
MySQL資料庫(十一)__2018.11.15
阿新 • • 發佈:2018-11-22
我們已經看到了,where條件可以篩選我們的記錄,符合要求的記錄,接下來還可以加上另外一個group by它呢是對我們的記錄做一個分組。
我們可以看到,我們可以按照欄位分組也可以按照欄位的位置進行分組。
GROUP BY分組:它是把記錄值相同的放到一個組裡,最終的查詢出的結果只會顯示組中的一條記錄。
#測試分組
#按照性別分組
SELECT id,username,age,sex FROM user1
GROUP BY sex;#按照地址分組 #會把值相同的放到一個組裡 SELECT username,age,sex,addr FROM user1 GROUP BY addr;
想看到分組中詳細資訊,group可以套著一個函式使用:配合group_concat()檢視組中某個欄位的詳細資訊。
#測試分組
#按照性別分組,查詢組中的使用者名稱有哪些
SELECT GROUP_CONCAT(username),age,sex,addr FROM user1
GROUP BY sex;
#因為要檢視username的詳細資訊,所以要把username放到group_concat()函式中顯示分組配合聚合函式使用。
常用的聚合函式:
count():是統計資料表中記錄總數
SUM():它是求和的
MAX():求最大值
MIN():求最小值
AVG():求平均值
一半呢都是配合上我們的聚合函式一起使用的。
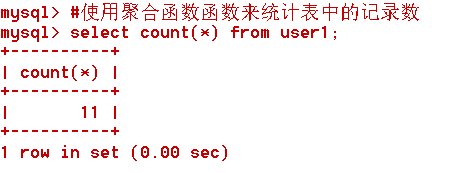
#測試聚合函式統計資料表中的記錄數
#並對它起一個別名
SELECT COUNT(*)AS total_users FROM user1;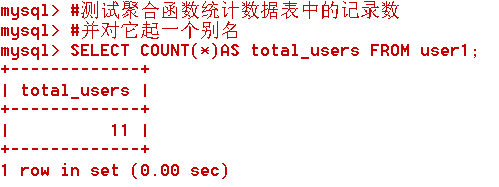
之後我們就可以取出這個欄位對應的值了;
#測試聚合函式統計資料表中的記錄數
SELECT COUNT(id) FROM user1;
但是注意id和*是有區別的,請看下面
#測試聚合函式統計資料表中的記錄數
SELECT COUNT(userDesc) FROM user1;

如果直接寫欄位的話,它在統計的時候如果這個欄位為空的話它不記錄進來。這就是它和*的區別。
欄位中的值為NULL時,不統計進來。寫*的話會統計進來。
#按照sex分組,得到使用者名稱詳情,並且分別顯示組中總人數
SELECT sex,GROUP_CONCAT(username),COUNT(*)AS totalusers FROM user1
GROUP BY sex;
使用到了我們的聚合函式
#按照addr分組,得到使用者名稱的詳情,總人數,得到組中年齡的總和,年齡的最大值、最小值、平均值和
SELECT addr,GROUP_CONCAT(username) AS userDetail,
COUNT(*)AS totalUsers,
SUM(age)AS sum_age,
MAX(age)AS max_age,
MIN(age)AS min_age,
AVG(age)AS avg_age
FROM user1
GROUP BY addr;
#按照sex分組,統計組中總人數、使用者名稱詳情、得到薪水綜合、薪水最大值、最小值、平均值
SELECT sex,
#當然了,你寫到一行也是可以的,但是不建議你寫到一行,看起來不方便
GROUP_CONCAT(username)AS userDetail,
COUNT(*)AS totalUsers,
SUM(salary)AS sum_salary,
MAX(salary)AS max_salary,
MIN(salary)AS min_salary,
AVG(salary)AS avg_salary
FROM user1
GROUP BY sex;
配合with rollup關鍵字使用:它會在記錄末尾新增一行記錄,是上面所有記錄的總和。
SELECT GROUP_CONCAT(username)AS userDetail,
COUNT(*)AS totalUsers
FROM user1
GROUP BY sex
WITH ROLLUP;
前面是按照欄位名稱進行分組,也可以按照欄位位置進行分組。
#按欄位位置進行分組
GROUP_CONCAT(username)AS userDetail,
COUNT(*)AS totalUsers,
SUM(salary)AS sum_salary,
MAX(salary)AS max_salary,
MIN(salary)AS min_salary,
AVG(salary)AS avg_salary
FROM user1
GROUP BY 1;
這就是篩選後得到的結果集。
where相當於對結果的第一次篩選,然後再用分組進行二次處理。
#查詢age>=30的使用者並且按照sex分組
SELECT sex,GROUP_CONCAT(username)AS userDetail,
COUNT(*)AS totalUsers
FROM user1
WHERE age>=30
GROUP BY sex;
相當於對這個結果再進行分組。
having字句對分組結果進行二次篩選
#按照addr分組,統計總人數
SELECT addr,
GROUP_CONCAT(username)AS userDetail,
COUNT(*) AS totalUsers
FROM user1
GROUP BY addr
HAVING COUNT(*)>=3;
#通過having字句對於分組結果進行二次篩選,要求組中總人數>=3
#按照addr分組,統計總人數
SELECT addr,
GROUP_CONCAT(username)AS userDetail,
COUNT(*) AS totalUsers
FROM user1
GROUP BY addr
HAVING totalUsers>=3;
#這也體現了別名的好處

#按照addr分組
SELECT addr,
GROUP_CONCAT(username) AS usersDetail,
COUNT(*)AS totalUsers,
SUM(salary)AS sum_salary,
MAX(salary)AS max_salary,
MIN(salary)AS min_salary,
AVG(salary)AS avg_salary
FROM user1
GROUP BY addr;
加上二次刪選的條件,要求平均薪水大於等於40000
#按照addr分組
SELECT addr,
GROUP_CONCAT(username) AS usersDetail,
COUNT(*)AS totalUsers,
SUM(salary)AS sum_salary,
MAX(salary)AS max_salary,
MIN(salary)AS min_salary,
AVG(salary)AS avg_salary
FROM user1
GROUP BY addr
HAVING avg_salary>=40000;
#這就是我們having字句的使用
