
轉:MongoDB · 引擎特性 · journal 與 oplog,究竟誰先寫入?
轉:MongoDB · 引擎特性 · journal 與 oplog,究竟誰先寫入?
資料庫核心月報
連結:http://mysql.taobao.org/monthly/2018/05/07/
MongoDB journal 與 oplog,誰先寫入?最近經常被人問到,本文主要科普一下 MongoDB 裡 oplog 以及 journal 這兩個概念。
journal
journal 是 MongoDB 儲存引擎層的概念,目前 MongoDB主要支援 mmapv1、wiredtiger、mongorocks 等儲存引擎,都支援配置journal。
MongoDB 所有的資料寫入、讀取最終都是調儲存引擎層的介面來儲存、讀取資料,journal 是儲存引擎儲存資料時的一種輔助機制。
以wiredtiger 為例,如果不配置 journal,寫入 wiredtiger 的資料,並不會立即持久化儲存;而是每分鐘會做一次全量的checkpoint
(storage.syncPeriodSecs配置項,預設為1分鐘),將所有的資料持久化。如果中間出現宕機,那麼資料只能恢復到最近的一次checkpoint,這樣最多可能丟掉1分鐘的資料。
所以建議「一定要開啟journal」,開啟 journal 後,每次寫入會記錄一條操作日誌(通過journal可以重新構造出寫入的資料)。這樣即
使出現宕機,啟動時 Wiredtiger 會先將資料恢復到最近的一次checkpoint的點,然後重放後續的 journal 操作日誌來恢復資料。
MongoDB 裡的 journal 行為 主要由2個引數控制,storage.journal.enabled 決定是否開啟journal,storage.journal.commitInternalMs
決定 journal 刷盤的間隔,預設為100ms,使用者也可以通過寫入時指定 writeConcern 為 {j: ture} 來每次寫入時都確保 journal 刷盤。
oplog
oplog 是 MongoDB 主從複製層面的一個概念,通過 oplog 來實現複製集節點間資料同步,客戶端將資料寫入到 Primary,Primary 寫入數
據後會記錄一條 oplog,Secondary 從 Primary(或其他 Secondary )拉取 oplog 並重放,來確保複製集裡每個節點儲存相同的資料。
oplog 在 MongoDB 裡是一個普通的 capped collection,對於儲存引擎來說,oplog只是一部分普通的資料而已。
MongoDB 的一次寫入
MongoDB 複製集裡寫入一個文件時,需要修改如下資料
- 將文件資料寫入對應的集合
- 更新集合的所有索引資訊
- 寫入一條oplog用於同步
上面3個修改操作,需要確保要麼都成功,要麼都失敗,不能出現部分成功的情況,否則
- 如果資料寫入成功,但索引寫入失敗,那麼會出現某個資料,通過全表掃描能讀取到,但通過索引就無法讀取
- 如果資料、索引都寫入成功,但 oplog 寫入不成功,那麼寫入操作就不能正常的同步到備節點,出現主備資料不一致的情況
MongoDB 在寫入資料時,會將上述3個操作放到一個 wiredtiger 的事務裡,確保「原子性」。
beginTransaction();
writeDataToColleciton();
writeCollectionIndex();
writeOplog();
commitTransaction();
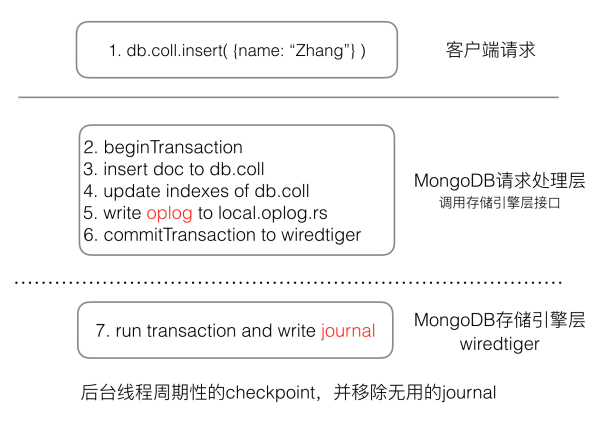
wiredtiger 提交事務時,會將所有修改操作應用,並將上述3個操作寫入到一條 journal 操作日誌裡;後臺會週期性的checkpoint,將修改持久化,並移除無用的journal。
從資料佈局看,oplog 與 journal 的關係

誰先寫入??
- oplog 與 journal 是 MongoDB 裡不同層次的概念,放在一起比先後本身是不合理的。
- oplog 在 MongoDB 裡是一個普通的集合,所以 oplog 的寫入與普通集合的寫入並無區別。
- 一次寫入,會對應資料、索引,oplog的修改,而這3個修改,會對應一條journal操作日誌。