
Hadoop單機和偽分佈環境搭建
Hadoop環境搭建與運維
Hadoop概述:
Hadoop是一個由Apache基金會所開發的分散式系統基礎架構。
使用者可以在不瞭解分散式底層細節的情況下,開發分散式程式。充分利用叢集的威力進行高速運算和儲存。
Hadoop實現了一個分散式檔案系統(Hadoop Distributed File System),簡稱HDFS。HDFS有高容錯性的特點,並且設計用來部署在低廉的(low-cost)硬體上;而且它提供高吞吐量(high throughput)來訪問應用程式的資料,適合那些有著超大資料集(large data set)的應用程式。HDFS放寬了(relax)POSIX的要求,可以以流的形式訪問(streaming access)檔案系統中的資料。
Hadoop的框架最核心的設計就是:HDFS和MapReduce。HDFS為海量的資料提供了儲存,則MapReduce為海量的資料提供了計算。
Hadoop單機模式和偽分散式:
1.單機模式
1.安裝ssh
sudo apt-get install openssh-server
安裝後可以使用如下命令登入本機
ssh localhost --會出現Are you sure want to continue contecting(yes/no)?
輸入yes即可
2.對於ssh的理解
ssh分為客戶端和服務端
一臺計算機的時候輸入的每條命令都是直接交給本機去處理
當兩臺計算機的時候:一臺為客戶端,一臺為服務端,假設A為客服端,B為服務端,B的IP地址假設為17.40.61.01,當在A的計算機上執行ssh 17.40.61.01時,就實現了ssh方式登入到B的linux系統執行----A計算機操作的是
B計算機的linux作業系統
3.進行ssh無密碼登入
cd ~/.ssh/
ssh-keygen -t rsa –p ‘’ //提示按ENTER就行
cat ./id_rsa.pub>>./authorized_key //加入授權
4.安裝java環境
下載jdk安裝包到指定資料夾
再使用sudo tar命令前先檢視安裝包的許可權如果是無法執行對其檔案許可權進行修改
chown user:user jdk_____________-
配置環境變數
vim ~/.bashrc
在~/.bashrc中新增export JAVA_HOME=/opt/jdk1.8.0_171---------jdk所在路徑
export PATH=$PATH:$JAVA_HOME/bin
退出 ~/.bashrc檔案介面
使環境變數生效 source ~/.bashrc
檢驗是否設定成功 java –version
5.安裝hadoop
進行許可權修改 chown user:user –R /xx/Hadoop/*
sudo tar -zxf hadoop------ -C /usr/local
到hadoop中配置JAVA_HOME,檔案位於hadoop2.7.6/etc/hadoop/hadoop.env.sh,將JAVA_HOME配置成JDK所在路徑.
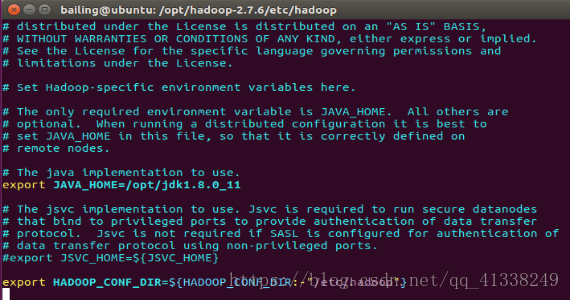
6.單機模式配置
mkdir input
cp ./etc/hadoop/*xml ./input //將配置檔案複製到input目錄下
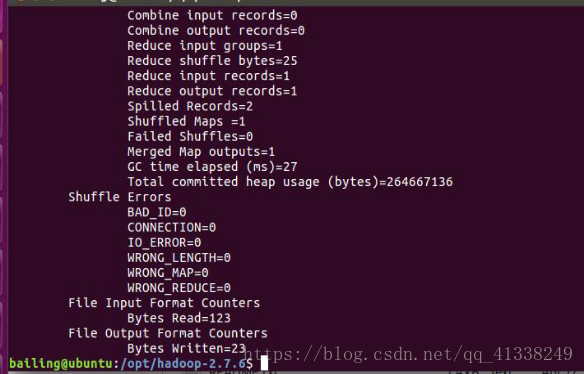
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples------- jar grep ./input ./output 'dfs[a-z.]+'
cat ./output/* //檢視執行結果

偽分散式模式
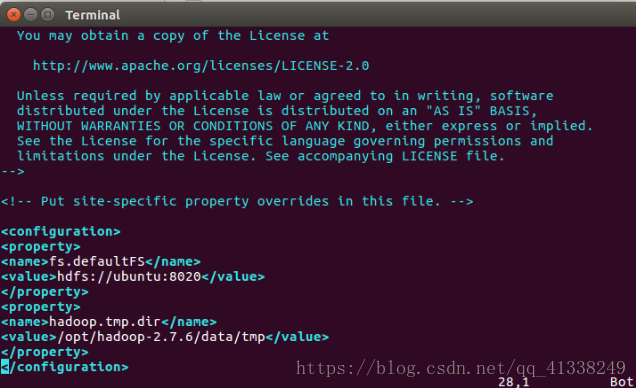
修改配置檔案core-site.xml和hdfs-site.xml檔案
vim core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-2.7.6/data/tmp</value>
</property>
</configuration>
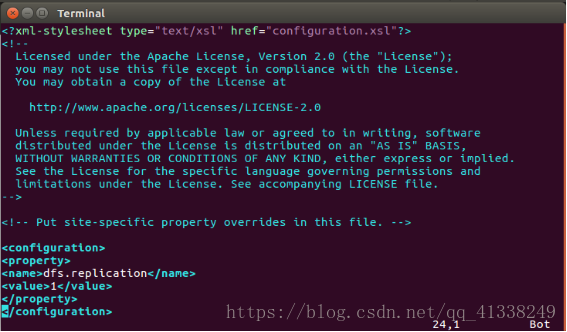
vim hdfs_site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name> dfs.namenode.name.dir</name>
<value>/opt/hadoop-2.7.6/data/tmp/name</value>
</property>
<property>
<name>dfs.datanode.name.dir</name>
<value>/opt/hadoop-2.7.6/data/tmp/data</value>
</property>
</configuration>
vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name </name>
<value>yarn</value>
</property>
</configuration>
vim yanr-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services </name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
7..執行節點格式化和執行hadoop
返回到hadoop安裝目錄 cd/usr/local/hadoop-2.7.6
格式化 ./bin/hdfs namenode –format
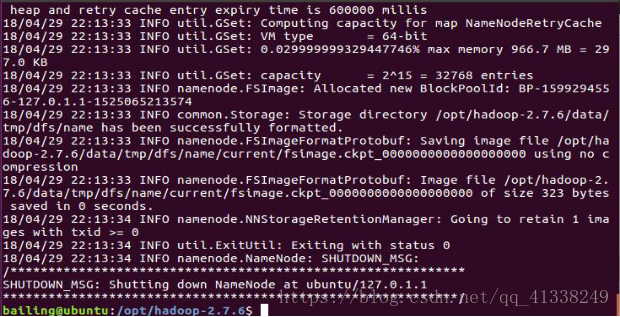
如果出現Exiting with status 1,則為錯誤 (通常為namenode和datanode資訊存放檔案 沒有許可權)
啟動:
Start-hdfs.sh
Start-yarn.sh
或者
Start-all.sh
啟動成功後jps命令則會列出程序
檢視web端介面
Http://127.0.0.1:50070
Hadoop叢集模式搭建
完成偽單機模式的搭建,並從這基礎上進行修改
修改core-site.xml檔案如下:
<name>fs.defaultFS</name>
<value>hdfs://Master:9000</value>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-2.7.6/data/tmp </value>
修改hdfs-site.xml如下:
<name>dfs.namenode.secondary.http-address</name>
<value>Master:50090</value>
<name>dfs.namenode.name.dir</name>
<value>/opt/hadoop-2.7.6/data/tmp /name</value>
<name>dfs.datanode.name.dir</name>
<value>/opt/hadoop-2.7.6/data/tmp/data</value>
<name>dfs.replication</name>
<value>1</value>
修改mapred-site.xml如下
<name>mapreduce.framework.name</name>
<value>yarn</value>
<name>mapreduce.jobhistory.address</name>
<value>Master:10020</value>
<name>mapreduce.jobhistory.webapp.address</name>
<value>Master:19888</value>
修改yarn-site.xml如下
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<name>yarn.resourcemanager.hostname</value>
<value>Master</value>
使用scp命令將主機配置完的hadoop傳送到個從機(注意路徑)
Scp ./hadoop.Master.hadoop.tar.gz Salve1:/home/hadoop/
Hadoop HA模式的介紹
1.概述
在hadoop2.x版本之前,namenode只存在一個,存在單點問題(雖然hadoop1.x版本有secondarynamenode,checkpointnode,buckcupnode這些,但是單點問題無法解決),在hadoop2.x版本後引入了HA機制。hadoop2.x的HA機制官方介紹了有2種方式,一種是NFS(Network File System)方式,另外一種是QJM(Quorum Journal Manager)方式。
2 基本原理
hadoop2.x的HA 機制有兩個namenode,一個是active namenode,狀態是active;另外一個是standby namenode,狀態是standby。兩者的狀態互相血環,但不會同時兩個都是active狀態,最多隻有1個是active狀態。只有active namenode提供對外的服務,standby namenode是不對外服務的。active namenode和standby namenode之間通過NFS或者JN來同步資料完成日常作業。
檢視叢集執行狀態(命令,Ui)
命令:hadoop dfsadmin -report
Ui: Master ip地址:500030
Hadoop命令的基本使用
FS Shell
呼叫檔案系統(FS)Shell命令應使用 bin/hadoop fs <args>的形式。 所有的的FS shell命令使用URI路徑作為引數。URI格式是scheme://authority/path。對HDFS檔案系統,scheme是hdfs,對本地檔案系統,scheme是file。其中scheme和authority引數都是可選的,如果未加指定,就會使用配置中指定的預設scheme。一個HDFS檔案或目錄比如/parent/child可以表示成hdfs://namenode:namenodeport/parent/child,或者更簡單的/parent/child(假設你配置檔案中的預設值是namenode:namenodeport)。大多數FS Shell命令的行為和對應的Unix Shell命令類似,不同之處會在下面介紹各命令使用詳情時指出。出錯資訊會輸出到stderr,其他資訊輸出到stdout。
使用方法:hadoop fs -cat URI [URI …]
將路徑指定檔案的內容輸出到stdout。
示例:
· hadoop fs -cat hdfs://host1:port1/file1 hdfs://host2:port2/file2
· hadoop fs -cat file:///file3 /user/hadoop/file4
返回值:
成功返回0,失敗返回-1。
使用方法:hadoop fs -chgrp [-R] GROUP URI [URI …] Change group association of files. With -R, make the change recursively through the directory structure. The user must be the owner of files, or else a super-user. Additional information is in the Permissions User Guide. -->
改變檔案所屬的組。使用-R將使改變在目錄結構下遞迴進行。命令的使用者必須是檔案的所有者或者超級使用者。更多的資訊請參見HDFS許可權使用者指南。
使用方法:hadoop fs -chmod [-R] <MODE[,MODE]... | OCTALMODE> URI [URI …]
改變檔案的許可權。使用-R將使改變在目錄結構下遞迴進行。命令的使用者必須是檔案的所有者或者超級使用者。更多的資訊請參見HDFS許可權使用者指南。
使用方法:hadoop fs -chown [-R] [OWNER][:[GROUP]] URI [URI ]
改變檔案的擁有者。使用-R將使改變在目錄結構下遞迴進行。命令的使用者必須是超級使用者。更多的資訊請參見HDFS許可權使用者指南。
使用方法:hadoop fs -copyFromLocal <localsrc> URI
除了限定源路徑是一個本地檔案外,和put命令相似。
使用方法:hadoop fs -copyToLocal [-ignorecrc] [-crc] URI <localdst>
除了限定目標路徑是一個本地檔案外,和get命令類似。
使用方法:hadoop fs -cp URI [URI …] <dest>
將檔案從源路徑複製到目標路徑。這個命令允許有多個源路徑,此時目標路徑必須是一個目錄。
示例:
· hadoop fs -cp /user/hadoop/file1 /user/hadoop/file2
· hadoop fs -cp /user/hadoop/file1 /user/hadoop/file2 /user/hadoop/dir
返回值:
成功返回0,失敗返回-1。
使用方法:hadoop fs -du URI [URI …]
顯示目錄中所有檔案的大小,或者當只指定一個檔案時,顯示此檔案的大小。
示例:
hadoop fs -du /user/hadoop/dir1 /user/hadoop/file1 hdfs://host:port/user/hadoop/dir1
返回值:
成功返回0,失敗返回-1。
使用方法:hadoop fs -dus <args>
顯示檔案的大小。
使用方法:hadoop fs -expunge
清空回收站。請參考HDFS設計文件以獲取更多關於回收站特性的資訊。
使用方法:hadoop fs -get [-ignorecrc] [-crc] <src> <localdst>
複製檔案到本地檔案系統。可用-ignorecrc選項複製CRC校驗失敗的檔案。使用-crc選項複製檔案以及CRC資訊。
示例:
· hadoop fs -get /user/hadoop/file localfile
· hadoop fs -get hdfs://host:port/user/hadoop/file localfile
返回值:
成功返回0,失敗返回-1。
使用方法:hadoop fs -getmerge <src> <localdst> [addnl]
接受一個源目錄和一個目標檔案作為輸入,並且將源目錄中所有的檔案連線成本地目標檔案。addnl是可選的,用於指定在每個檔案結尾新增一個換行符。
使用方法:hadoop fs -ls <args>
如果是檔案,則按照如下格式返回檔案資訊:
檔名 <副本數> 檔案大小 修改日期 修改時間 許可權 使用者ID 組ID
如果是目錄,則返回它直接子檔案的一個列表,就像在Unix中一樣。目錄返回列表的資訊如下:
目錄名 <dir> 修改日期 修改時間 許可權 使用者ID 組ID
示例:
hadoop fs -ls /user/hadoop/file1 /user/hadoop/file2 hdfs://host:port/user/hadoop/dir1 /nonexistentfile
返回值:
成功返回0,失敗返回-1。
使用方法:hadoop fs -lsr <args>
ls命令的遞迴版本。類似於Unix中的ls -R。
使用方法:hadoop fs -mkdir <paths>
接受路徑指定的uri作為引數,建立這些目錄。其行為類似於Unix的mkdir -p,它會建立路徑中的各級父目錄。
示例:
· hadoop fs -mkdir /user/hadoop/dir1 /user/hadoop/dir2
· hadoop fs -mkdir hdfs://host1:port1/user/hadoop/dir hdfs://host2:port2/user/hadoop/dir
返回值:
成功返回0,失敗返回-1。
使用方法:dfs -moveFromLocal <src> <dst>
輸出一個”not implemented“資訊。
使用方法:hadoop fs -mv URI [URI …] <dest>
將檔案從源路徑移動到目標路徑。這個命令允許有多個源路徑,此時目標路徑必須是一個目錄。不允許在不同的檔案系統間移動檔案。
示例:
· hadoop fs -mv /user/hadoop/file1 /user/hadoop/file2
· hadoop fs -mv hdfs://host:port/file1 hdfs://host:port/file2 hdfs://host:port/file3 hdfs://host:port/dir1
返回值:
成功返回0,失敗返回-1。
使用方法:hadoop fs -put <localsrc> ... <dst>
從本地檔案系統中複製單個或多個源路徑到目標檔案系統。也支援從標準輸入中讀取輸入寫入目標檔案系統。
· hadoop fs -put localfile /user/hadoop/hadoopfile
· hadoop fs -put localfile1 localfile2 /user/hadoop/hadoopdir
· hadoop fs -put localfile hdfs://host:port/hadoop/hadoopfile
· hadoop fs -put - hdfs://host:port/hadoop/hadoopfile
從標準輸入中讀取輸入。
返回值:
成功返回0,失敗返回-1。
使用方法:hadoop fs -rm URI [URI …]
刪除指定的檔案。只刪除非空目錄和檔案。請參考rmr命令瞭解遞迴刪除。
示例:
· hadoop fs -rm hdfs://host:port/file /user/hadoop/emptydir
返回值:
成功返回0,失敗返回-1。
使用方法:hadoop fs -rmr URI [URI …]
delete的遞迴版本。
示例:
· hadoop fs -rmr /user/hadoop/dir
· hadoop fs -rmr hdfs://host:port/user/hadoop/dir
返回值:
成功返回0,失敗返回-1。
使用方法:hadoop fs -setrep [-R] <path>
改變一個檔案的副本系數。-R選項用於遞迴改變目錄下所有檔案的副本系數。
示例:
· hadoop fs -setrep -w 3 -R /user/hadoop/dir1
返回值:
成功返回0,失敗返回-1。
使用方法:hadoop fs -stat URI [URI …]
返回指定路徑的統計資訊。
示例:
· hadoop fs -stat path
返回值:
成功返回0,失敗返回-1。
使用方法:hadoop fs -tail [-f] URI
將檔案尾部1K位元組的內容輸出到stdout。支援-f選項,行為和Unix中一致。
示例:
· hadoop fs -tail pathname
返回值:
成功返回0,失敗返回-1。
使用方法:hadoop fs -test -[ezd] URI
選項:
-e 檢查檔案是否存在。如果存在則返回0。
-z 檢查檔案是否是0位元組。如果是則返回0。
-d 如果路徑是個目錄,則返回1,否則返回0。
示例:
· hadoop fs -test -e filename
使用方法:hadoop fs -text <src>
將原始檔輸出為文字格式。允許的格式是zip和TextRecordInputStream。
使用方法:hadoop fs -touchz URI [URI …]
建立一個0位元組的空檔案。
示例:
· hadoop -touchz pathname
返回值:
成功返回0,失敗返回-1。
Wordcount示例程式的執行和日誌檢視
1.Wordcount示例程式
執行 wordcount 程式
已經啟動了必需的各項程序:namenode、datanode、resourcemanager、nodemanager、JobHistoryServer 等
確保當前 hdfs 不處於安全模式
hdfs dfsadmin -safemode leave
1
確保已經在 HDFS 中建立了相關目錄 /data/wordcount 、/output ,以下 /tmp 及其以下目錄是啟動 JobHistoryServer 後系統自動生成的
上傳了測試資料集 slaves
hadoop fs -put /usr/local/cluster/hadoop/etc/hadoop/slaves /data/wordcount/
進入程式所在目錄,並執行程式
cd /usr/local/cluster/hadoop/share/hadoop/mapreduce
hadoop jar hadoop-mapreduce-examples-2.5.0-cdh5.3.2.jar wordcount /data/wordcount /output/wordcount
15/12/22 00:30:36 INFO input.FileInputFormat: Total input paths to process : 115/12/22 00:30:37 INFO mapreduce.JobSubmitter: number of splits:115/12/22 00:30:37 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1450714294593_000115/12/22 00:30:37 INFO impl.YarnClientImpl: Submitted application application_1450714294593_000115/12/22 00:30:37 INFO mapreduce.Job: The url to track the job: http://master5:8088/proxy/application_1450714294593_0001/15/12/22 00:30:37 INFO mapreduce.Job: Running job: job_1450714294593_000115/12/22 00:30:43 INFO mapreduce.Job: Job job_1450714294593_0001 running in uber mode : false15/12/22 00:30:43 INFO mapreduce.Job: map 0% reduce 0%15/12/22 00:30:49 INFO mapreduce.Job: map 100% reduce 0%15/12/22 00:31:04 INFO mapreduce.Job: map 100% reduce 100%15/12/22 00:31:05 INFO mapreduce.Job: Job job_1450714294593_0001 completed successfully15/12/22 00:31:05 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=48
FILE: Number of bytes written=212385
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=125
HDFS: Number of bytes written=30
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=2347
Total time spent by all reduces in occupied slots (ms)=13060
Total time spent by all map tasks (ms)=2347
Total time spent by all reduce tasks (ms)=13060
Total vcore-seconds taken by all map tasks=2347
Total vcore-seconds taken by all reduce tasks=13060
Total megabyte-seconds taken by all map tasks=2403328
Total megabyte-seconds taken by all reduce tasks=13373440
Map-Reduce Framework
Map input records=3
Map output records=3
Map output bytes=36
Map output materialized bytes=48
Input split bytes=101
Combine input records=3
Combine output records=3
Reduce input groups=3
Reduce shuffle bytes=48
Reduce input records=3
Reduce output records=3
Spilled Records=6
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=98
CPU time spent (ms)=1250
Physical memory (bytes) snapshot=440475648
Virtual memory (bytes) snapshot=4203302912
Total committed heap usage (bytes)=342360064
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=24
File Output Format Counters
Bytes Written=30
2. 日誌檢視
通過web介面檢視hadoop叢集執行日誌的地址:
http://hostname:8088/logs/