
memcached的學習(10)
2018.6.14
講解Memcached如何從客戶端讀取命令,並且解析命令,然後處理命令並且向客戶端迴應訊息。其中,Memcached是通過sendmsg函式向客戶端傳送資料的,這裡我們具體分析Memcached迴應訊息的技術細節。
右邊對應了響應客戶端需要準備好傳送的資料結構,值得注意的是每次傳送的是一個msghrd的結構體指向的快取空間。這是一種多緩衝技術,也就是和之前我們說的傳送緩衝區是不一樣的概念。
傳統的傳送緩衝區,就是一個緩衝區,一次性將緩衝區的資料都發送出去,一般需要預設定一段大的buff,這樣的效率很低,有可能緩衝區也會滿,導致資料的丟失。所以unix提出了一種新的iovec多緩衝區的技術,具體如下:
I/O vector,與readv和wirtev操作相關的結構體。readv和writev函式用於在一次函式呼叫中讀、寫多個非連續緩衝區。有時也將這兩個函式稱為散佈讀(scatter read)和聚集寫(gather write)。
顧名思義,就是可以指定多個緩衝區進行一次性發送,這樣的好處是,解放了緩衝區預設的限制,同時減少了系統的呼叫。
和以前方法比的優缺點:
通常的情況下,程式可能會在多個地方產生不同的buffer,如 nginx,第一個phase裡都可能會產生buffer,放進一個chain裡,
如果對每個buffer呼叫一次send,系統呼叫的個數將直接等於buffer的個數,對於多buffer的情況會很糟。
可能大家會想到重新分配一個大的buffer, 再把資料全部填充進去,這樣其實只用了一次系統呼叫了。又或者在一開始就預先分配一塊足夠大的記憶體。
這兩種情況是能滿足要求,不過都不足取,前一種會浪費記憶體,後一種方法對phase的獨立性有影響。
那麼在memcached中是如何利用這種多緩衝技術的呢?
Memcached訊息迴應原始碼分析
資料結構
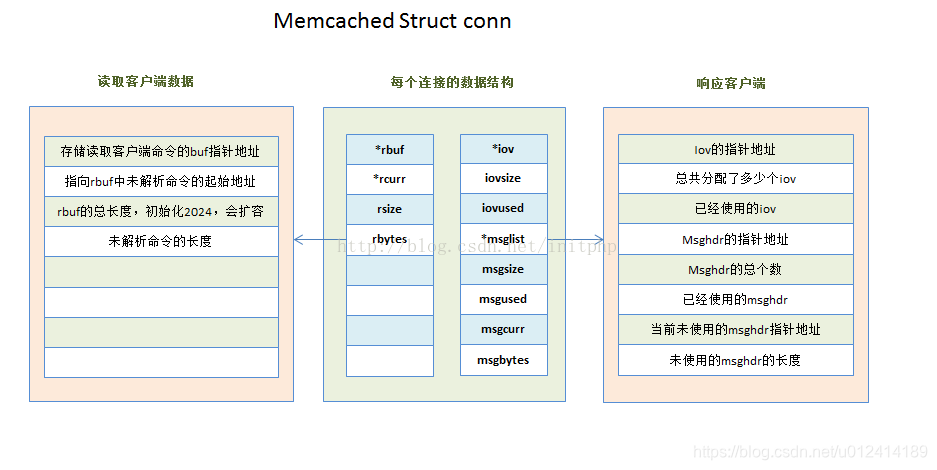
我們繼續看一下conn這個結構。conn結構我們上一期說過,主要是儲存單個客戶端的連線詳情資訊。每一個客戶端連線到Memcached都會有這麼一個數據結構。
1. typedef struct conn conn;
2. 我們可以看一下conn_new這個方法,這個方法應該在第一章節的時候講到過。這邊主要看一下iov和msglist兩個引數初始化的過程。
1. conn *conn_new(const int sfd, enum conn_states init_state,
2. const int event_flags, const int read_buffer_size,
3. enum network_transport transport, struct event_base *base) {
4. //...
5. c->rbuf = c->wbuf = 0;
6. c->ilist = 0;
7. c->suffixlist = 0;
8. c->iov = 0;
9. c->msglist = 0;
10. c->hdrbuf = 0;
11.
12. c->rsize = read_buffer_size;
13. c->wsize = DATA_BUFFER_SIZE;
14. c->isize = ITEM_LIST_INITIAL;
15. c->suffixsize = SUFFIX_LIST_INITIAL;
16. c->iovsize = IOV_LIST_INITIAL; //初始化400
17. c->msgsize = MSG_LIST_INITIAL; //初始化10
18. c->hdrsize = 0;
19.
20. c->rbuf = (char *) malloc((size_t) c->rsize);
21. c->wbuf = (char *) malloc((size_t) c->wsize);
22. c->ilist = (item **) malloc(sizeof(item *) * c->isize);
23. c->suffixlist = (char **) malloc(sizeof(char *) * c->suffixsize);
24. c->iov = (struct iovec *) malloc(sizeof(struct iovec) * c->iovsize); //初始化iov
25. c->msglist = (struct msghdr *) malloc(
26. sizeof(struct msghdr) * c->msgsize); //初始化msglist
27. //...
28. }
資料結構關係圖(iov和msglist之間的關係):
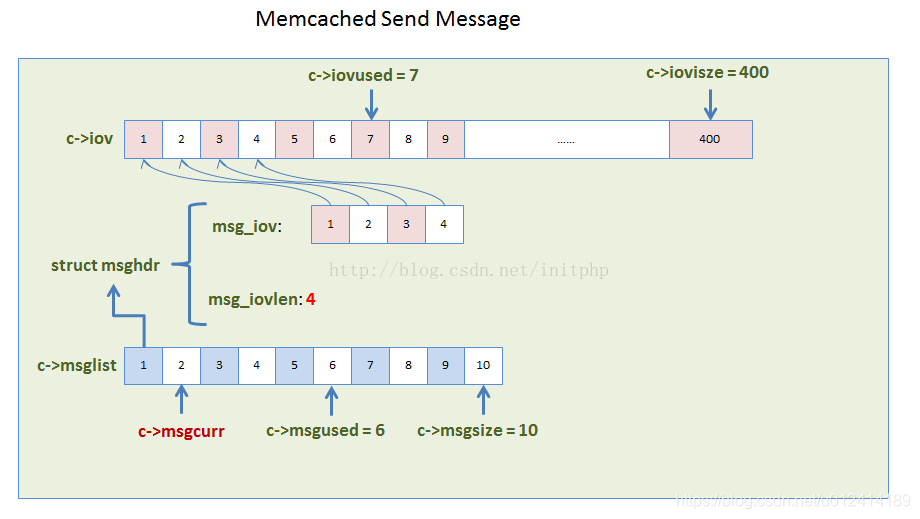
從圖上看,memcached每次傳送給客戶端都是一個msglist中的msghdr元素,這個元素中包含了不同緩衝區的資料,例如c->iov中的資料1 2 3 4,注意這裡1 2 3 4不是連續的資料,指向各個資料所在位置的指標。由於一個命令可以得到多個返回資料,所以一個命令可能攜帶有多個iov,所有一個命令的全部返回結果可能包含多個msghdr。
memcached傳送客戶端的訊息響應的流程如下:
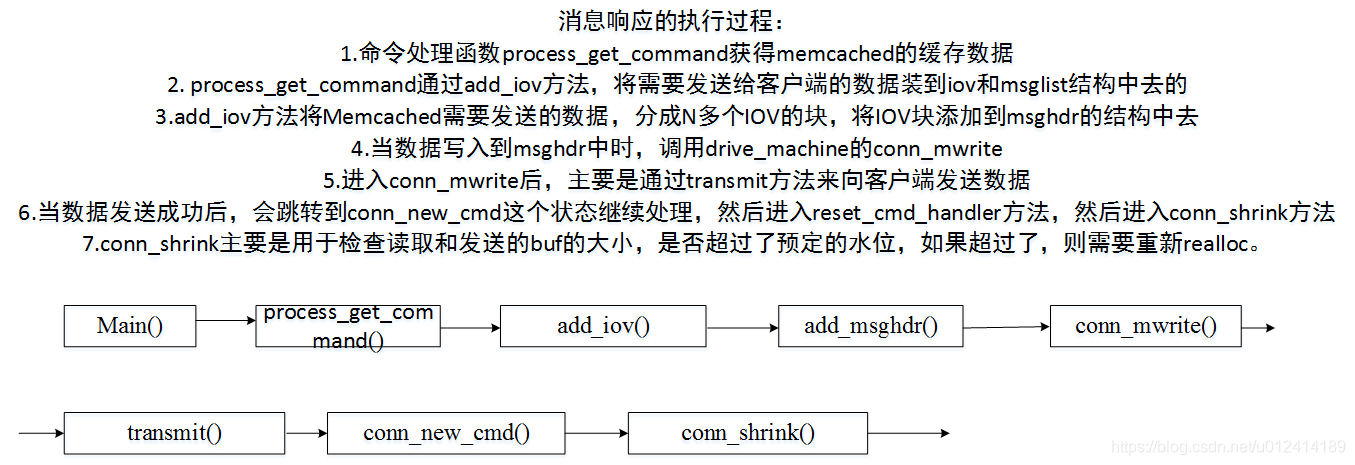
思考與分析:
這裡我們可以學習到的是,memcached利用的多緩衝技術,其實發送緩衝區的資料很簡單,但是對於這種多資料的存取,高併發的存取,使用傳統的send不停的呼叫,或者是記憶體的拷貝顯然是會影響效率,memcached採用的這種技術很值得學習。