定的物件
boolean isEmpty()判斷集合是否為空
Iterator iterator()返回一個迭代器
boolean containsAll(Collection c)查詢集合中是否有集合c中的元素
boolean addAll(Collection c)將集合c中所有的元素新增給該集合
void clear()刪除集合中所有元素
void removeAll(Collection c)從集合中刪除c集合中也有的元素
void retainAll(Collection c)從集合中刪除集合c中不包含的元素
--------------------------------------------------------------------------------------------
collection主要子介面物件:
├List(抽象介面,可重複有序)
list主要方法:
void add(int index,Object element)在指定位置上新增一個物件
boolean addAll(int index,Collection c)將集合c的元素新增到指定的位置
Object get(int index)返回List中指定位置的元素
int indexOf(Object o)返回第一個出現元素o的位置.
Object remove(int index)刪除指定位置的元素
Object set(int index,Object element)用元素element取代位置index上的元素,返回被取代的元素
void sort()
--------------------------------------------------------------------------------------------
1.List主要子介面物件
│├LinkedList沒有同步方法
│├ArrayList非同步的(unsynchronized)
│└Vector(同步) 非常類似ArrayList,但是Vector是同步的
└Stack 記住 push和pop方法,還有peek方法得到棧頂的元素,empty方法測試堆疊是否為空,search方法檢測一個元素在堆疊中的位置。注意:Stack剛建立後是空棧。
--------------------------------------------------------------------------------------------
2.└Set不包含重複的元素
HashSet
SortSet
TreeSet
另外:-Queue(繼承collection)---Deque
--------------------------------------------------------------------------------------------
3.Map
Map沒有繼承Collection介面,Map提供key到value的對映。
方法:
boolean equals(Object o)比較物件
boolean remove(Object o)刪除一個物件
put(Object key,Object value)新增key和value
├Hashtable 任何非空(non-null)的物件。同步的
├HashMap 可空的物件。不同步的 ,但是效率高,較常用。 注:迭代子操作時間開銷和HashMap的容量成比例。因此,如果迭代操作的效能相當重要的話,不要將HashMap的初始化容量設得過高,或者load factor過低。
└WeakHashMap 改進的HashMap,它對key實行“弱引用”,如果一個key不再被外部所引用,那麼該key可以被GC回收。
SortMap---TreeMap
4.總結:
a.如果涉及到堆疊,佇列(先進後出)等操作,應該考慮用List,對於需要快速插入,刪除元素,應該使用LinkedList,如果需要快速隨機訪問元素,應該使用ArrayList。
b.如果程式在單執行緒環境中,或者訪問僅僅在一個執行緒中進行,考慮非同步的類,其效率較高,如果多個執行緒可能同時操作一個類,應該使用同步的類。
c.要特別注意對雜湊表的操作,作為key的物件要正確複寫equals和hashCode方法。
d.儘量返回介面而非實際的型別,如返回List而非ArrayList,這樣如果以後需要將ArrayList換成LinkedList時,客戶端程式碼不用改變。這就是針對抽象程式設計。
e.ArrayList、HashSet/LinkedHashSet、PriorityQueue、LinkedList是執行緒不安全的,
可以使用synchronized關鍵字,或者類似下面的方法解決:
[java] view plain copy
- List list = Collections.synchronizedList(new ArrayList(...));
5.幾個面試常見問題:
1.Q:ArrayList和Vector有什麼區別?HashMap和HashTable有什麼區別?
A:Vector和HashTable是執行緒同步的(synchronized)。效能上,ArrayList和HashMap分別比Vector和Hashtable要好。
2.Q:大致講解java集合的體系結構
A:List、Set、Map是這個集合體系中最主要的三個介面。
其中List和Set繼承自Collection介面。
Set不允許元素重複。HashSet和TreeSet是兩個主要的實現類。
List有序且允許元素重複。ArrayList、LinkedList和Vector是三個主要的實現類。
Map也屬於集合系統,但和Collection介面不同。Map是key對value的對映集合,其中key列就是一個集合。key不能重複,但是value可以重複。HashMap、TreeMap和Hashtable是三個主要的實現類。
SortedSet和SortedMap介面對元素按指定規則排序,SortedMap是對key列進行排序。
3.Q:Comparable和Comparator區別
A:呼叫java.util.Collections.sort(List list)方法來進行排序的時候,List內的Object都必須實現了Comparable介面。
java.util.Collections.sort(List list,Comparator c),可以臨時宣告一個Comparator 來實現排序。
[java] view plain copy
- Collections.sort(imageList, new Comparator() {
- public int compare(Object a, Object b) {
- int orderA = Integer.parseInt( ( (Image) a).getSequence());
- int orderB = Integer.parseInt( ( (Image) b).getSequence());
- return orderA - orderB;
- }
- });
如果需要改變排列順序
改成return orderb - orderA 即可。
6.其他注意點
List介面對Collection進行了簡單的擴充,它的具體實現類常用的有ArrayList和LinkedList。你可以將任何東西放到一個List容器中,並在需要時從中取出。ArrayList從其命名中可以看出它是一種類似陣列的形式進行儲存,因此它的隨機訪問速度極快,而LinkedList的內部實現是連結串列,它適合於在連結串列中間需要頻繁進行插入和刪除操作。在具體應用時可以根據需要自由選擇。前面說的Iterator只能對容器進行向前遍歷,而ListIterator則繼承了Iterator的思想,並提供了對List進行雙向遍歷的方法。
Set介面也是Collection的一種擴充套件,而與List不同的時,在Set中的物件元素不能重複,也就是說你不能把同樣的東西兩次放入同一個Set容器中。它的常用具體實現有HashSet和TreeSet類。HashSet能快速定位一個元素,但是你放到HashSet中的物件需要實現hashCode()方法,它使用了前面說過的雜湊碼的演算法。而TreeSet則將放入其中的元素按序存放,這就要求你放入其中的物件是可排序的,這就用到了集合框架提供的另外兩個實用類Comparable和Comparator。一個類是可排序的,它就應該實現Comparable介面。有時多個類具有相同的排序演算法,那就不需要在每分別重複定義相同的排序演算法,只要實現Comparator介面即可。集合框架中還有兩個很實用的公用類:Collections和Arrays。Collections提供了對一個Collection容器進行諸如排序、複製、查詢和填充等一些非常有用的方法,Arrays則是對一個數組進行類似的操作。
Map是一種把鍵物件和值物件進行關聯的容器,而一個值物件又可以是一個Map,依次類推,這樣就可形成一個多級對映。對於鍵物件來說,像Set一樣,一個Map容器中的鍵物件不允許重複,這是為了保持查詢結果的一致性;如果有兩個鍵物件一樣,那你想得到那個鍵物件所對應的值物件時就有問題了,可能你得到的並不是你想的那個值物件,結果會造成混亂,所以鍵的唯一性很重要,也是符合集合的性質的。當然在使用過程中,某個鍵所對應的值物件可能會發生變化,這時會按照最後一次修改的值物件與鍵對應。對於值物件則沒有唯一性的要求。你可以將任意多個鍵都對映到一個值物件上,這不會發生任何問題(不過對你的使用卻可能會造成不便,你不知道你得到的到底是那一個鍵所對應的值物件)。Map有兩種比較常用的實現:HashMap和TreeMap。HashMap也用到了雜湊碼的演算法,以便快速查詢一個鍵,TreeMap則是對鍵按序存放,因此它便有一些擴充套件的方法,比如firstKey(),lastKey()等,你還可以從TreeMap中指定一個範圍以取得其子Map。鍵和值的關聯很簡單,用pub(Object key,Object value)方法即可將一個鍵與一個值物件相關聯。用get(Object key)可得到與此key物件所對應的值物件。
遍歷Map的方式:
a.//最常規的一種遍歷方法,最常規就是最常用的,雖然不復雜,但很重要,這是我們最熟悉的,就不多說了!!
[java] view plain copy
- public static void work(Map<String, Student> map) {
- Collection<Student> c = map.values();
- Iterator it = c.iterator();
- for (; it.hasNext();) {
- System.out.println(it.next());
- }
- }
b.// 利用keyset進行遍歷,它的優點在於可以根據你所想要的key值得到你想要的 values,更具靈活性!!
[java] view plain copy
- public static void workByKeySet(Map<String, Student> map) {
- Set<String> key = map.keySet();
- for (Iterator it = key.iterator(); it.hasNext();) {
- String s = (String) it.next();
- System.out.println(map.get(s));
- }
- }
c.// 比較複雜的一種遍歷在這裡,暴力!!,它的靈活性太強了,想得到什麼就能得到什麼~~
[java] view plain copy
- public static void workByEntry(Map<String, Student> map) {
- Set<Map.Entry<String, Student>> set = map.entrySet();
- for (Iterator<Map.Entry<String, Student>> it = set.iterator(); it
- .hasNext();) {
- Map.Entry<String, Student> entry = (Map.Entry<String, Student>) it
- .next();
- System.out.println(entry.getKey() + "—>" + entry.getValue());
- }
- }
d.//Map.Entry的另外一種簡練寫法(foreach遍歷方式)
[java] view plain copy
- public static void workByEntry(Map<String, Student> map) {
- Set<Map.Entry<String, Student>> set = map.entrySet();
- for (Map.Entry<String, Student> me : set) {
- System.out.println(me.getKey() + "—>" + me.getValue());
- }
- }
7.Queue
Queue和List有兩個區別:
前者有“隊頭”的概念,取元素、移除元素、均為對“隊頭”的操作(通常但不總是FIFO,即先進先出),
而後者只有在插入時需要保證在尾部進行;前者對元素的一些同一種操作提供了兩種方法,在特定情況下拋異常/返回特殊值——add()/offer()、remove()/poll()、element()/peek()。不難想到,在所謂的兩種方法中,拋異常的方法完全可以通過包裝不拋異常的方法來實現,這也是AbstractQueue所做的。
Deque介面繼承了Queue,但是和AbstractQueue沒有關係。Deque同時提供了在隊頭和隊尾進行插入和刪除的操作。
PriorityQueue
PriorityQueue用於存放含有優先順序的元素,插入的物件必須可以比較。該類內部同樣封裝了一個數組。與其抽象父類AbstractQueue不同,PriorityQueue的offer()方法在插入null時會拋空指標異常——null是無法與其他元素比較通常意義下的優先順序的;此外,add()方法是直接包裝了offer(),沒有附加的行為。
由於其內部的資料結構是陣列的緣故,很多操作都需要先把元素通過indexOf()轉化成對應的陣列下標,再進行進一步的操作,如remove()、removeEq()、contains()等。其實這個陣列保持優先順序佇列的方式,是採用堆(Heap)的方式,具體可以參考任意一本演算法書籍,比如《演算法導論》等,這裡就不展開解釋了。和堆的特性有關,在尋找指定元素時,必須從頭至尾遍歷,而不能使用二分查詢。
LinkedList
LinkedList既是List,也是Queue(Deque),其原因是它是雙向的,內部的元素(Entry)同時保留了上一個和下一個元素的引用。使用頭部的引用header,取其previous,就可以獲得尾部的引用。通過這一轉換,可以很容易實現Deque所需要的行為。也正因此,可以支援棧的行為,天生就有push()和pop()方法。簡而言之,是Java中的雙向連結串列,其支援的操作和普通的雙向連結串列一樣。
和陣列不同,根據下標查詢特定元素時,只能遍歷地獲取了,因而在隨機訪問時效率不如ArrayList。儘管如此,作者還是儘可能地利用了LinkedList的特性做了點優化,儘量減少了訪問次數:
[java] view plain copy
- private Entry<E> entry(int index) {
- if (index < 0 || index >= size)
- throw new IndexOutOfBoundsException("Index: "+index+
- ", Size: "+size);
- Entry<E> e = header;
- if (index < (size >> 1)) {
- for (int i = 0; i <= index; i++)
- e = e.next;
- } else {
- for (int i = size; i > index; i--)
- e = e.previous;
- }
- return e;
- }
LinkedList對首部和尾部的插入都支援,但繼承自Collection介面的add()方法是在尾部進行插入。